
Java面试常考之ConcurrentHashMap多线程扩容机制详解
作者:爱敲代码的小黄
几乎所有的后端技术面试官都要在 ConcurrentHashMap 技术的使用和原理方面对小伙伴们进行刁难,本文主要来和大家聊聊ConcurrentHashMap多线程的扩容机制,希望对大家有所帮助
一、引言
ConcurrentHashMap 技术在互联网技术使用如此广泛,几乎所有的后端技术面试官都要在 ConcurrentHashMap 技术的使用和原理方面对小伙伴们进行 360° 的刁难。
作为一个在互联网公司面一次拿一次 Offer 的面霸,打败了无数竞争对手,每次都只能看到无数落寞的身影失望的离开,略感愧疚(请允许我使用一下夸张的修辞手法)。
本篇文章大约读取时间十分钟,带你彻底掌握 ConcurrentHashMap 的 魔鬼式的多线程扩容 逻辑,目录如下:

二、扩容流程
我们上一篇文章讲了关于 ConcurrentHashMap 的存储流程:聊聊ConcurrentHashMap的存储流程,熟悉了其数据是如何的放到数组、链表、红黑树中
今天这篇文章,我们重点讲一下 ConcurrentHashMap 魔鬼式的多线程扩容逻辑
系好安全带,我们发车了!
1、treeifyBin方法触发扩容
// 在链表长度大于等于8时,尝试将链表转为红黑树
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
// 数组不能为空
if (tab != null) {
// 数组的长度n,是否小于64
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
// 如果数组长度小于64,不能将链表转为红黑树,先尝试扩容操作
// 这里的扩容传入的数据是当前数据的2倍
tryPresize(n << 1);
// 省略部分代码……
}
}2、tryPreSize方法-针对putAll的初始化操作
private final void tryPresize(int size) {
// 如果当前传过来的size大于最大值MAXIMUM_CAPACITY >>> 1,则取 MAXIMUM_CAPACITY
// 反之取 tableSizeFor(size + (size >>> 1) + 1)= size的1.5倍 + 1
// tableSizeFor:这个方法我们之前也讲过,找size的最近二次幂
// 这个地方的c
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY : tableSizeFor(size + (size >>> 1) + 1);
int sc;
// 当前的sizeCtl大于等于0,证明不属于异常状态
// static final int MOVED = -1; // 代表当前hash位置的数据正在扩容!
// static final int TREEBIN = -2; // 代表当前hash位置下挂载的是一个红黑树
// static final int RESERVED = -3; // 预留当前索引位置……
while ((sc = sizeCtl) >= 0) {
Node<K,V>[] tab = table; int n;
// 如果当前的数组为空,走初始化的逻辑
// 有人可能会好奇,这里怎么会为空呢?
// 大家可以去看下putAll的源码(放在下面),源码里面第一句调用的就是tryPresize的方法
if (tab == null || (n = tab.length) == 0) {
// 进来执行初始化
// sc是初始化长度,初始化长度如果比计算出来的c要大的话,直接使用sc,如果没有sc大,
// 说明sc无法容纳下putAll中传入的map,使用更大的数组长度
n = (sc > c) ? sc : c;
// 还是老配方,CAS将SIZECTL尝试从sc变成-1
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
// Step1:判断引用
// Step2:创建数组
// Step3:修改sizeCtl数值
if (table == tab) {
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
}
}
// 如果计算出来的长度c如果小于等于sc,直接退出循环结束方法
// 数组长度大于等于最大长度了,直接退出循环结束方法
// 不需要扩容
else if (c <= sc || n >= MAXIMUM_CAPACITY)
break;
// 省略部分代码
}
}
// putAll方法
