
详解Java中布隆过滤器(Bloom Filter)原理及其使用场景
作者:地大第一渣男
1、什么是布隆过滤器
以下定义来自百度百科:
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
从上述定义我们可以得到以下关键信息:
- 布隆过滤器是由很长的二进制向量(即可以理解成很长的0、1数组)与一系列随机映射函数(Hash函数)构成。
- 布隆过滤器的作用是检索一个元素是否存在我们的集合之中。
- 优点是空间效率和查询时间都比一般的算法要好的多;缺点是有一定的误识别率和删除困难。
注意!接下来的原理我们都会基于定义来逐句解释和讲解布隆过滤器,请大家记住上述三点关键信息。
2、布隆过滤器的原理
2.1 布隆过滤器的数据结构
我们从定义总结的关键信息可知:布隆过滤器是由很长的二进制向量(即可以理解成很长的0、1数组)与一系列随机映射函数(Hash函数)构成。因此我们可以将布隆过滤器理解成下图这种很长的一个二进制数组:

正是由于布隆过滤器的数据结构仅需要存储“0”或“1”,因此所占用内存极少,这也是布隆过滤器的一大优点。
2.2 布隆过滤器的检索和插入原理
从上图布隆过滤器的数据结构图和定义的关键信息我们可以知道:布隆过滤器实际上是个很长的二进制数组,作用是检索一个元素是否存在我们的集合之中。那么布隆过滤器是如何通过上述数据结构判断一个元素是否存在我们的集合之中的呢?
这里就需要用到我们定义中提到的“一系列随机映射函数(Hash函数)”了。
首先我们需要知道什么是Hash函数?这里我们给出Hash函数的一个简要的说明:
简单来说Hash函数就是把输入值通过特定方式(hash函数) 处理后 生成一个值,这个值等同于存放数据的地址。
比如我们当前的Hash函数是 y=x²&(len-1),这里y是指最终在布隆过滤器的数据结构(二进制数组)中存放的下标位置,x指我们传入的值,len指数组的长度。那么如果当数组长度为100(举个例子,实际上数组长度是很长的),传入的值为5,则我们通过Hash函数得到的下标为25。那么此时我们便将下标25的值从0标为1。这就是插入(增加)数据的原理。
插入(增加)数据流程图如下:
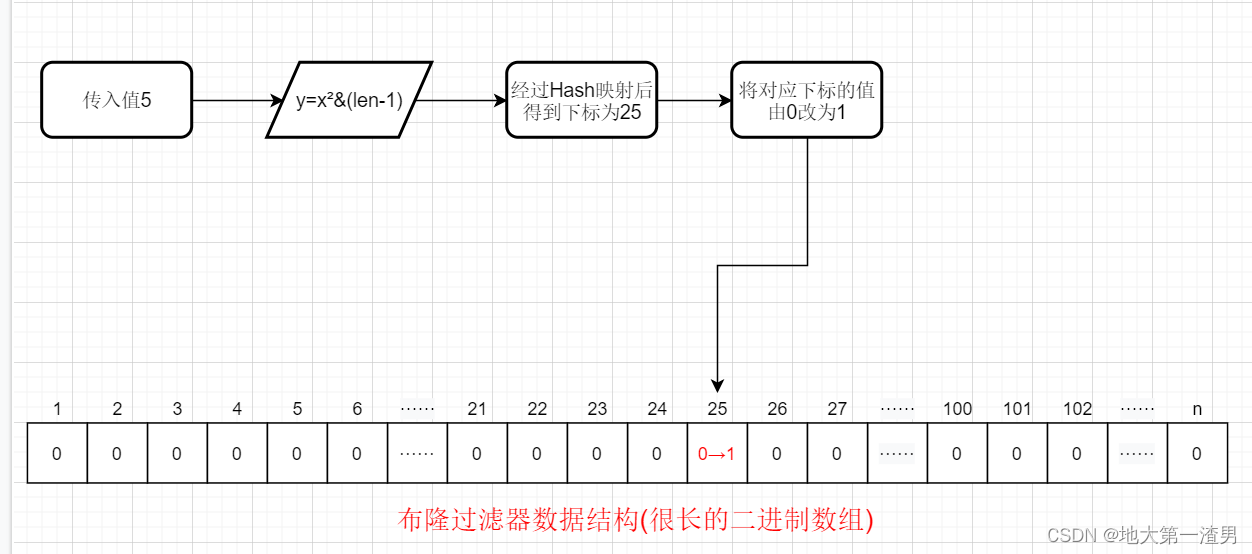
那么,当我们下次再输入这个值的时候,我们会得到当前数组对应下标的值为1,说明我们有这个数字!这是不是就是检索的原理了!
