
源码分析Go语言中gofmt实现原理
作者:偷天神猫
前言
gofmt 是 Go 语言官方提供的一个工具,用于自动格式化 Go 源代码,使其符合 Go 语言的官方编码风格。其实现原理大致可以分为以下几个步骤:
读取和解析源代码:
gofmt首先读取指定的 Go 源代码文件或目录。对于目录,它会递归地查找所有的.go文件。然后,它使用 Go 语言的解析库(如go/parser和go/token)来解析源代码,并构建出一个抽象语法树(AST)。遍历抽象语法树(AST):一旦源代码被解析成 AST,
gofmt会遍历这棵树。这个过程中,它会识别和修改树中的节点,以便按照 Go 语言的格式化规则调整代码的格式。这包括调整缩进、空格、换行符等。格式化规则应用:
gofmt通过内置的一系列格式化规则来调整和优化代码的布局。这些规则涵盖了从基本的缩进和行长度控制到更复杂的代码结构对齐等方面。gofmt的目标是保持代码风格的一致性,以提高代码的可读性和维护性。生成和输出格式化后的代码:遍历和修改 AST 后,
gofmt将根据修改后的 AST 生成格式化后的源代码。这一步是通过 AST 的序列化完成的,即将 AST 转换回 Go 语言源代码的文本表示。覆盖原始文件或输出到标准输出:默认情况下,
gofmt会将格式化后的代码输出到标准输出(屏幕)。如果指定了-w(write)选项,gofmt会将格式化后的代码写回原始文件,替换掉原来的内容。还有其他选项可以用来控制输出,例如-d选项会显示格式化前后的差异。
