
go循环依赖的最佳解决方案
作者:人间小傻瓜
前言:
import cycle not allowed(循环依赖不被允许)相信作为每一个golang语言使用研发,都遇到过这个令人头痛的报错。循环依赖是指两个或多个模块之间互相依赖,形成了一个闭环的情况。这种情况下,编译器或解释器无法确定应该先加载哪个模块,从而导致程序无法正常运行。本文会结合部分案例对解决方案进行讲解。
包引用循环依赖
golang 代码包的加载过程:
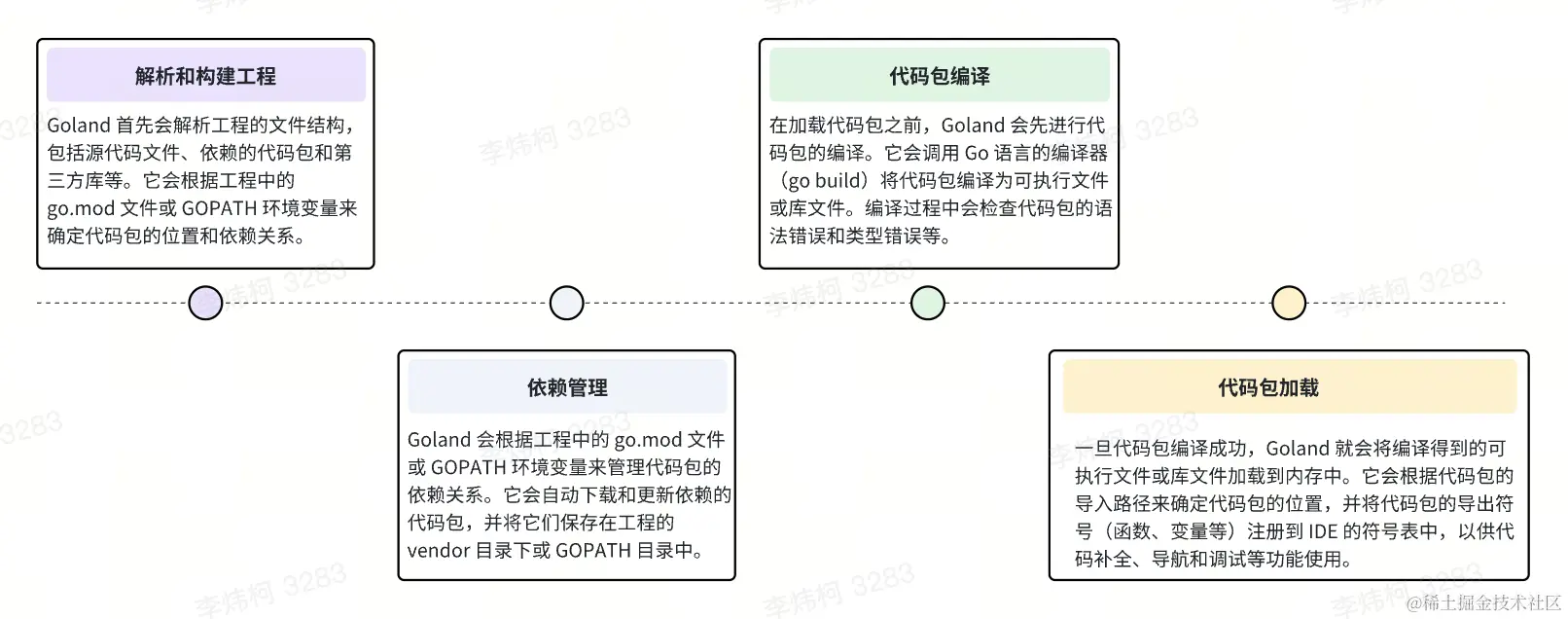
问题一:循环依赖是在上面哪一个环节报错?
