
Golang微服务框架Kratos实现Kafka消息队列的方法
作者:喵个咪
Golang微服务框架Kratos应用Kafka消息队列
消息队列是一种异步的服务间通信方式,适用于无服务器和微服务架构。消息在被处理和删除之前一直存储在队列上。每条消息仅可被一位用户处理一次。消息队列可被用于分离重量级处理、缓冲或批处理工作以及缓解高峰期工作负载。
消息队列是大型分布式系统不可缺少的中间件,也是高并发系统的基石中间件,所以掌握好消息队列MQ就变得极其重要。
在本文当中,您将了解到:什么是消息队列?什么是Kafka?怎样在微服务框架Kratos当中应用Kafka进行业务开发。
什么是消息队列
消息队列(Message Queue,简称MQ)指保存消息的一个容器,其实本质就是一个保存数据的队列。
消息中间件是指利用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的构建。
消息中间件是分布式系统中重要的组件,主要解决应用解耦,异步消息,流量削峰等问题,实现高性能,高可用,可伸缩和最终一致性的系统架构。目前使用较多的消息队列有:ActiveMQ、RabbitMQ、ZeroMQ、Kafka、MetaMQ、Kafka、NAQ、NATS、Pulsar等。
消息队列应用场景
消息中间件在互联网公司使用得越来越多,主要用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。以下介绍消息队列在实际应用中常用的使用场景:异步处理,应用解耦,流量削峰和消息通讯。
异步处理
通常的微服务实现的接口,都是通过RPC进行微服务、服务客户端之间的相互调用,这是同步阻塞执行。有一些业务,业务流程比较耗时且可以不需要立即返回结果,还有一些业务可以互不干扰的并行执行,那么我们就可以将之转为异步,并发执行。从而减少同步接口的请求响应时间,从而提高系统的吞吐量。

以下单为例,用户下单后需要实施:生成订单、赠送活动积分、赠送红包、发送下单成功通知等,一系列业务处理。假设三个业务节点每个使用100毫秒钟,不考虑网络等其他开销,则串行方式的时间是400毫秒,并行的时间只需要200毫秒。这样就大大提高了系统的吞吐量。
应用解耦
应用解耦,顾名思义就是解除应用系统之间的耦合依赖。通过消息队列,使得每个应用系统不必受其他系统影响,可以更独立自主。
以电商系统为例,用户下单后,订单系统需要通知积分系统。一般的做法是:订单系统直接调用积分系统的接口。这就使得应用系统间的耦合特别紧密。如果积分系统无法访问,则积分处理失败,从而导致订单失败。

加入消息队列之后,用户下单后,订单系统完成下单业务后,将消息写入消息队列,返回用户订单下单成功。积分系统通过订阅下单消息的方式获取下单通知消息,从而进行积分操作。实现订单系统与库存系统的应用解耦。如果,在下单时积分系统系统异常,也不影响用户正常下单,因为下单后,订单系统写入消息队列就不再关心其他的后续操作。
流量削峰
流量削峰也是消息队列中的常用场景,一般在秒杀或团抢活动中使用广泛。
以秒杀活动为例,一般会因为流量过大,导致流量暴增,应用挂掉。为解决这个问题,一般需要在应用前端加入消息队列,秒杀业务处理系统根据消息队列中的请求信息,再做后续处理。

如上图所示,服务器接收到用户的请求后,首先写入消息队列,秒杀业务处理系统根据消息队列中的请求信息,做后续业务处理。假如消息队列长度超过最大数量,则直接抛弃用户请求或跳转到错误页面。
消息通讯
消息通讯是指应用间的数据通信。消息队列一般都内置了高效的通信机制,因此也可以用在单纯的消息通讯上。比如:实现点对点消息队列,或者聊天室等点对点通讯。
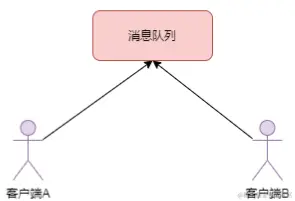
以上实际是消息队列的两种消息模式,点对点或发布订阅模式。
什么是 Apache Kafka?
