
8张图带你全面了解Java kafka的核心机制
作者:JAVA旭阳
kafka基础架构
现在假如有100T大小的消息要发送到kafka中,数据量非常大,一台机器存储不下,面对这种情况,你该如何设计呢?
很简单,分而治之,一台不够,那就多台,这就形成了一个kafka集群。如下图所示,一个broker就是一个kafka节点,100T数据就有3个节点分担,每个节点约33T,这样就能解决问题了,还能提高吞吐量。
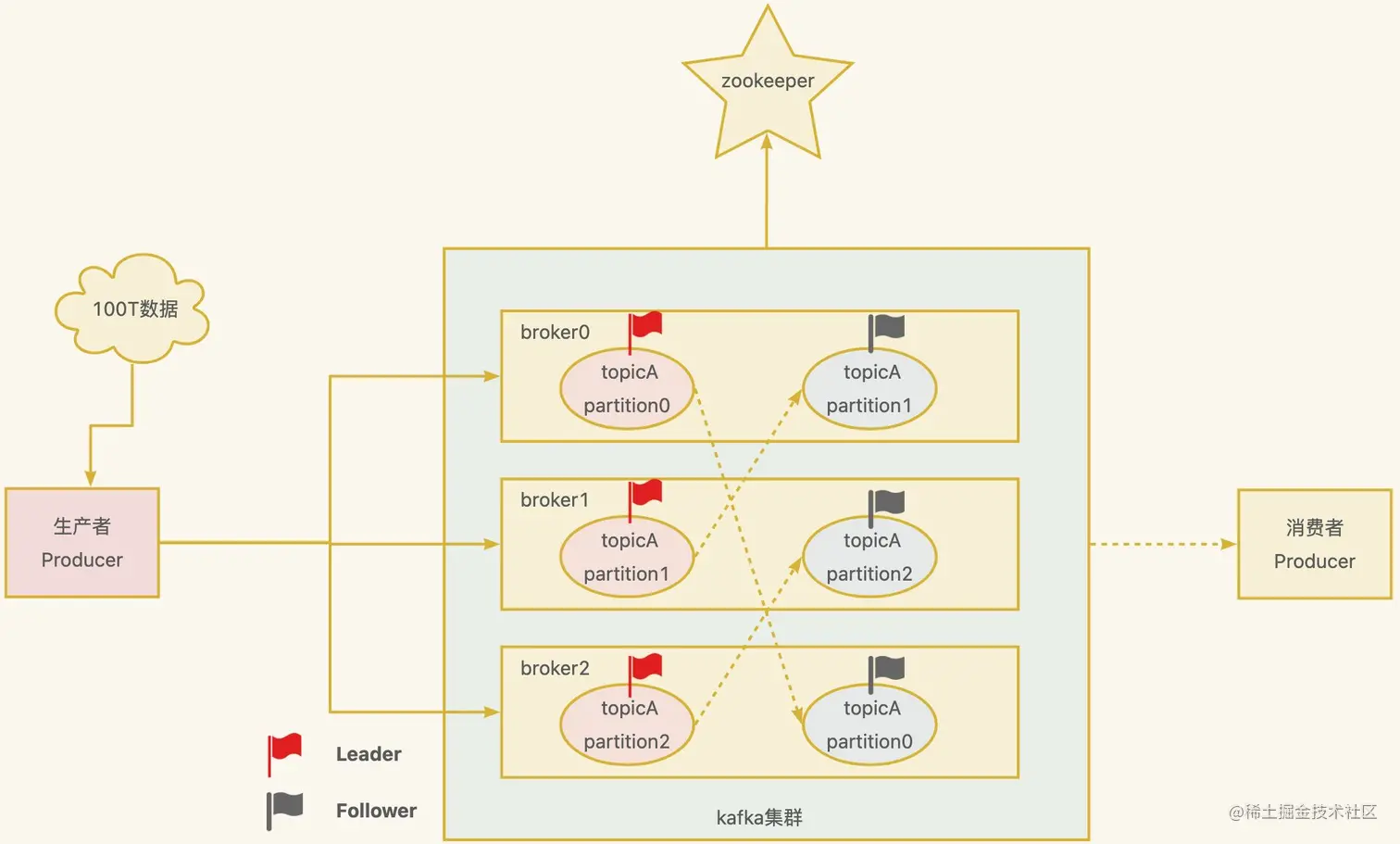
- Topic: 可以理解为一个队列,一个kafka集群中可以定义很多的topic,比如上图中的
topicA。 - Partition: 为了实现扩展性,提高吞吐量,一个非常大的
topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。比如上图中的topicA被分成了3个partition。 - Replica: 副本,如果数据只放在一个
broker中,万一这个broker宕机了怎么办?为了实现高可用,一个topic的每个分区都有若干个副本,一个Leader和若干个Follower。比如上图中的虚线连接的就是它的副本。 - Leader: 每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是
Leader。 - Follower: 每个分区多个副本中的“从”,实时从
Leader中同步数据,保持和Leader数据的同步。Leader发生故障时,某个Follower会成为新的Leader。 - Producer: 消息生产者,就是向
Kafka broker发消息的客户端,后面详细讲解。 - Consumer: 消息消费者,向
Kafka broker取消息的客户端,多个Consumer会组成一个消费者组,后面详细讲解。 - Zookeeper:用来记录kafka中的一些元数据,比如kafka集群中的broker,leader是谁等等,但
Kafka2.8.0版本以后也支持非zk的方式,大大减少了和zk的交互。
kafka生产者流程
前面通过一张图片讲解了kafka整体的架构,那现在我们来看看kafka生产者发送的整个过程,这里面也是大有文章。
在消息发送的过程中,涉及到了两个线程——main 线程和 Sender 线程。在 main 线程中创建了一个双端队列 RecordAccumulator。main 线程将消息发送给 RecordAccumulator,Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker。