编译环节。 当存在循环依赖时,golang编译代码时会首先解析代码包的依赖关系,然后按照依赖关系的顺序进行编译。如果存在循环依赖,即A依赖于B,而B又依赖于A,golang会检测到这种循环依赖关系,并报告编译错误。编译错误的具体信息会包括代码包路径和导致循环依赖的具体文件及行号。
问题二:循环依赖的危害有哪些?
对于golang来说,最大的危害就是连编译都过不了...
问题三:go高版本是否支持从编译环节解决循环依赖的问题?
不支持。 java解决循环依赖的方法有很多,延迟初始化或懒加载、三级缓存等都是解决包循环依赖的利器。然而golang并没有配置或注解来解决循环依赖的问题。

相比于代码的执行效率,Go更加注重编译的速度。虽然Go的编译器不会像C/C++那样花费大量的时间生成高效的机器码,但它们更专注于快速的编译大量的源代码。支持循环依赖会导致代码编译时间增加,因为每次改变某个依赖项都会重新编译整个依赖树。此外,循环依赖还增加了链接时间和使独立测试和包重用的难度(由于包之间可能不可靠分离,单元测试也会变得更加困难)。
解决方案:
重新梳理领域模型
在遇到循环依赖的时候,最先考虑的就是模块分层是否不清晰,领域划分是否准确。下图是最基础的DDD模型。

下层不依赖上层
我们应该有着清晰的认知,在服务中,哪个模块是下层,哪个是上层。