gofmt 的设计哲学是“无需配置”,旨在为 Go 社区提供一个统一的代码格式标准。通过自动格式化代码,gofmt 减少了代码审查中关于风格的讨论,使开发者可以更专注于代码的逻辑和功能上。
源码分析
以目前最新的go稳定版1.22.1为例,gofmt库的源码文件如下所示,共计8个文件和一个测试数据文件夹:
调用流程
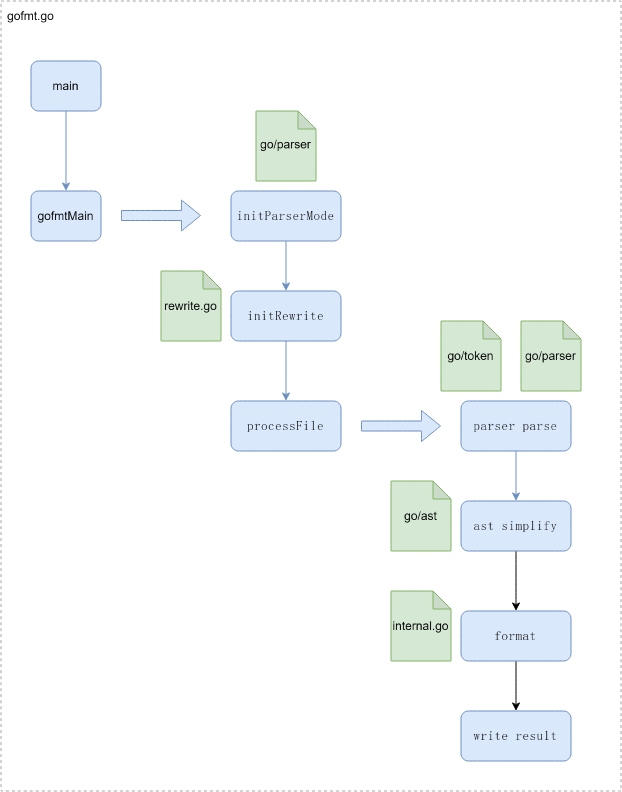
我们先来预览下gofmt库的函数调用流程图
源码处窥
下面我们通过阅读源码直观的感受下gofmt究竟是怎么工作的。
gofmt.go则是gofmt库的核心,也是它的入口,所以我们从这个文件开始看起。 在该文件开头可以看到gofmt的flag定义:
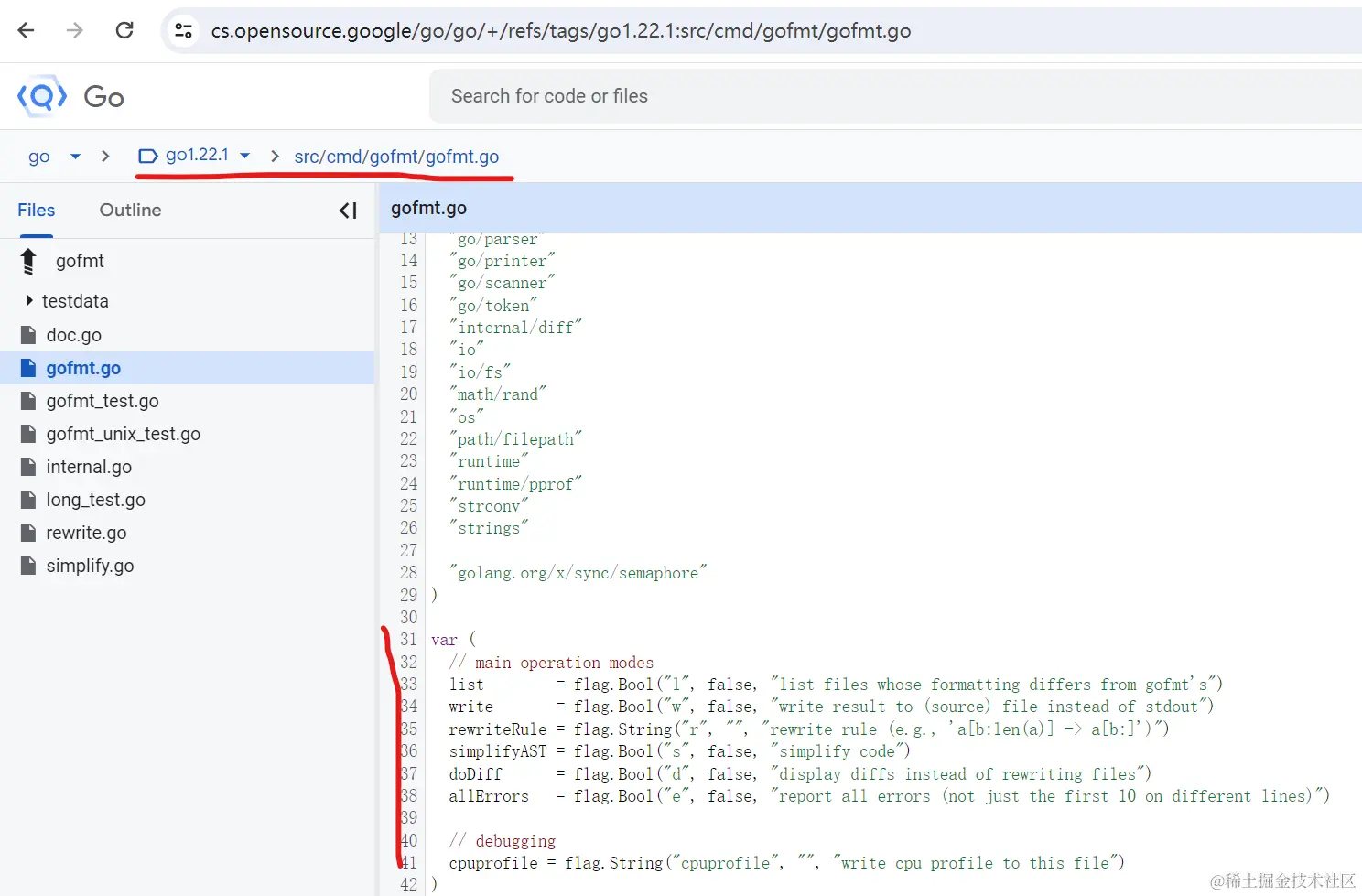
入口函数在358行,在370行又调用了真正负责格式化处理流程的gofmtMain:

gofmtMain中的关键函数是processFile,不过它的运行需要依赖当前文件中的initParserMode()以及rewrite.go中的initRewrite()

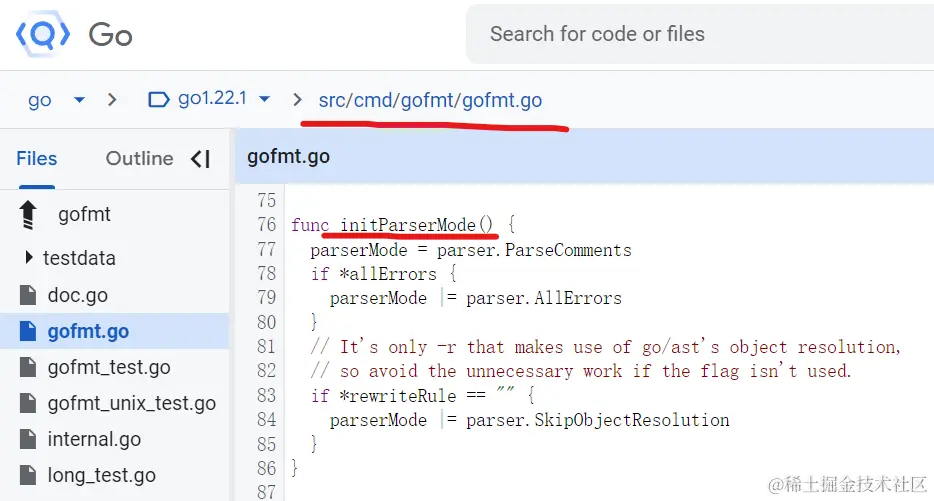
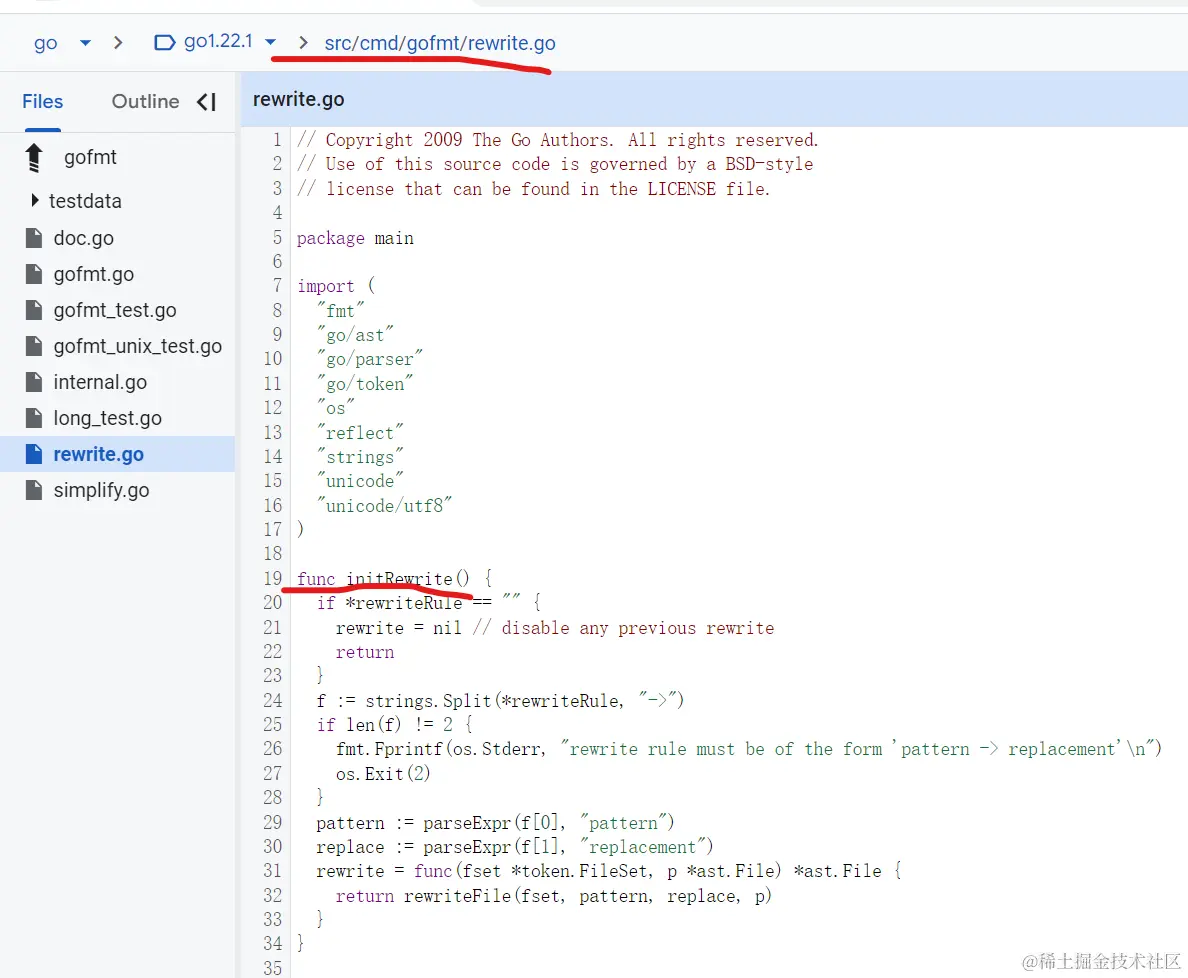