- 在主线程中由
kafkaProducer创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator, 也称为消息收集器)中。
- 拦截器: 可以用来在消息发送前做一些准备工作,比如按照某个规则过滤不符合要求的消息、修改消息的内容等,也可以用来在发送回调逻辑前做一些定制化的需求,比如统计类工作。
- 序列化器: 用于在网络传输中将数据序列化为字节流进行传输,保证数据不会丢失。
- 分区器: 用于按照一定的规则将数据分发到不同的kafka broker节点中
Sender线程负责从RecordAccumulator获取消息并将其发送到Kafka中。
RecordAccumulator主要用来缓存消息以便Sender线程可以批量发送,进而减少网络传输的资源消耗以提升性能。
RecordAccumulator缓存的大小可以通过生产者客户端参数buffer.memory配置,默认值为33554432B,即32M。
- 主线程中发送过来的消息都会被迫加到
RecordAccumulator的某个双端队列(Deque)中,RecordAccumulator内部为每个分区都维护了一个双端队列,即Deque<ProducerBatch>, 消息写入缓存时,追加到双端队列的尾部。 Sender读取消息时,从双端队列的头部读取。ProducerBatch是指一个消息批次;与此同时,会将较小的ProducerBatch凑成一个较大ProducerBatch,也可以减少网络请求的次数以提升整体的吞吐量。ProducerBatch大小可以通过batch.size控制,默认16kb。Sender线程会在有数据积累到batch.size,默认16kb,或者如果数据迟迟未达到batch.size,Sender线程等待linger.ms设置的时间到了之后就会获取数据。linger.ms单位ms,默认值是0ms,表示没有延迟。
Sender从RecordAccumulator获取缓存的消息之后,会将数据封装成网络请求<Node,Request>的形式,这样就可以将Request请求发往各个Node了。- 请求在从
sender线程发往Kafka之前还会保存到InFlightRequests中,它的主要作用是缓存了已经发出去但还没有收到服务端响应的请求。InFlightRequests默认每个分区下最多缓存5个请求,可以通过配置参数为max.in.flight.request.per. connection修改。 - 请求
Request通过通道Selector发送到kafka节点。 - 发送后,需要等待kafka的应答机制,取决于配置项
acks.
- 0:生产者发送过来的数据,不需要等待数据落盘就应答。
- 1:生产者发送过来的数据,
Leader收到数据后应答。 - -1(all):生产者发送过来的数据,Leader和副本节点收齐数据后应答。默认值是-1,-1 和all 是等价的。
Request请求接受到kafka的响应结果,如果成功的话,从InFlightRequests清除请求,否则的话需要进行重发操作,可以通过配置项retries决定,当消息发送出现错误的时候,系统会重发消息。retries表示重试次数。默认是 int 最大值,2147483647。- 清理消息累加器
RecordAccumulator中的数据。
kafka消费者流程
原来kafka生产者发送经过了这么多流程,我们现在来看看kafka消费者又是如何进行的呢?
Kafka 中的消费是基于拉取模式的。消息的消费一般有两种模式:推送模式和拉取模式。推模式是服务端主动将消息推送给消费者,而拉模式是消费者主动向服务端发起请求来拉取消息。
kafka是以消费者组进行消费的,一个消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同。

- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。如果向消费组中添加更多的消费者,超过主题分区数量,则有一部分消费者就会闲置,不会接收任何消息。
- 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
那么问题来了,kafka是如何指定消费者组的每个消费者消费哪个分区?每次消费的数量是多少呢?
一、如何制定消费方案

- 消费者consumerA,consumerB, consumerC向kafka集群中的协调器
coordinator发送JoinGroup的请求。coordinator主要是用来辅助实现消费者组的初始化和分区的分配。
coordinator老大节点选择 =groupid的hashcode值 % 50(__consumer_offsets内置主题位移的分区数量)例如:groupid的hashcode值 为1,1% 50 = 1,那么__consumer_offsets主题的1号分区,在哪个broker上,就选择这个节点的coordinator作为这个消费者组的老大。消费者组下的所有的消费者提交offset的时候就往这个分区去提交offset。
- 选出一个
consumer作为消费中的leader,比如上图中的ConsumerB。 - 消费者
leader制定出消费方案,比如谁来消费哪个分区等 - 把消费方案发给
coordinator - 最后
coordinator就把消费方 案下发给各个consumer, 图中只画了一条线,实际上是有下发各个consumer。
注意,每个消费者都会和coordinator保持心跳(默认3s),一旦超时(session.timeout.ms=45s),该消费者会被移除,并触发再平衡;或者消费者处理消息的时间过长(max.poll.interval.ms=5分钟),也会触发再平衡,也就是重新进行上面的流程。
二、消费者消费细节
现在已经初始化消费者组信息,知道哪个消费者消费哪个分区,接着我们来看看消费者细节。
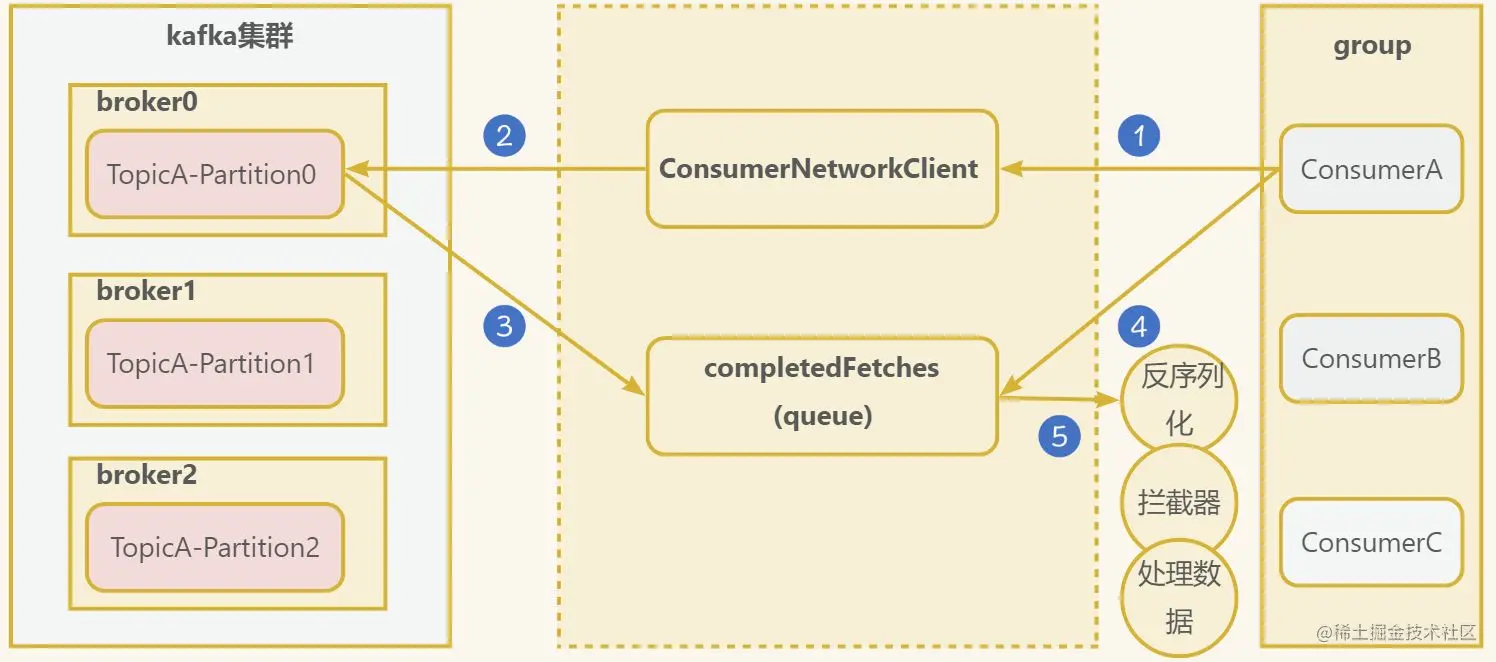
- 消费者创建一个网络连接客户端
ConsumerNetworkClient, 发送消费请求,可以进行如下配置:
fetch.min.bytes: 每批次最小抓取大小,默认1字节fetch.max.bytes: 每批次最大抓取大小,默认50Mfetch.max.wait.ms:最大超时时间,默认500ms
- 发送请求到kafka集群
- 成功的回调,会将数据保存到
completedFetches队列中 - 消费者从队列中抓取数据,根据配置
max.poll.records一次拉取数据返回消息的最大条数,默认500条。 - 获取到数据后,需要经过反序列化器、拦截器等。
kafka的存储机制
我们都知道消息发送到kafka,最终是存储到磁盘中的,我们看下kafka是如何存储的。