Apache Kafka 是一个分布式数据流处理平台,可以实时发布、订阅、存储和处理数据流。它旨在处理多种来源的数据流,并将它们交付给多个消费者。简而言之,它可以移动大量数据,不仅是从 A 点移到 B 点,而是能从 A 到 Z 的多个点移到任何您想要的位置,并且可以同时进行。
Apache Kafka 可以取代传统的企业级消息传递系统。它最初是 Linkedin 为处理每天 1.4 万亿条消息而开发的一个内部系统,现已成为应用于各式各样企业需求的开源数据流处理解决方案。
Kafka 的工作原理
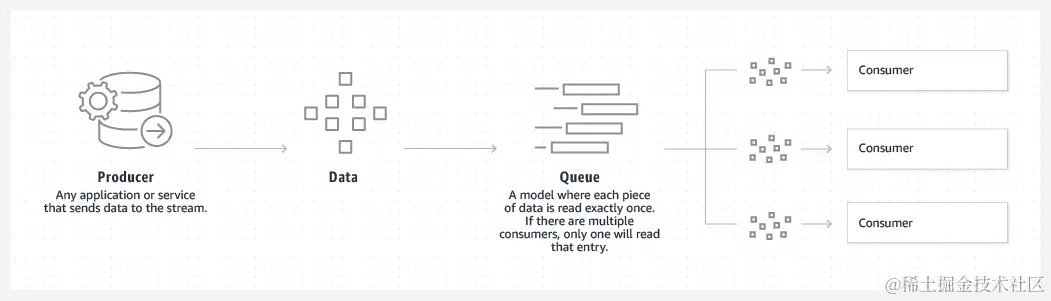
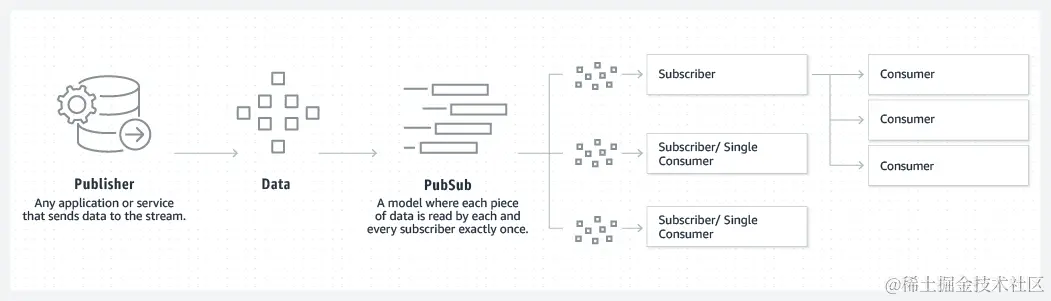
Kafka 结合了两种消息收发模型、列队和发布-订阅,以向客户提供其各自的主要优势。通过列队可以跨多个使用器实例分发数据处理,因此具有很高的可扩展性。但是,传统队列不支持多订阅者。发布-订阅方法支持多订阅者,但是由于每条消息传送给每个订阅者,因此无法用于跨多个工作进程发布工作。Kafka uses 使用分区日志模型将这两种解决方案融合在一起。日志是一种有序的记录,这些日志分成区段或分区,分别对应不同的订阅者。这意味着,同一个主题可有多个订阅者,分别有各自的分区以获得更高的可扩展性。最后,Kafka 的模型带来可重放性,允许多个相互独立的应用程序从数据流执行读取以便按自己的速率独立地工作。
列队
发布-订阅
Kafka的基本概念
kafka运行在集群上,集群包含一个或多个服务器。kafka把消息存在topic中,每一条消息包含键值(key),值(value)和时间戳(timestamp)。
kafka有以下一些基本概念:
Producer - 消息生产者,就是向kafka broker发消息的客户端。
Consumer - 消息消费者,是消息的使用方,负责消费Kafka服务器上的消息。
Topic - 主题,由用户定义并配置在Kafka服务器,用于建立Producer和Consumer之间的订阅关系。生产者发送消息到指定的Topic下,消息者从这个Topic下消费消息。
Partition - 消息分区,一个topic可以分为多个 partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。
Broker - 一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
Consumer Group - 消费者分组,用于归组同类消费者。每个consumer属于一个特定的consumer group,多个消费者可以共同消息一个Topic下的消息,每个消费者消费其中的部分消息,这些消费者就组成了一个分组,拥有同一个分组名称,通常也被称为消费者集群。
Offset - 消息在partition中的偏移量。每一条消息在partition都有唯一的偏移量,消息者可以指定偏移量来指定要消费的消息。
Docker部署开发环境
docker pull bitnami/zookeeper:latest
docker pull bitnami/kafka:latest
docker run -itd \
--name zookeeper-test \
-p 2181:2181 \
-e ALLOW_ANONYMOUS_LOGIN=yes \
bitnami/zookeeper:latest
docker run -itd \
--name kafka-standalone \
--link zookeeper-test \
-p 9092:9092 \
-v /home/data/kafka:/bitnami/kafka \
-e KAFKA_BROKER_ID=1 \
-e KAFKA_LISTENERS=PLAINTEXT://:9092 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9092 \
-e KAFKA_ZOOKEEPER_CONNECT=zookeeper-test:2181 \
-e ALLOW_PLAINTEXT_LISTENER=yes \
--user root \
bitnami/kafka:latest管理工具
Kratos下如何应用Kafka?