这两个init函数我们按下不表,因为他们不是我们本文的重点,有兴趣的同学可以按图索骥自行查看其实现。我们回到processFile函数,继续查看其核心执行逻辑。
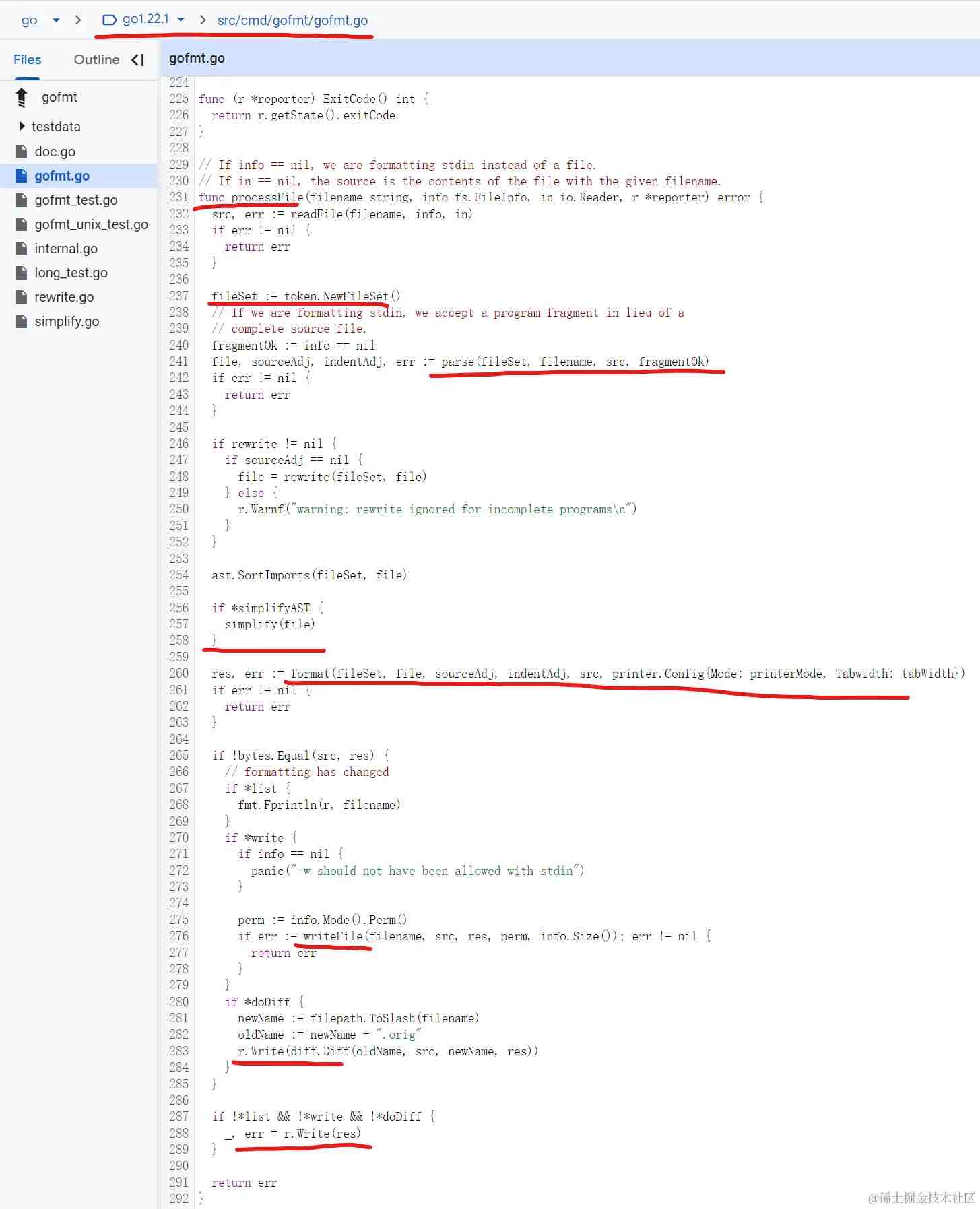
processFile读取文件后,调用internal.go中的parse函数进行语法解析,然后依赖simplify.go中的simplify生成抽象语法树。在这两个文件中我们终于看到【大致流程】中提到的go/parser 和 go/token两个关键库,其实另外一个go/ast也很重要,它主要负责抽象语法树相关的工作。
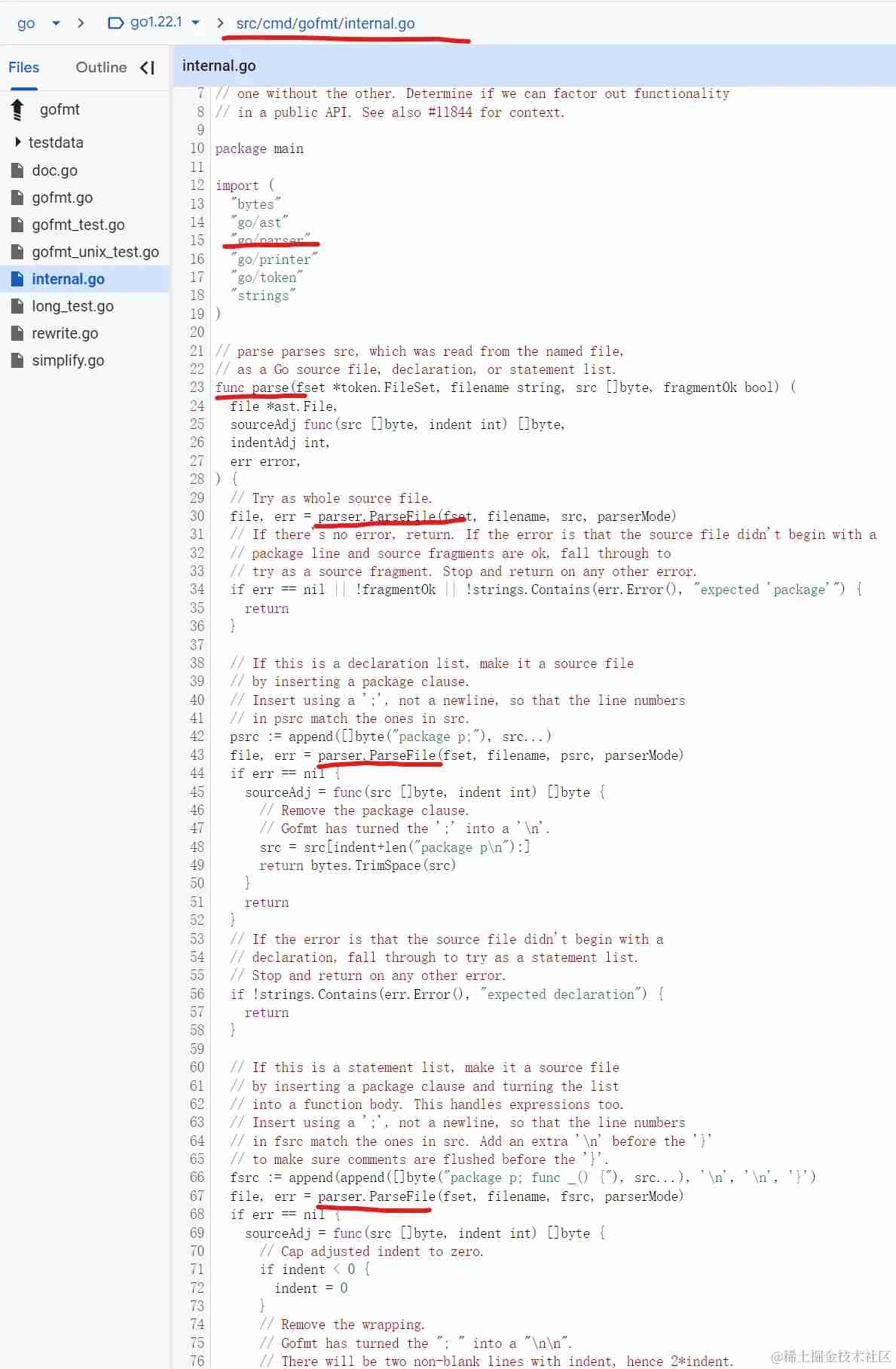
gofmt.go重点依赖的库
go/token
功能作用:go/token 包定义了 Go 语言的词法标记(tokens)及其位置信息(文件位置)。它为语法分析和 AST 构建提供基础设施,包括标识符、关键字、文本位置等的表示。
应用场景:这个包通常与 go/parser 和 go/ast 结合使用,用于实现对 Go 代码的词法分析和位置追踪。应用场景包括编译器开发、代码分析工具、代码格式化工具等,任何需要精确控制和了解代码结构及元素位置的场合。
go/ast
功能作用:go/ast 包提供了构造和操作 Go 语言源代码的抽象语法树(AST)的能力。AST 是源代码的树状结构表示,每个节点代表代码的一部分,比如表达式、语句或声明。
