
深入了解Go语言编译链接的过程
作者:小许code
1 前言
interface、channel的文章中经常会提到,Go在编译时会将interface和channel关键字转换成runtime中的结构和函数调用。所以我觉得很有必要就Go的编译过程理一理做个进行总结,然后结合之前对底层原理总结的文章,那么对整个逻辑会更加清晰。我也是查了各种资料,尽量把整个过程能总起出一些东西来,学习嘛,总是需要不断总结,分享!
1.1 什么是ASCII字符
ASCII 代表美国信息交换标准代码,用于电子通信。在计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从00000000到11111111。 上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定,这被称为 ASCII 码,一直沿用至今。
它使用整数对数字(0-9)、大写字母(AZ)、小写字母(az)和分号(;)、感叹号(!)等符号进行编码。整数比字母或字母更容易存储在电子设备中符号。例如,97用于表示“a”,33用于表示“!” 并且可以很容易地存储在内存中。
我们知道Go是采用UTF-8是编码规则, 和ASCII码之间的联系呢?了解UTF-8之前我们先了解Unicode,因为ASCII码只能表示英语,不能表示其他语言。Unicode 为世界上所有字符都分配了一个唯一的数字编号,但是Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
因为互联网的普及,UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。Unicode的编码规则,对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码,因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
对于ASCII码、Unicode、UTF-8之间的联系就不展开更多更细的总结,用个栗子来说明下我们编写的Go程序文件和编码之间关系。
1.2 图说ASCII码和Go程序文件
这里参考下一个网络上的图片说明,首先我们Go代码Hello.go如下
package main
import "fmt"
func main() {
fmt.Println("hello world")
}我们知道我们用心敲下的每一行代码都是字节序列,然后每个字节代表一个字符,代码和ASCII码之间的对应关系就是中间一列代表文本对应的 ASCII 字符,最右边的列就是我们的代码,跟下面的对照表示一一对应的,比如hello.go文件的首字母p的值是对应的就是70。

16进制查看文件内容
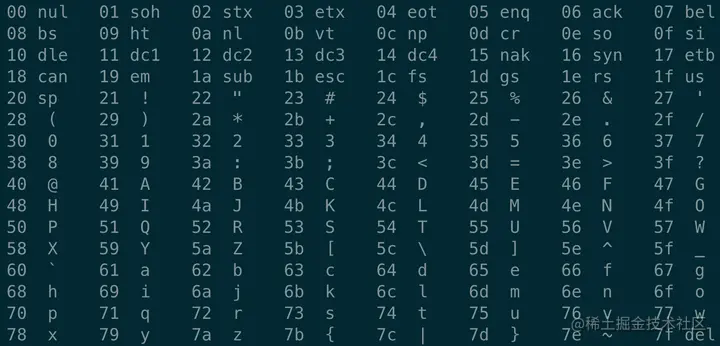
ASCII码对照表
hello.go 文件都是由 ASCII 字符表示的,它被称为文本文件,8个bit看成一个单位,假定源程序都是ASCII码,转换为我们人类都能更好理解的go程序,那么到这里编码和程序文件之间的关系已经清楚了,接下来就从编译和链接过程来看有哪些步骤,然后每一个步骤做了什么!
2 编译过程
我们知道Go 程序并不能直接运行,每条 Go 语句必须转化为一系列的低级机器语言指令,将这些指令打包到一起,并以二进制磁盘文件的形式存储起来,也就是可执行目标文件。这个过程就涉及到对源文件进行词法分析、语法分析、语义分析、优化,最后生成汇编代码文件(以.s作为文件后缀),再经过汇编器将汇编文件生成.o二进制程序,最后经过链接器转换成可执行的目标程序(比如windows下的.exe程序)。
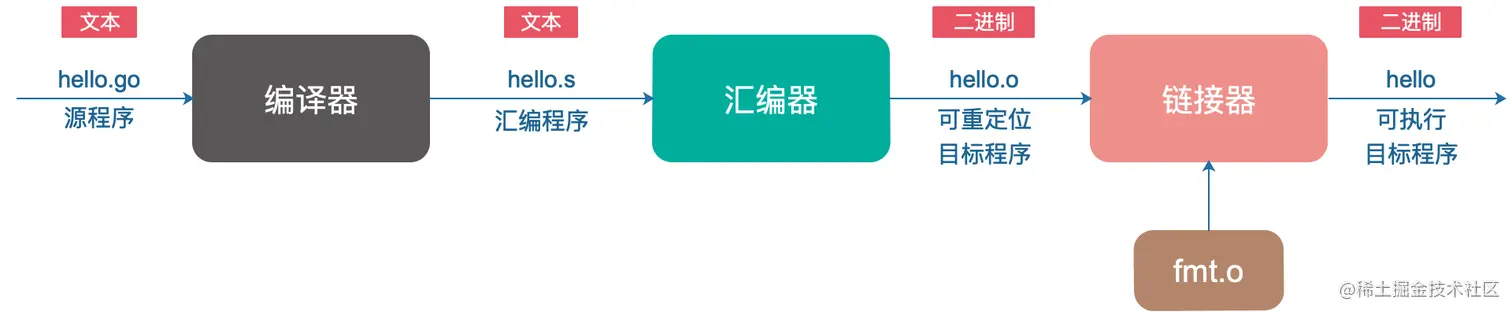
源文件编译为执行程序的过程
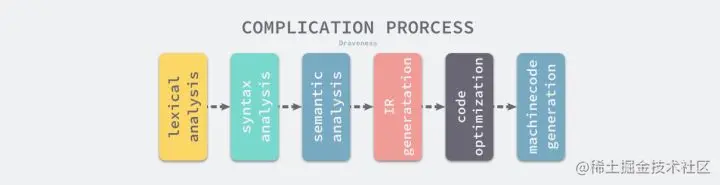
编译过程
2.1 词法分析
词法分析(lexical analysis)维基百科上给出的定义:是计算机科学中将字符序列转换为标记(token)序列的过程。进行词法分析的程序或者函数叫作词法分析器(lexical analyzer,简称lexer),也叫扫描器(scanner)。词法分析器一般以函数的形式存在,供语法分析器调。
Go在编译源码时首先,由词法分析器(lexer)对源代码文件进行解析,将文件中的字符串序列转为Token序列(在src/cmd/compile/internal/syntax/tokens.go),token包含标识符、关键字、特殊符号等都是以常量的形式存在。