检索流程图如下:
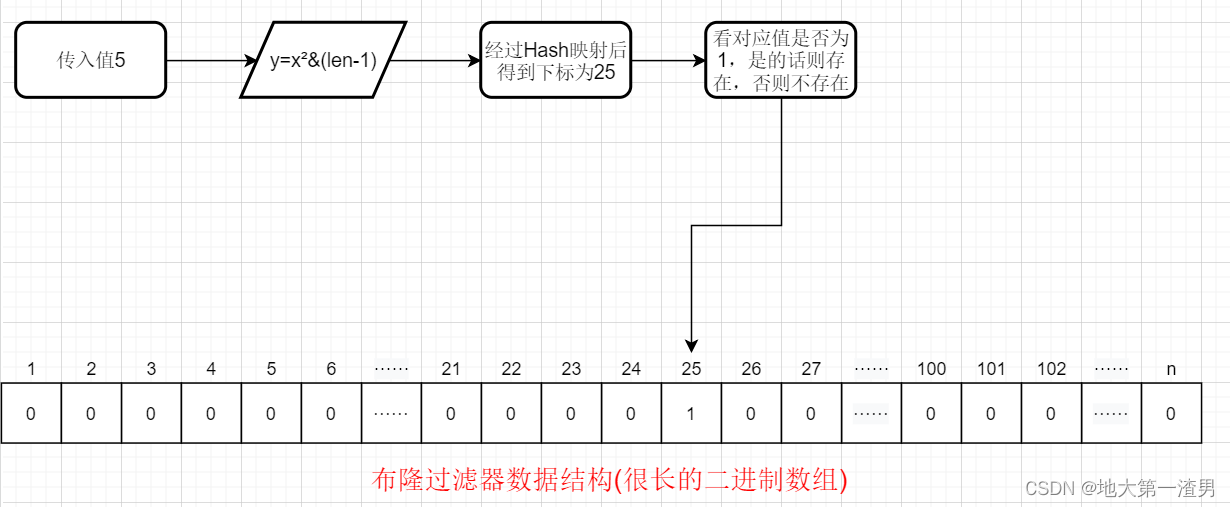
当然,这里有基础的同学肯定会发现我们上述说的过程虽然很简单,但是存在很大的问题:
①存在Hash冲突导致误判:
首先我们先对Hash冲突作一个简要说明:
根据key(键值)即经过一个Hash函数F(key)得到的结果的作为地址去存放当前的value值,但是却发现算出来的地址上已经被占用了,这就是所谓的hash冲突。
我们基于上述例子继续讲,在经过上述流程后,我们数组下标为25的值是1。此时我们传入一个值25,那么通过我们上述举例的Hash算法计算后得到的数组下标值也为25,那么此时布隆过滤器是不是就会认为值25是存在的!但是实际上是因为5和25经过Hash映射后得到同一个地址,导致了误判!
当然,这么简单的问题伟大的“布隆先生”肯定不会犯如此“低级”的错误,因此解决方法就和我们上述定义中的关键字“一系列Hash函数”有关了。
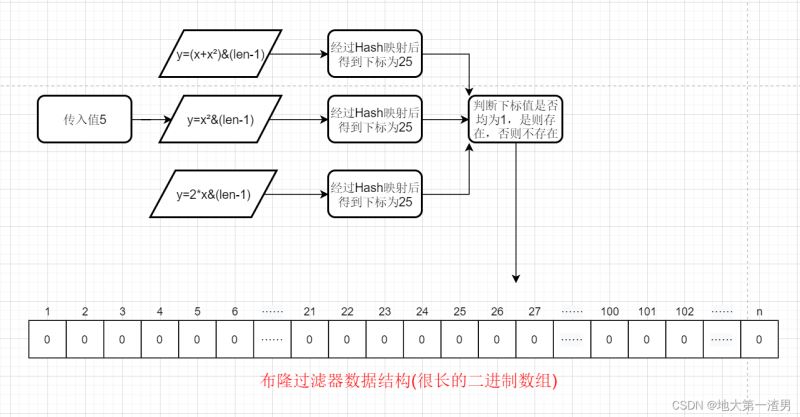
我们通过“一系列的Hash函数”,比如Hash函数①y=x²&(len-1)②y=(2*x)&(len-1) ③y=(x+x²)&(len-1) 这三个Hash函数一起来决定某个元素是否存在我们的集合中。
也就是检索流程变为:将key值传入一系列Hash函数得到对应的一系列数组地址(索引下标),注意这里一般来说有几个Hash函数就会得到几个地址,然后去判断这几个索引下标对应的值是否均为1,是的话则说明存在,否则不存在。
上述才是布隆过滤器检索元素是否存在的真正流程,检索元素流程图因此对应变化如下:
插入元素流程变为:根据一系列Hash函数得到一系列地址,将对应地址下标值改为1,流程图如下:
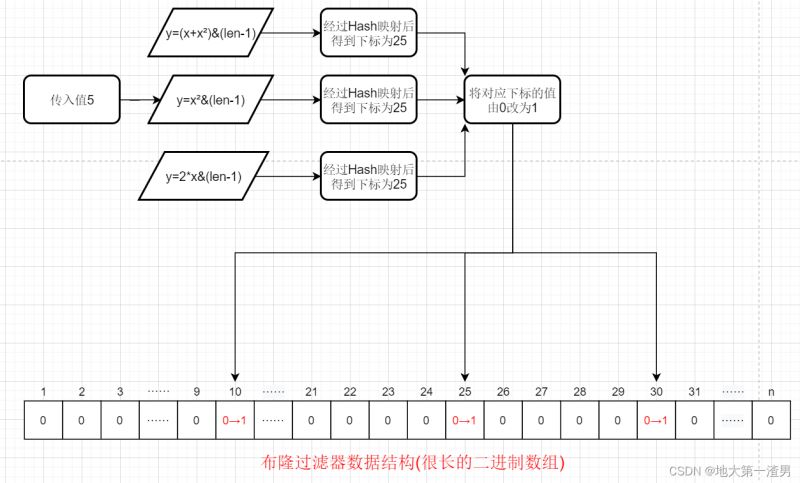
当然,我们从布隆过滤器定义中提到的缺点可以知道:布隆过滤器会有一定误判率。说明即使是在一系列Hash函数下,依然会有巧合:“一个不存在的元素,对应的一系列映射后的地址的值为1,即出现误判”。这也是无法避免的事情,毕竟如果数据量很大的话,很难防止有一定量的、不存在的“幸运儿”能通过布隆过滤器的筛选。
当然,我们在使用布隆过滤器的时候能通过设置两个参数:①预期数据量 ②误判率期望值。我们可以通过设置“误判率期望值”来达到我们能接受的误判率。
当然!大家别异想天开:“哎呀,那我设置0不就行了吗?”这肯定是不可能的,而且设置的误判率越低,数据量越大,占用内存则越大,运行时间则越慢!这也很好理解:数据量越大肯定占用越多内存空间,误判率越低则说明要越多的Hash函数来进行运算,则运行时间越慢,一个key对应的地址也多了,肯定占用越多内存空间。