一个topic分为多个partition,每个partition对应于一个log文件,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,每个partition分为多个segment。每个segment包括:“.index”文件、“.log”文件和.timeindex等文件,Producer生产的数据会被不断追加到该log文件末端。

上图中t1即为一个topic的名称,而“t1-0/t1-1”则表明这个目录是t1这个topic的哪个partition。

kafka中的索引文件以稀疏索引(sparseindex)的方式构造消息的索引,如下图所示:

1.根据目标offset定位segment文件
2.找到小于等于目标offset的最大offset对应的索引项
3.定位到log文件
4.向下遍历找到目标Record
注意:index为稀疏索引,大约每往log文件写入4kb数据,会往index文件写入一条索引。通过参数log.index.interval.bytes控制,默认4kb。
那kafka中磁盘文件保存多久呢?
kafka 中默认的日志保存时间为 7 天,可以通过调整如下参数修改保存时间。
log.retention.hours,最低优先级小时,默认 7 天。log.retention.minutes,分钟。log.retention.ms,最高优先级毫秒。log.retention.check.interval.ms,负责设置检查周期,默认 5 分钟。
总结
其实kafka中的细节十分多,本文也只是对kafka的一些核心机制从理论层面做了一个总结,更多的细节还是需要自行去实践,去学习。
以上就是8张图带你全面了解Java kafka的核心机制的详细内容,更多关于Java kafka核心机制的资料请关注脚本之家其它相关文章!