const ( _ token = iota _EOF // EOF // names and literals _Name // name _Literal // literal // operators and operations // _Operator is excluding '*' (_Star) _Operator // op _AssignOp // op= _IncOp // opop _Assign // = _Define // := _Arrow // <- _Star // *
而扫描代码在(src/cmd/compile/internal/syntax/scanner.go),通过核心的next()函数,不断读取下一个函数,然后通过一个大的switch-case来匹配比如换行、字符串、括号等标识符将其转换为token,从而完成一次解析。
func (s *scanner) next() {
for s.ch == ' ' || s.ch == '\t' || s.ch == '\n' && !nlsemi || s.ch == '\r' {
s.nextch()
}
...
switch s.ch {
case -1:
if nlsemi {
s.lit = "EOF"
s.tok = _Semi
break
}
s.tok = _EOF
case '\n':
s.nextch()
s.lit = "newline"
s.tok = _Semi
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9':
s.number(false)
case '"':
s.stdString()
case '`':
s.rawString()
...
}2.2 语法分析
语法分析的输入是词法分析器输出的 Token 序列,语法分析器会按照顺序解析 Token 序列,该过程会将词法分析生成的 Token 按照编程语言定义好的文法(Grammar)自下而上或者自上而下的规约,
转换成有意义的结构体,即抽象语法树(AST【Abstract syntax tree】)。每一个 Go 的源代码文件最终会被解析成一个独立的抽象语法树归纳成一个source file结构(语法树最顶层的结构或者开始符号都是 SourceFile)
SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .词法分析会返回一个不包含空格、换行等字符的 Token 序列,例如:package, json, import, (, io, ), …,而语法分析会把 Token 序列转换成有意义的结构体,即语法树
"json.go": SourceFile {
PackageName: "json",
ImportDecl: []Import{
"io",
},
TopLevelDecl: ...
}2.3 类型检查
经过词法分析构建成抽象语法树之后,下一步就是类型检查,类型检查会对抽象语法树中定义和使用的类型进行检查,会按照以下步骤处理和验证不同语法树的节点。Go语言的编译器同时使用静态类型检查和动态类型检查,这里只讨论静态类型检查。
- 常量、类型和函数名及类型;
- 变量的赋值和初始化;
- 函数和闭包的主体;
- 哈希键值对的类型;
- 导入函数体
- 外部的声明
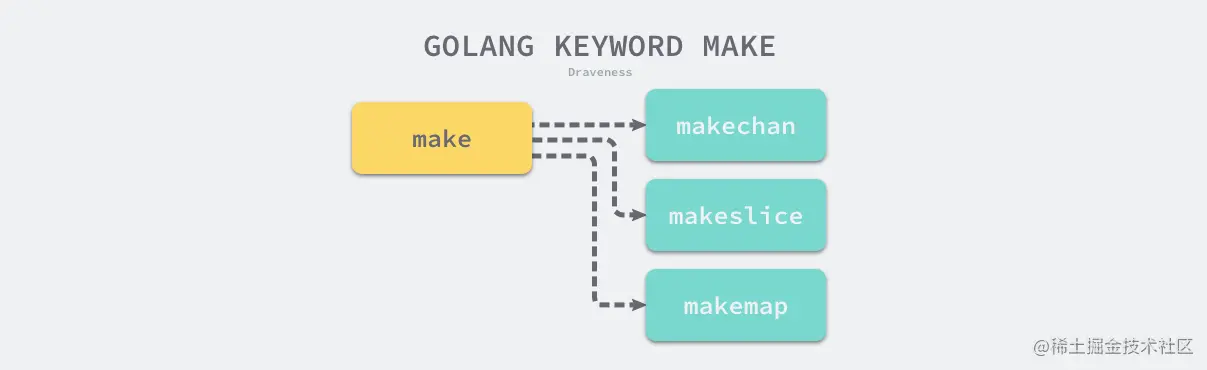
通过对类型的验证,保证节点不存在类型错误,包括:结构体对接口的实现。类型检查阶段不止会对节点的类型进行验证,还会展开和改写一些内建的函数,例如 make 关键字在这个阶段会根据子树的结构被替换成 runtime.makeslice 或者 runtime.makechan 等函数
类型检查-修改关键字节点操作类型
注:此过程中也可能改写AST,包括去除一些不会被执行的代码,优化代码以提高执行效率,而且会修改make、new等关键字对应节点的操作类型
2.4 中间代码生成
经过对抽象语法树的类型检查后,可以认为当前代码不存在类型和语法上的错误了,接下来Go编译器会将抽象语法树转为中间代码。中间代码是编译器或者虚拟机使用的语言,它可以来帮助我们分析计算机程序。在编译过程中,编译器会在将源代码转换到机器码的过程中,先把源代码转换成一种中间的表示形式。
源代码-》中间代码-》机器码
中间代码生成分为三步:配置初始化、遍历和替换、SSA生成
2.4.1 配置初始化
- 缓存类型信息
- 根据当前的 CPU 架构初始化 SSA 配置
- 初始化一些编译器可能用到的 Go 语言运行时的函数
2.4.2 遍历和替换
在生成中间代码之前,编译器还需要替换抽象语法树中节点的一些元素,这个替换的过程是通过cmd/compile/internal/gc.wal和以相关函数实现的。