如数据库dao层,reids包这些都是处于基础设施层的模块,那么其就不能依赖于领域层逻辑接口。如果想要实现写入数据库并写入redis,这个逻辑就影响在领域层实现而不是在基础设施层。
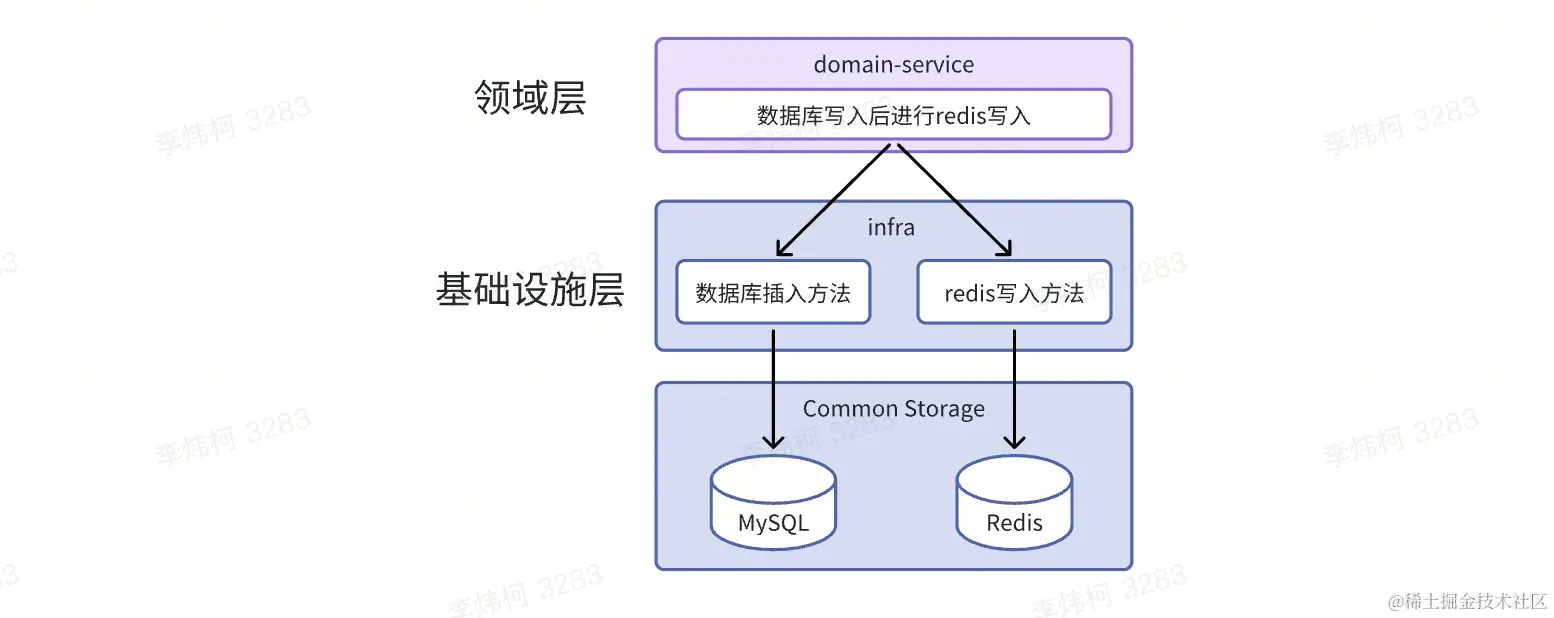
同层不能互相调用
举个例子,假设我们有外呼模块和短信模块,部分场景在外呼后要自动发送短信,部分场景发完短信后要机器人外呼,就出现循环依赖了。我们可以有两种解决方案,1.将互相调用的逻辑往上层移动。2.将两个模块放在一起作为一个统一的用户触达模块。

有些时候,在没出现循环依赖的时候,我们可能并没有意识到出现了同层调用的情况,等到出现循环依赖再想保持良好的架构模式就需要代码重构了。 约束是死的,人是活的。总是有一些场景,你不得不在同层模块间进行调用,但是改造的消耗的成本远比不遵守准则来得低,则进行同层间调用也不是什么丢脸的事。

目前很多服务还是依赖于传统的MVC模型进行开发,三层结构使得所有的业务逻辑都耦合在service(业务逻辑)层,虽然可阅读性下降了,但是也降低了循环依赖问题发生(所有的业务逻辑都在一个包下)。DDD在给我们带来高可维护性,可阅读性的同时,也需要我们更清晰的对业务有明确的认知和一定的技术支持。两者不论好坏,各有各自适用的业务场景。
依赖倒置原则
依赖倒置又叫做依赖反转。依赖关系如下图所示:
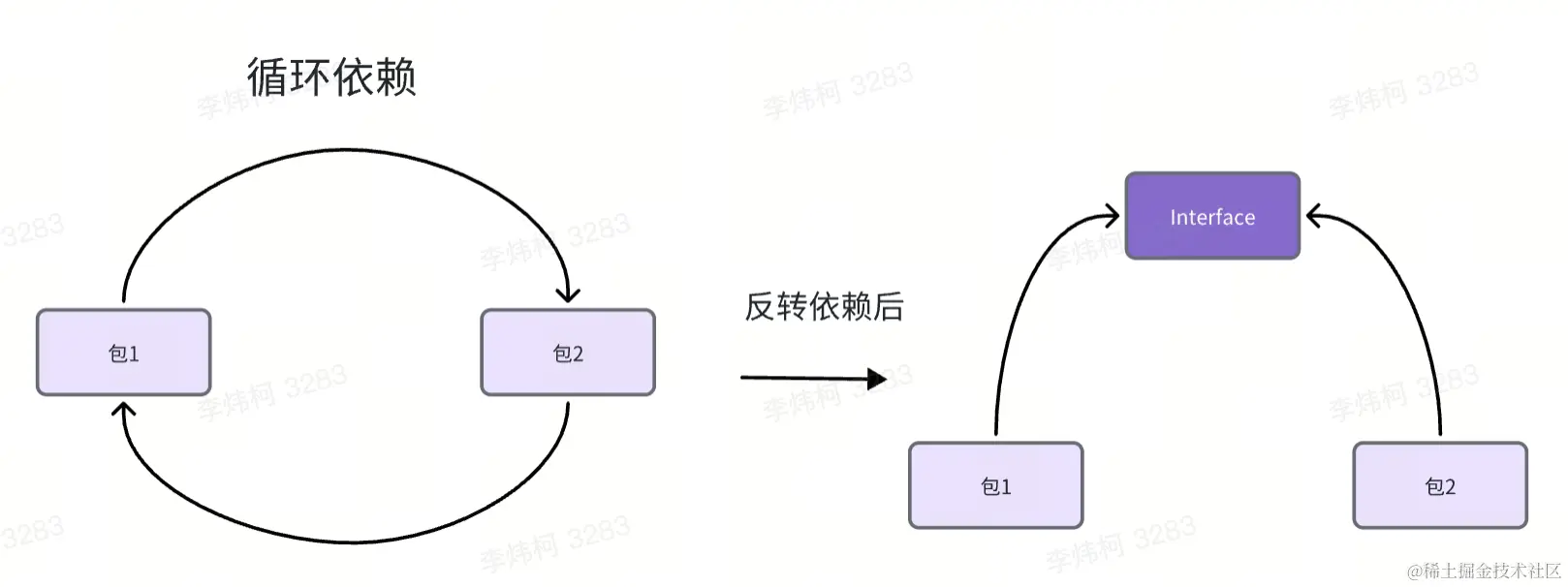

依赖倒置是解决循环依赖很常用的技巧,但是不是所有的循环依赖场景都适用依赖倒置来解决,我们通常会在架构设计或者通用能力接口的实现上使用到它,恰当的使用,可以降低代码耦合性,提高代码可读性和可维护性。
举例一个生活中的例子:
我们运营平台最常见的场景就是审核,在增信提额场景中,会先对用户提交的资料进行审核,再对用户提交的申请进行审核。目前,人审已经不满足我们诉求,我们需要提供一个自动审核的能力,在审核员完成对资料的审核后,自动触发自动审核完成对申请维度的审核。如下图:
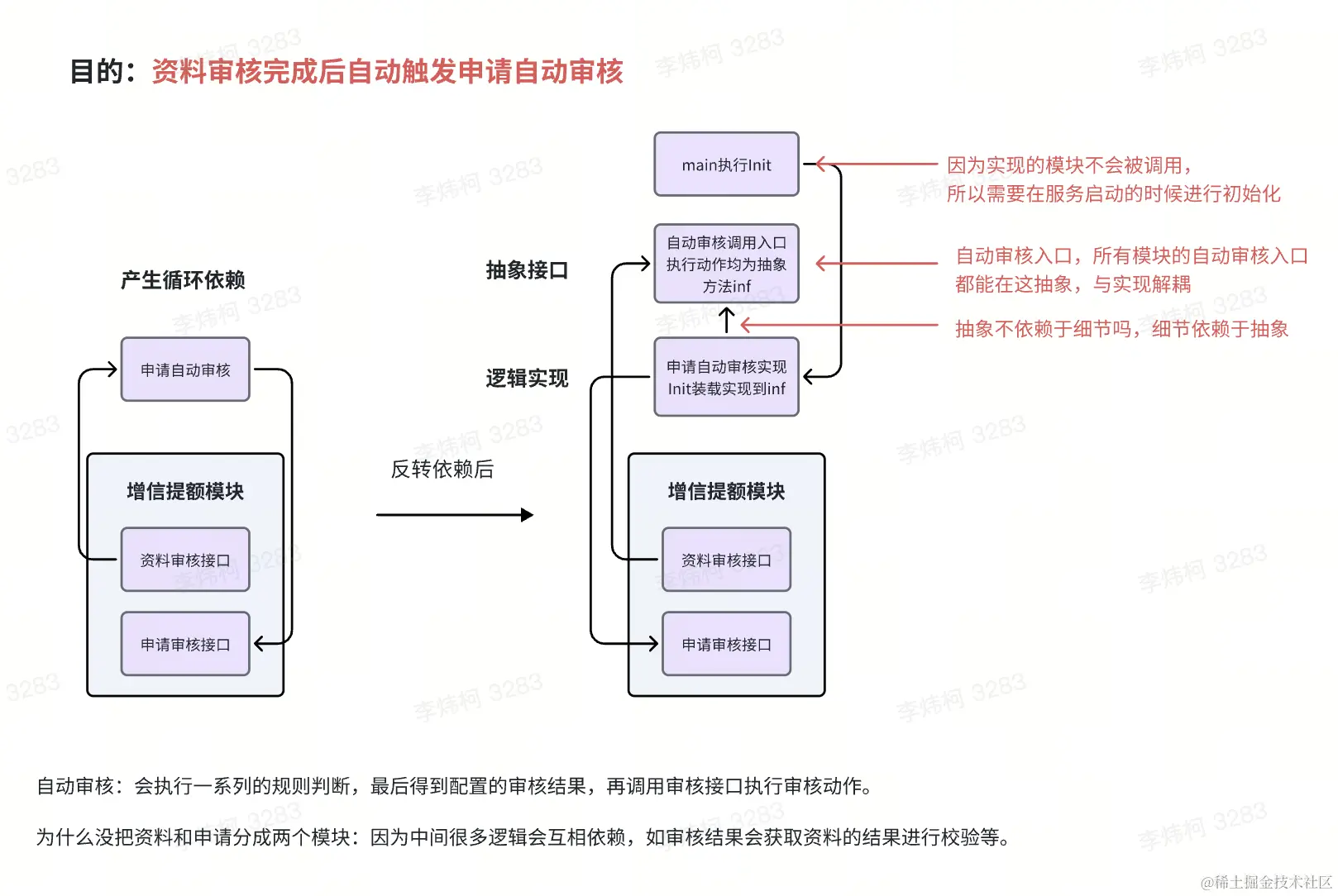
上图左边,如果我们单独的抽出一个文件夹作为自动审核模块,资料审核完成需要发起自动审核,自动审核需要执行申请审核,所以上面自动审核模块和增信提额模块就形成了循环依赖的关系。
当我们进行依赖反转后,就可以得到右图。将自动审核模块分成两个文件夹,一个是抽象接口,一个是逻辑实现。抽象接口不依赖于逻辑实现,所以自动审核入口不再依赖于增信提额模块中的申请审核。自动审核入口成为最底层模块,所有的模块都可以随意调用,一定不会产生循环依赖。对于资料审核完成执行申请审核场景下,资料审核是高层,自动审核实现逻辑是低层,他们都依赖于抽象。