public void putAll(Map<? extends K, ? extends V> m) {
// 直接走扩容的逻辑
tryPresize(m.size());
for (Map.Entry<? extends K, ? extends V> e : m.entrySet())
putVal(e.getKey(), e.getValue(), false);
}3、tryPreSize方法-计算扩容戳
private final void tryPresize(int size) {
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :
tableSizeFor(size + (size >>> 1) + 1);
int sc;
while ((sc = sizeCtl) >= 0) {
Node<K,V>[] tab = table;
// 当前数组的长度
int n;
// 判断引用是否一致
if (tab == table) {
// 计算扩容标识戳,根据当前数组的长度计算一个16位的扩容戳
// 1、保证后面的SIZECTL赋值是负数
// 2、记录当前从什么长度开始扩容
int rs = resizeStamp(n);
// 这里存在bug
// 由于我们上面(sc = sizeCtl) >= 0的判断,sc只能大于0
// 这里永远大于等于0
if (sc < 0) {
// 协助扩容的代码
}
// 代表当前没有线程进行扩容,我是第一个扩容的
else if (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
}
}
}
// 计算扩容标识戳
static final int resizeStamp(int n) {
return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}4、tryPreSize方法-对sizeCtl的修改
private final void tryPresize(int size) {
// sc默认为sizeCtl
while ((sc = sizeCtl) >= 0) {
else if (tab == table) {
// rs:扩容戳 00000000 00000000 10000000 00011010
int rs = resizeStamp(n);
if (sc < 0) {
// 说明有线程正在扩容,过来帮助扩容
// 我们之前第一个线程扩容的时候,将sizeCtl设置成:10000000 00011010 00000000 00000010
// 所以:sc = 10000000 00011010 00000000 00000010
Node<K,V>[] nt;
// 依然有BUG
// 当前线程扩容时,老数组长度是否和我当前线程扩容时的老数组长度一致
// 00000000 00000000 10000000 00011010
if ((sc >>> RESIZE_STAMP_SHIFT) != rs
// 10000000 00011010 00000000 00000010
// 00000000 00000000 10000000 00011010
// 这两个判断都是有问题的,核心问题就应该先将rs左移16位,再追加当前值。
// 这两个判断是BUG
// 判断当前扩容是否已经即将结束
|| sc == rs + 1 // sc == rs << 16 + 1 BUG
// 判断当前扩容的线程是否达到了最大限度
|| sc == rs + MAX_RESIZERS // sc == rs << 16 + MAX_RESIZERS BUG
// 扩容已经结束了。
|| (nt = nextTable) == null
// 记录迁移的索引位置,从高位往低位迁移,也代表扩容即将结束。
|| transferIndex <= 0)
break;
// 如果线程需要协助扩容,首先就是对sizeCtl进行+1操作,代表当前要进来一个线程协助扩容
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
// 上面的判断没进去的话,nt就代表新数组
transfer(tab, nt);
}
// 是第一个来扩容的线程
// 基于CAS将sizeCtl修改为:10000000 00011010 00000000 00000010
// 将扩容戳左移16位之后,符号位是1,就代码这个值为负数
// 低16位在表示当前正在扩容的线程有多少个:低16位为2,代表当前有一个线程正在扩容
// 为什么低16位值为2时,代表有一个线程正在扩容
// 每一个线程扩容完毕后,会对低16位进行-1操作,当最后一个线程扩容完毕后,减1的结果还是-1,