2.3 布隆过滤器元素的修改和删除
我们从定义可以知道:我们想要修改或删除一个元素时,同时去保证布隆过滤器不受影响是几乎不可能的。
为什么这样说呢,由于我们在插入元素时,不同的值可能经过一系列Hash函数后得到的一系列地址,总有可能两个或多个值经过某个Hash函数映射后得到其中一个地址会一样,此时数组中对应的下标肯定为1,当我们删除或修改某个元素后,我们如果想将其原来对应地址的值从1改为0后,无法确定这个地址是否也对应其他值,如果贸然修改,可能会导致其他原本存在的值在检索时返回不存在的情况!这种情况是极其危险的,可能会导致数据的“逻辑丢失”。
因此我们这里不讨论修改和删除的情况。因为布隆过滤器对元素的删除不太支持,目前有一些变形的特定布隆过滤器支持元素的删除。
3、布隆过滤器的使用场景
3.1 Redis通过布隆过滤器防止缓存穿透
首先我们需要知道什么是缓存穿透,这里我们给出缓存穿透的定义。
Redis缓存穿透指访问一个缓存和数据库中都不存在的key,由于这个key在缓存中不存在,则会到数据库中查询,数据库中也不存在该key,无法将数据添加到缓存中,所以每次都会访问数据库导致数据库压力增大。
我们可以在访问Redis之前使用布隆过滤器来对请求的key进行过滤, 可以大大减少那些恶意攻击。当然,会存在一定误判率,但是使用布隆过滤器后,“不法分子”肯定对我们服务器就没那么容易进行恶意攻击了。
3.2 RocketMQ通过布隆过滤器防止消息重复消费
为了防止RocketMQ消息重复消费,我们发送消息时可以对每个消息设置唯一的key,然后在消费者处利用布隆过滤器对消息的key检索,如果存在则说明消息已经消费过,不消费。不存在则进行消费,然后插入布隆过滤器。
当然,上面两个例子仅仅是举的例子,布隆过滤器能使用的地方很多,只要但凡涉及“数据过滤”均可以考虑使用“布隆过滤器”来实现。
4、布隆过滤器优缺点
4.1 优点:
- 时间复杂度低,增加和查询元素的时间复杂为O(N),(N为哈希函数的个数,通常情况比较小)
- 保密性强,布隆过滤器不存储元素本身
- 存储空间小,如果允许存在一定的误判,布隆过滤器是非常节省空间的(相比其他数据结构如Set、Map集合)
4.2 缺点:
- 有点一定的误判率,但是可以通过调整参数来降低
- 无法获取元素本身
- 很难删除元素
以上就是详解Java中布隆过滤器(Bloom Filter)原理及其使用场景的详细内容,更多关于Java布隆过滤器的资料请关注脚本之家其它相关文章!