我对Kafka做了一个封装,要在Kratos下面使用Kafka,首先需要在项目中引用我封装的两个库:
第一个库可以视之为Kafka客户端的一个封装:
go get -u github.com/tx7do/kratos-transport/broker/kafka
这一个库是讲Kafka的客户端封装成一个Kratos的transport.Server,该库依赖上面的库:
go get -u github.com/tx7do/kratos-transport/transport/kafka
想要在Kratos里面应用Kafka,有两条途径可以达成:
- 在
Data层引用Kafka的Broker,仅用于发布(Publish)消息之用,换言之,就是只发送不接收的单向通讯; - 在
Server层引用Kafka的Server,可以发布(Publish)消息,也可以订阅(Subscribe)消息,换言之,就是既发送又接收的全双工通讯。
接下来我就详细的讲解应用方法:
在Data层引用Kafka的Broker
首先创建Kafka的Broker:
import (
"github.com/tx7do/kratos-transport/broker"
"github.com/tx7do/kratos-transport/broker/kafka"
)
func NewKafkaBroker(cfg *conf.Bootstrap) broker.Broker {
b := kafka.NewBroker(
broker.WithAddress(cfg.Data.Kafka.Addrs...),
broker.WithCodec(cfg.Data.Kafka.Codec),
)
if b == nil {
return nil
}
_ = b.Init()
if err := b.Connect(); err != nil {
return nil
}
return b
}然后,注入到Wire的ProviderSet:
package data
import "github.com/google/wire"
// ProviderSet is data providers.
var ProviderSet = wire.NewSet(
...
NewKafkaBroker,
)最后,我们就可以在Service里面调用了:
package service
type ReportService struct {
v1.ReportServiceHTTPServer
kafkaBroker broker.Broker
log *log.Helper
}
func NewReportService(logger log.Logger, kafkaBroker broker.Broker) *ReportService {
l := log.NewHelper(log.With(logger, "module", "report/service/agent-service"))
return &ReportService{
log: l,
kafkaBroker: kafkaBroker,
}
}
func (s *ReportService) PostReport(_ context.Context, req *v1.PostReportRequest) (*v1.PostReportResponse, error) {
_ = s.kafkaBroker.Publish(topic.EventReportData, reportV1.RealTimeWarehousingData{
EventName: &req.EventName,
ReportData: &req.Content,
CreateTime: util.UnixMilliToStringPtr(trans.Int64(time.Now().UnixMilli())),
})
return &v1.PostReportResponse{
Code: 0,
Msg: "success",
}, nil
}需要注意的是,添加了以上代码之后,需要使用命令生成Wire的胶水代码:
go run -mod=mod github.com/google/wire/cmd/wire ./cmd/server
在Server层引用Kafka的Server
首先要创建Server:
package server
import (
...
"github.com/tx7do/kratos-transport/transport/kafka"
)
// NewKafkaServer create a kafka server.
func NewKafkaServer(cfg *conf.Bootstrap, _ log.Logger, svc *service.SaverService) *kafka.Server {
ctx := context.Background()
srv := kafka.NewServer(
kafka.WithAddress(cfg.Server.Kafka.Addrs),
kafka.WithGlobalTracerProvider(),
kafka.WithGlobalPropagator(),
kafka.WithCodec("json"),
)
registerKafkaSubscribers(ctx, srv, svc)
return srv
}
func registerKafkaSubscribers(ctx context.Context, srv *kafka.Server, svc *service.SaverService) {
_ = kafka.RegisterSubscriber(srv, ctx,
topic.UserReportData, topic.LoggerSaverQueue, false,
svc.SaveUserReport,
)
_ = kafka.RegisterSubscriber(srv, ctx,
topic.EventReportData, topic.LoggerSaverQueue, false,
svc.SaveEventReport,
)
}接着,调用kratos.Server把Kafka的服务器注册到Kratos里去:
func newApp(ll log.Logger, rr registry.Registrar, ks *kafka.Server) *kratos.App {
return kratos.New(
kratos.ID(Service.GetInstanceId()),
kratos.Name(Service.Name),
kratos.Version(Service.Version),
kratos.Metadata(Service.Metadata),
kratos.Logger(ll),
kratos.Server(
ks,
),
kratos.Registrar(rr),
)
}最后,我们就可以在Service里愉快的玩耍了,在这里,我只演示收到Kafka消息之后立即写入数据库的操作:
package service
type SaverService struct {
log *log.Helper
statusRepo *data.AcceptStatusRepo
realtimeRepo *data.RealtimeWarehousingRepo
}
func NewSaverService(
logger log.Logger,
statusRepo *data.AcceptStatusRepo,
realtimeRepo *data.RealtimeWarehousingRepo,
) *SaverService {
l := log.NewHelper(log.With(logger, "module", "saver/service/logger-service"))
return &SaverService{
log: l,
statusRepo: statusRepo,
realtimeRepo: realtimeRepo,
}
}
func (s *SaverService) SaveUserReport(_ context.Context, _ string, _ broker.Headers, msg *v1.AcceptStatusReportData) error {
return s.statusRepo.Create(msg)
}
func (s *SaverService) SaveEventReport(_ context.Context, _ string, _ broker.Headers, msg *v1.RealTimeWarehousingData) error {
return s.realtimeRepo.Create(msg)
}实例代码
以上代码以及接口定义,可以在我的另外一个开源项目里面找到:
https://github.com/tx7do/kratos-uba
https://gitee.com/tx7do/kratos-uba
以上就是Golang微服务框架Kratos实现Kafka消息队列的方法的详细内容,更多关于Golang Kafka消息队列的资料请关注脚本之家其它相关文章!