// 当值为-1时,要对老数组进行一波扫描,查看是否有遗漏的数据没有迁移到新数组
else if (U.compareAndSwapInt(this, SIZECTL, sc,(rs << RESIZE_STAMP_SHIFT) + 2))
// 调用transfer方法,并且将第二个参数设置为null,就代表是第一次来扩容!
transfer(tab, null);
}
}
}5、transfer方法-计算每个线程迁移的长度
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
// 数组长度
int n = tab.length;
// 每个线程一次性迁移多少数据到新数组
int stride;
// 基于CPU的线程数来计算:NCPU = Runtime.getRuntime().availableProcessors()
// MIN_TRANSFER_STRIDE = 16
// NCPU = 4
// 举个例子:N = 1024 - 512 - 256 - 128 / 4 = 32
// 如果算出来每个线程的长度小于16的话,直接使用16
// 如果大于16的话,则使用N
// 如果线程数只有1的话,直接就是原数组长度
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE){
stride = MIN_TRANSFER_STRIDE;
}
}6、 transfer方法-构建新数组并查看标识属性
// 以32位长度数组扩容到64位为例子
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
// 数组长度
int n = tab.length;
// 每个线程一次性迁移多少数据到新数组
int stride;
// 第一个进来扩容的线程需要把新数组构建出来
if (nextTab == null) {
try {
// 将原数组长度左移一位创建新数组
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
// 赋值操作
nextTab = nt;
} catch (Throwable ex) {
sizeCtl = Integer.MAX_VALUE;
return;
}
// 将成员变量的新数组赋值volatile修饰
nextTable = nextTab;
// 迁移数据时用到的标识volatile修饰
transferIndex = n;
}
// 新数组长度
int nextn = nextTab.length;
// 老数组迁移完数据后,做的标识
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
// 迁移数据时,需要用到的标识
boolean advance = true;
boolean finishing = false;
}7、transfer方法-线程领取迁移任务
// 以32位长度数组扩容到64位为例子
// 数组长度
int n = tab.length;
// 每个线程一次性迁移多少数据到新数组
int stride;
// 迁移数据时用到的标识volatile修饰
transferIndex = n;
// 新数组长度
int nextn = nextTab.length;
// 老数组迁移完数据后,做的标识
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
// advance:true,代表当前线程需要接收任务,然后再执行迁移
// 如果为false,代表已经接收完任务
boolean advance = true;
// 标识迁移是否结束
boolean finishing = false;
// 开始循环
for (int i = 0, bound = 0;;) {
Node<K,V> f;
int fh;
while (advance) {
int nextIndex;
int nextBound;
// 第一次:这里肯定进不去
// 主要判断当前任务是否执行完毕
if (--i >= bound || finishing)
advance = false;
// 第一次:这里肯定也进不去
// 判断transferIndex是否小于等于0,代表没有任务可领取,结束了。
// 在线程领取任务会,会对transferIndex进行修改,修改为transferIndex - stride
// 在任务都领取完之后,transferIndex肯定是小于等于0的,代表没有迁移数据的任务可以领取