这是一个很典型的通过依赖反转来实现提供一个通用能力的例子。除了基础设施层以外,我们所有实现的通用能力接口如果包含了业务逻辑,都应将其通过依赖反转来与实现解耦。可以彻底解决通用能力包导致的循环依赖问题。
分层架构中也经常会使用依赖反转来改变不同层之间的依赖关系以此达到改进的目的。如下面一种场景:

将基础设施层放到所有层最上方。其优点有:
基础设施层可以调用其他层所有的方法。
基础设施层可以直接使用领域层定义的实体等其他层的结构化信息。
事件驱动架构
事件驱动架构是一种松耦合、分布式的架构。可以通过mq来实现。
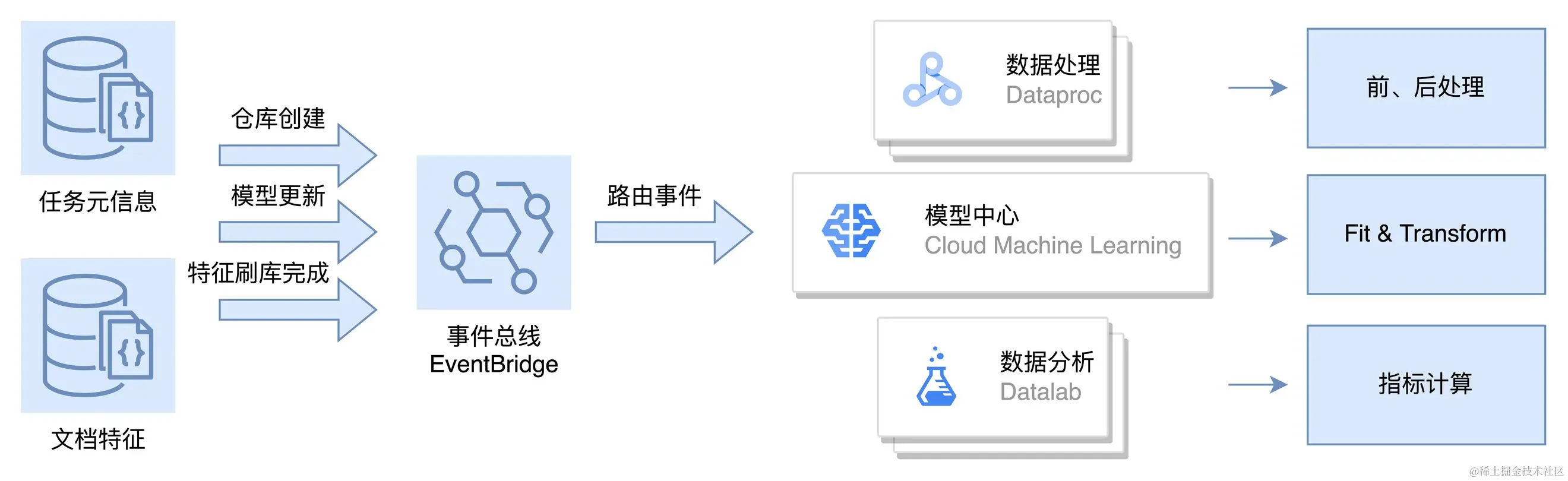
事件驱动架构体系结构具备以下三个能力:
事件收集:负责收集各种应用产生的数据变化,例如订单创建、退换货等状态变更。这些变化可以被用于监控业务流程、识别异常情况和触发警报等。
事件处理:对采集到的数据变化进行脱敏处理,并进行初步的过滤和筛选,以确保数据的准确性和可靠性。这有助于减少误报和漏报的风险,并为上层应用提供有价值的数据。
事件路由:根据数据变化的来源和性质,将事件路由分发至下游产品,以实现更高效的业务处理和分析。这可以帮助企业更好地了解自己的业务状况,并根据需要进行优化和改进。
举例:
同样是上面增信提额的例子,如果这个时候,放心借产品审核也需要进行自动审核了,那我们是否可以按如下架构进行调整。