这些用于遍历抽象语法树的函数会将一些关键字和内建函数转换成函数调用,例如: 上述函数会将panic、recover两个内建函数转换成runtime.gopanic和runtime.gorecover两个真正运行时函数,而关键字new也会被转换成调用runtime.newobject函数。

关键字或内建函数到运行时函数的映射
这些映射关系都在src/cmd/compile/internal/gc/builtin/runtime.go,包括channel、make、new、select等关键字或内建函数,但是这里只有声明。
func makemap64(mapType *byte, hint int64, mapbuf *any) (hmap map[any]any) func makemap(mapType *byte, hint int, mapbuf *any) (hmap map[any]any)
函数的实现是在src/runtime运行时包下面,比如对应channel的转换后的实际实现在src/runtime/chan.go文件
2.4.3 SSA(静态单赋值)生成
经过 walk 系列函数的处理之后,抽象语法树就不会改变了,Go 语言的编译器会使用 cmd/compile/internal/gc.compileSSA 函数将抽象语法树转换成中间代码
func compileSSA(fn *Node, worker int) {
f := buildssa(fn, worker)
pp := newProgs(fn, worker)
genssa(f, pp)
pp.Flush()
}cmd/compile/internal/gc.buildssa负责生成具有 SSA 特性的中间代码,我们可以使用命令行工具来观察中间代码的生成过程,假设我们有以下的 Go 语言源代码,其中只包含一个简单的hello函数:
package hello
func hello(a int) int {
c := a + 2
return c
}上述文件中包含源代码对应的抽象语法树、几十个版本的中间代码以及最终生成的 SSA
2.5 机器码生成
Go 语言编译的最后一个阶段是根据 SSA 中间代码生成机器码,这里谈的机器码是在目标 CPU 架构上能够运行的二进制代码。机器码的生成实际上是对SSA的降级过程,在 SSA 中间代码降级的过程中,编译器将一些值重写成了目标 CPU 架构的特定值,降级的过程处理了所有机器特定的重写规则并对代码进行了一定程度的优化。执行架构特定的优化和重写并生成指令,经由汇编器将这些指令转换为机器码。具体的底层原理就很复杂了,我也不清楚,了解个过程就行了。
就源码编译为汇编指令举个栗子:
$ cat hello.go
package hello
func hello(a int) int {
c := a + 2
return c
}
$ GOOS=linux GOARCH=amd64 go tool compile -S hello.go
"".hello STEXT nosplit size=15 args=0x10 locals=0x0
0x0000 00000 (hello.go:30) TEXT "".hello(SB), NOSPLIT|ABIInternal, $0-16
0x0000 00000 (hello.go:30) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (hello.go:30) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (hello.go:31) MOVQ "".a+8(SP), AX
0x0005 00005 (hello.go:31) ADDQ $2, AX
0x0009 00009 (hello.go:32) MOVQ AX, "".~r1+16(SP)
0x000e 00014 (hello.go:32) RET
0x0000 48 8b 44 24 08 48 83 c0 02 48 89 44 24 10 c3 H.D$.H...H.D$..
...3 链接过程
编译过程其实是对单个文件进行的,而链接过程将编译过程生成的一个个目标文件链接成最终的可执行程序,最终得到的文件是分成各种段的,比如数据段、代码段、BSS段等等,运行时会被装载到内存中。各个段具有不同的读写、执行属性,保护了程序的安全运行。比如Hello.go编译后会生成一个hello.a二进制代码文件,然后结合其他库和基础库,在windows下生成一个exe程序。
以上就是深入了解Go语言编译链接的过程的详细内容,更多关于Go语言编译链接的资料请关注脚本之家其它相关文章!