
如何使用JavaScript获取word的内容
作者:mob64ca12f63d4f
一、流程概述
在这个过程中,我们将通过以下步骤获取Word文件的文字内容。操作需要使用到FileReader对象以及库如mammoth.js。以下是详细的步骤流程表:
| 步骤 | 描述 |
| 1 | 引入必要的库 |
| 2 | 创建文件选择器 |
| 3 | 添加文件选择事件监听器 |
| 4 | 使用FileReader读取文件内容 |
| 5 | 处理读取的内容并输出 |
二、步骤详解
1. 引入必要的库
首先,确保你在HTML文件中引入mammoth.js库。这个库能够帮助我们从Word文件中提取文本。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Word文件读取</title>
<script src="
</head>
<body>
<!-- 这里后面会添加其他HTML元素 -->
</body>
</html>
注释:引入mammoth.js库,以便后续提取Word文件内容。
2. 创建文件选择器
接下来,我们需要一个文件选择器来让用户选择他们的Word文件。
<input type="file" id="upload" accept=".docx"/> <div id="output"></div>
注释:<input>标签用于文件上传,accept属性限制用户只能选择.docx文件。
3. 添加文件选择事件监听器
我们需要监听用户在文件选择器中的操作:
document.getElementById('upload').addEventListener('change', function(event) {
var file = event.target.files[0]; // 获取用户选择的文件
if (file) {
var reader = new FileReader(); // 创建文件读取对象
reader.onload = function(e) {
var arrayBuffer = e.target.result; // 获取文件内容
mammoth.extractRawText({ arrayBuffer: arrayBuffer })
.then(displayResult) // 提取文本并显示
.catch(handleError); // 错误处理
};
reader.readAsArrayBuffer(file); // 读取文件为字节流
}
});
注释:
addEventListener:监听change事件,当用户选择文件时触发。
FileReader():JavaScript提供的用于读取文件的API。
reader.onload:读取完成后调用的函数。
mammoth.extractRawText:提取Word文件文本的方法。
4. 处理读取的内容并输出
定义displayResult和handleError函数,通过它们来显示结果和处理错误。
function displayResult(result) {
document.getElementById('output').innerText = result.value; // 显示提取的文本
}
function handleError(err) {
console.error('Error: ', err); // 输出错误信息
}
注释:
displayResult:该函数将提取的文本显示在output的<div>元素中。
handleError:用于输出读取过程中可能发生的错误到控制台。
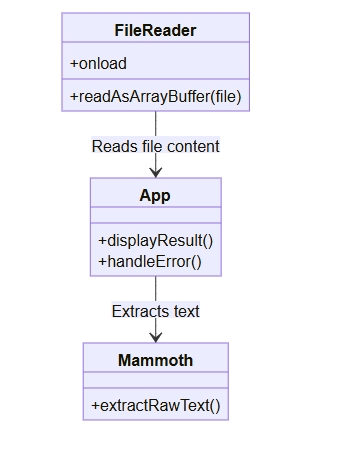
类图
使用Mermaid语法可以绘制如下一张类图,展示代码组件之间的关系。
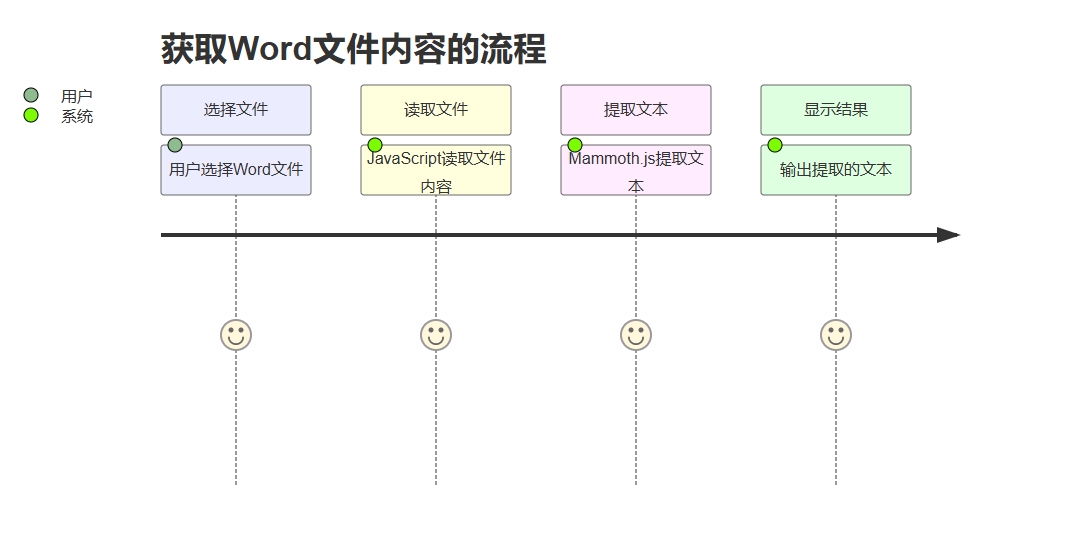
旅行图
通过Mermaid语法的旅行图,可以清晰了解我们实现上述功能的过程。
三、小结
通过以上步骤,我们成功地运用JavaScript从Word文件中提取了文字内容。这种技巧在需要处理用户上传文档内容的场景中非常有用,例如在线文档编辑、内容管理系统等。学习并掌握这一技能,将极大提高你的前端开发能力。
四、方法补充
除了上文的方法,小编为大家整理了其他JavaScript获取word内容的方法,希望对大家有所帮助
示例代码
把docx文件中表格转化为json二维数组
import { convertToHtml } from "mammoth"
import { JSDOM } from "jsdom"
convertToHtml({ path: "./test.docx" })
.then(function (result) {
const html = result.value // The generated HTML
const messages = result.messages // 转化时的一些warning信息
console.log(messages)
const table_data: string[][] = []
// 使用 JSDOM 加载 HTML 内容
const dom = new JSDOM(html)
const document = dom.window.document
// 获取表格中的所有 <tr> 元素
const tableRows = document.querySelectorAll("table tr")
// 遍历 <tr> 元素
tableRows.forEach((row, index) => {
const row_data: string[] = []
// 获取当前行中的所有 <td> 元素
const cells = row.querySelectorAll("td")
// 遍历 <td> 元素
cells.forEach((cell, cellIndex) => {
row_data.push(cell.textContent ?? "")
})
table_data.push(row_data)
})
console.log("Table结果", table_data)
})
.catch(function (error) {
console.error(error)
})代码解释
mammoth将word转化为htmljsdom不在浏览器中时,用来解析html的dom结构
到此这篇关于如何使用JavaScript获取word的内容的文章就介绍到这了,更多相关JavaScript获取word内容内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!