应用场景:它主要用于开发需要分析、检查、修改或生成 Go 代码的工具,如静态分析工具、代码格式化程序、重构工具等。
go/parser
功能作用:go/parser 包负责解析 Go 源代码文件,将其转化为 AST(抽象语法树)。它提供了解析 Go 代码的接口和功能,可以从文件、字符串等输入源解析 Go 代码。
应用场景:用于需要读取和解析 Go 源代码的场合,比如编写代码编辑器的语法高亮功能、静态代码分析、文档生成工具等。
format函数
通过阅读processFile源码我们了解到,当源码被解析为AST后,gofmt执行了一个format函数来生成格式化后的结果。
res, err := format(fileSet, file, sourceAdj, indentAdj, src, printer.Config{Mode: printerMode, Tabwidth: tabWidth})
if err != nil {
return err
}
internal.go中放置了fotmat函数的实现。
其实format函数才是gofmt真正发挥威力的地方,毕竟读文件、解析文件、生成语法树、写文件这些工作都是调用的别的库,而format才是它自己实打实实现的,我添加了详细的中文注释。
// format函数用于格式化给定的包文件,该文件最初从src获得,
// 并基于原始源代码通过sourceAdj和indentAdj进行结果调整。
func format(
fset *token.FileSet, // 文件集,用于存储和处理文件的位置信息
file *ast.File, // 抽象语法树表示的文件
sourceAdj func(src []byte, indent int) []byte, // 调整源代码的函数
indentAdj int, // 缩进调整量
src []byte, // 原始源代码
cfg printer.Config, // 打印配置,控制输出格式
) ([]byte, error) {
if sourceAdj == nil {
// 如果没有提供sourceAdj函数,则处理完整的源文件
var buf bytes.Buffer // 创建一个缓冲区来存储格式化后的代码
err := cfg.Fprint(&buf, fset, file) // 将格式化后的文件输出到缓冲区
if err != nil {
return nil, err // 如果发生错误,返回错误
}
return buf.Bytes(), nil // 返回缓冲区中的字节切片
}
// 处理部分源文件的情况
// 确定并添加前导空格
i, j := 0, 0
for j < len(src) && isSpace(src[j]) { // 遍历源代码前面的空白字符
if src[j] == '\n' {