我们将自动审核抽成一个独立服务,通过mq解耦自动审核回调业务系统的逻辑。至此即解决了循环依赖的问题,又对自动审核服务与业务系统进行了明确的划分。缺陷是:对于原流程改造成本大。
无论是依赖倒置还是事件驱动架构,都能解决以上循环依赖的问题,**没有最好的方案,只有最适用的方案。**依赖倒置适用于同步场景。而事件驱动架构适用于异步的场景。
丑陋的解决方式(不推荐 不推荐 不推荐)
通过go:linkname注释来避免导入包。
go:linkname是一个编译器指令(格式://go:linkname localname [importpath.name] ) 。这个特殊指令的作用域不是紧跟的下一行代码,而是在同一个包下生效。
//go:linkname 告诉Go的编译器本本地的变量或方法 localname 链接到指令的变量或方法 importpath.name 上go:linkname定义 。
这是go官方黑科技,官方也不建议使用。
结论:
遇到循环依赖不要慌。
先梳理出上下层模块,切记,上层不依赖于下层。
如果为同层模块,则考虑同层合并或者逻辑上移。
同步场景的通用接口考虑用依赖倒置原则,上层下层均依赖于抽象。
异步场景考虑用事件驱动模式。
永远不要考虑linkname解决。
以上就是go循环依赖的最佳解决方案的详细内容,更多关于go循环依赖解决的资料请关注脚本之家其它相关文章!