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
// nextIndex=32
// stride=16
// nextIndex > stride ? nextIndex - stride : 0:当前的nextIndex是否大于每个线程切割的
// 是:nextIndex - stride/否:0
// 将TRANSFERINDEX从nextIndex变成16
else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?nextIndex - stride : 0))) {
// 对bound赋值(16)
bound = nextBound;
// 对i赋值(31)
i = nextIndex - 1;
// 赋值,代表当前领取任务结束
// 该线程当前领取的任务是(16~31)
advance = false;
}
}
}线程领取扩容任务的流程:

8、transfer方法-扩容是否已经结束
// 判断扩容是否已经结束!
// i < 0:当前线程没有接收到任务!
// i >= n: 迁移的索引位置,不可能大于数组的长度,不会成立
// i + n >= nextn:因为i最大值就是数组索引的最大值,不会成立
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
// 第一次到这里:必定是false
// 如果再次到这里的时候,最后一个扩容的线程也扫描完了
if (finishing) {
nextTable = null;
table = nextTab;
// 重新更改当前的sizeCtl的数值:0.75N
sizeCtl = (n << 1) - (n >>> 1);
return;
}
// 到这里代表当前线程已经不需要去扩容了
// 那么它要把当前并发扩容的线程数减一
// SIZECTL ----> sc - 1
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
// 判断当前这个线程是不是最后一个扩容线程
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
// 如果不是的话,直接返回就好了
return;
// 如果是的话,当前线程还需要将旧数据全部扫描一遍,校验一下是不是都迁移完了
finishing = advance = true;
// 将当前的i重新变成原数组的长度
// 重新进行一轮校验
i = n; // recheck before commit
}
}9、 transfer方法-迁移数据(链表)
// 如果当前的i位置上没有数据,直接不需要迁移
else if ((f = tabAt(tab, i)) == null)
// 将原来i位置上CAS标记成fwd
// fwd的Hash为Move
advance = casTabAt(tab, i, null, fwd);
// // 拿到当前i位置的hash值,如果为MOVED,证明数据已经迁移过了。
else if ((fh = f.hash) == MOVED)
// 那么直接返回即可,主要是最后一个扩容线程扫描的时候使用
advance = true; // already processed
else {
// 锁住
synchronized (f) {
// 再次校验
if (tabAt(tab, i) == f) {
// ln:null - lowNode
Node<K,V> ln;
// hn:null - highNode
Node<K,V> hn;
// 如果当前的fh是正常的
if (fh >= 0) {
// 求当前的runBit
// 这里只会有两个结果:0 或者 n
int runBit = fh & n;
// 用当前lastRun指向f
Node<K,V> lastRun = f;
// 进行链表的遍历
for (Node<K,V> p = f.next; p != null; p = p.next) {
// 求每一个链表的p.hash & n
int b = p.hash & n;
// 如果当前的b不等于上一个节点
// 需要更新下runBit的数据和lastRun的指针
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
// 如果最后runBit=0的话
// lastRun赋值给ln
if (runBit == 0) {
ln = lastRun;
hn = null;
}
// 如果最后runBit=0的话
// lastRun赋值给hn
else {
hn = lastRun;
ln = null;