i = j + 1 // 更新最后一行前导空间的字节偏移量
}
j++
}
var res []byte // 用于存储最终结果的切片
res = append(res, src[:i]...) // 将前导空格添加到结果中
// 确定并添加第一行代码的缩进
// 除非没有制表符,否则忽略空格,空格视为一个制表符
indent := 0
hasSpace := false
for _, b := range src[i:j] {
switch b {
case ' ':
hasSpace = true
case '\t':
indent++ // 统计制表符数量作为缩进量
}
}
if indent == 0 && hasSpace {
indent = 1 // 如果没有制表符但有空格,则将缩进设置为1
}
for i := 0; i < indent; i++ {
res = append(res, '\t') // 将缩进添加到结果中
}
// 格式化源代码
cfg.Indent = indent + indentAdj // 设置缩进配置
var buf bytes.Buffer
err := cfg.Fprint(&buf, fset, file) // 将格式化的代码写入缓冲区,不包括前导和尾随空格
if err != nil {
return nil, err
}
out := sourceAdj(buf.Bytes(), cfg.Indent) // 调整格式化后的代码
// 如果调整后的输出为空,则源代码除了空白字符外是空的
// 结果是传入的源代码
if len(out) == 0 {
return src, nil
}
// 否则,将输出添加到前导空间后面
res = append(res, out...)
// 确定并添加尾随空格
i = len(src)
for i > 0 && isSpace(src[i-1]) {
i-- // 回溯以确定尾随空格的开始位置
}
return append(res, src[i:]...), nil // 将尾随空格添加到结果中并返回
}
结语
至此我们得已窥到gofmt的庐山真面目。
对于想要了解gofmt大体实现流程的同学来说,走到这里实属不易,您已经超越了只是知道怎么使用gofmt的段位。
不过对于想要了解更多细节的同学来说,越往下挖疑问反而越多,比如:
- 用于调整源代码的函数
sourceAdj究竟是如何实现的? parser、ast、token这些包内部又是如何实现的?他们应用了哪些基础算法知识?
限于篇幅,我就不在本文作答以上问题了,我觉得能给大家带来思考和启发就是最好的分享。后续如果大家对于源码解析很感兴趣,我再作进一步的细节展开。
以上就是源码分析Go语言中gofmt实现原理的详细内容,更多关于Go gofmt实现原理的资料请关注脚本之家其它相关文章!