}
// 从数组头节点开始一直遍历到lastRun位置
for (Node<K,V> p = f; p != lastRun; p = p.next) {
// hash/key/value
int ph = p.hash; K pk = p.key; V pv = p.val;
// 如果当前的是0,则挂到ln下面
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
// 如果当前的是1,则挂到hn下面
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
// 将新数组i位置设置成ln
setTabAt(nextTab, i, ln);
// 将新数组i+N位置设置成hn
setTabAt(nextTab, i + n, hn);
// 将原来数组的i位置设置成fwd,代表迁移完毕
setTabAt(tab, i, fwd);
// 将advance设置成true,保证进行上面的while循环
// 执行上面的i--,进行下一节点的迁移计划
advance = true;
}
}
}
}
}9.1 LastRun机制
假如当前我需要将数组从 16 扩容至 32,我们看下原来的结构:

当我们进行下面这一步时:
int runBit = fh & n;
for (Node<K,V> p = f.next; p != null; p = p.next) {
// 求每一个链表的p.hash & n
int b = p.hash & n;
// 如果当前的b不等于上一个节点
// 需要更新下runBit的数据和lastRun的指针
if (b != runBit) {
runBit = b;
lastRun = p;
}
}图片如下:紫色代表 0,粉色代表 1

在迁移之前,我们要掌握一个知识,由于我们的数组是 2 倍扩容,所以原始数据的数据一定会落在新数组的 2 和 N + 2 的位置

最后将我们的数组从原始数组直接迁移过来,由于 lastRun 之后位置的数据都是一样的hash,所以直接全量迁移即可,不需要挨个遍历,这也是实施 lastRun 的原因,减少时间复杂度
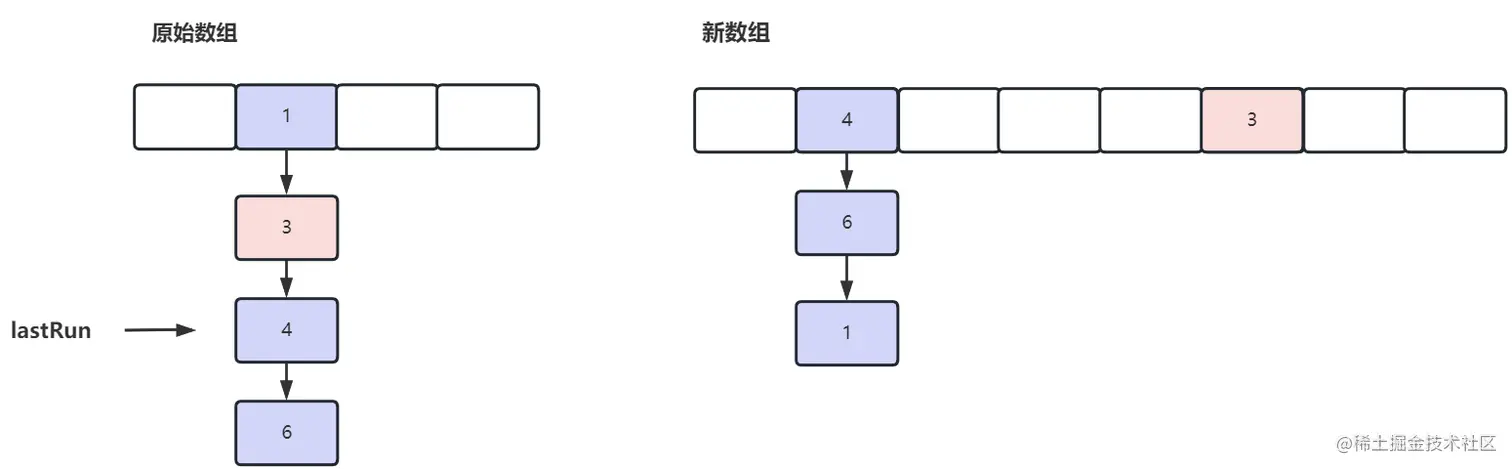
最终迁移效果如上,迁移完毕,减少 i 的下标,继续迁移下一个数组的位置。
10、协助扩容
// 如果当前的hash是正在扩容
if ((fh = f.hash) == MOVED){
// 进行协作式扩容
tab = helpTransfer(tab, f);
}
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
Node<K,V>[] nextTab;
int sc;
// 第一个判断:老数组不为null
// 第二个判断:新数组不为null (将新数组赋值给nextTab)
if (tab != null && (f instanceof ForwardingNode) &&
(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {
// 拿到扩容戳
int rs = resizeStamp(tab.length);
// 第一个判断:fwd中的新数组,和当前正在扩容的新数组是否相等。
// 相等:可以协助扩容。不相等:要么扩容结束,要么开启了新的扩容
// 第二个判断:老数组是否改变了。 相等:可以协助扩容。不相等:扩容结束了
// 第三个判断:如果正在扩容,sizeCtl肯定为负数,并且给sc赋值
while (nextTab == nextTable && table == tab &&
(sc = sizeCtl) < 0) {
// 判断扩容戳是否一致
// 看下transferIndex是否小于0,如果小于的话,说明扩容的任务已经被领完了
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
// 如果还有任务的话,CAS将当前的SIZECTL加一,协助扩容
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
// 协助扩容的代码,上面刚刚分析过
transfer(tab, nextTab);
break;
}
}
return nextTab;
}
return table;
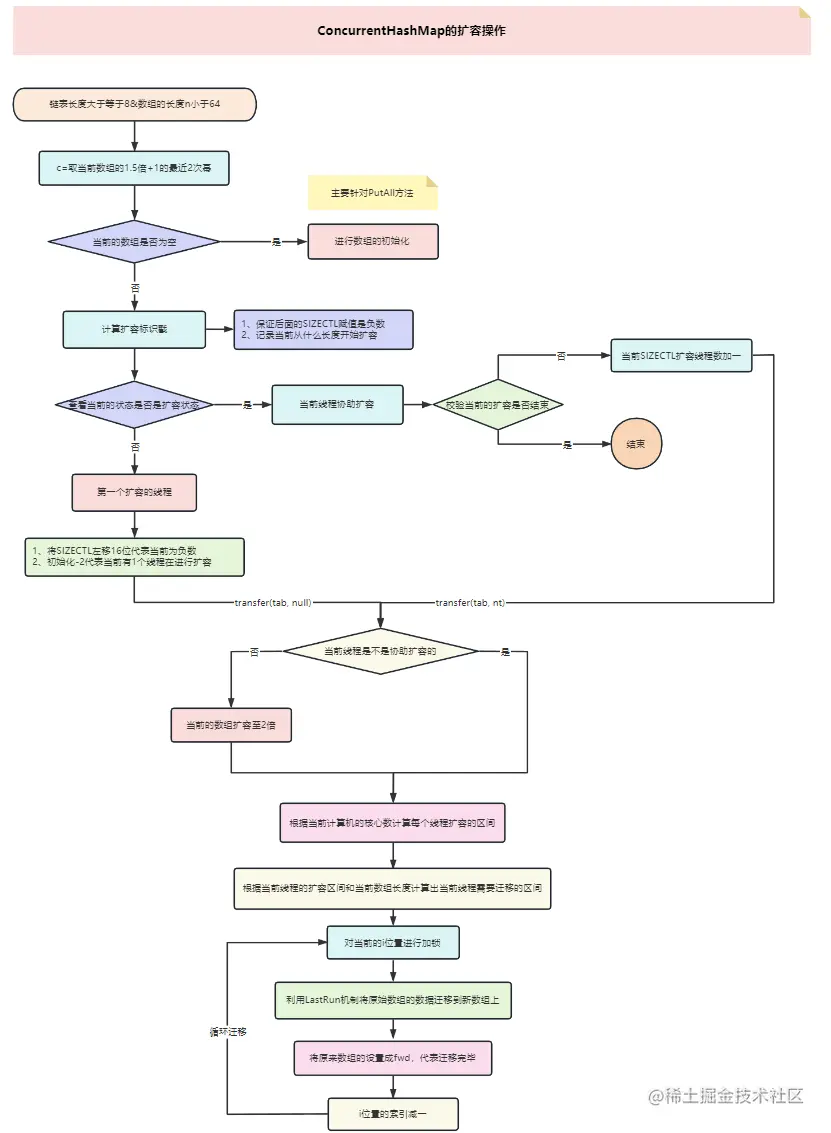
}三、流程图
以上就是Java面试常考之ConcurrentHashMap多线程扩容机制详解的详细内容,更多关于Java ConcurrentHashMap的资料请关注脚本之家其它相关文章!