
Nodejs本地部署DeepSeek的教程详解
作者:海上彼尚
DeepSeek作为一款开源且性能强大的大语言模型,提供了灵活的本地部署方案,让用户能够在本地环境中高效运行模型,同时保护数据隐私,本文主要为大家详细介绍了Nodejs本地部署DeepSeek的相关知识,需要的可以了解下
1.下载 Ollama
下载之后点击安装,等待安装成功后,打开cmd窗口,输入以下指令:
ollama -v
如果显示了版本号,则代表已经下载成功了。
2.下载DeepSeek模型
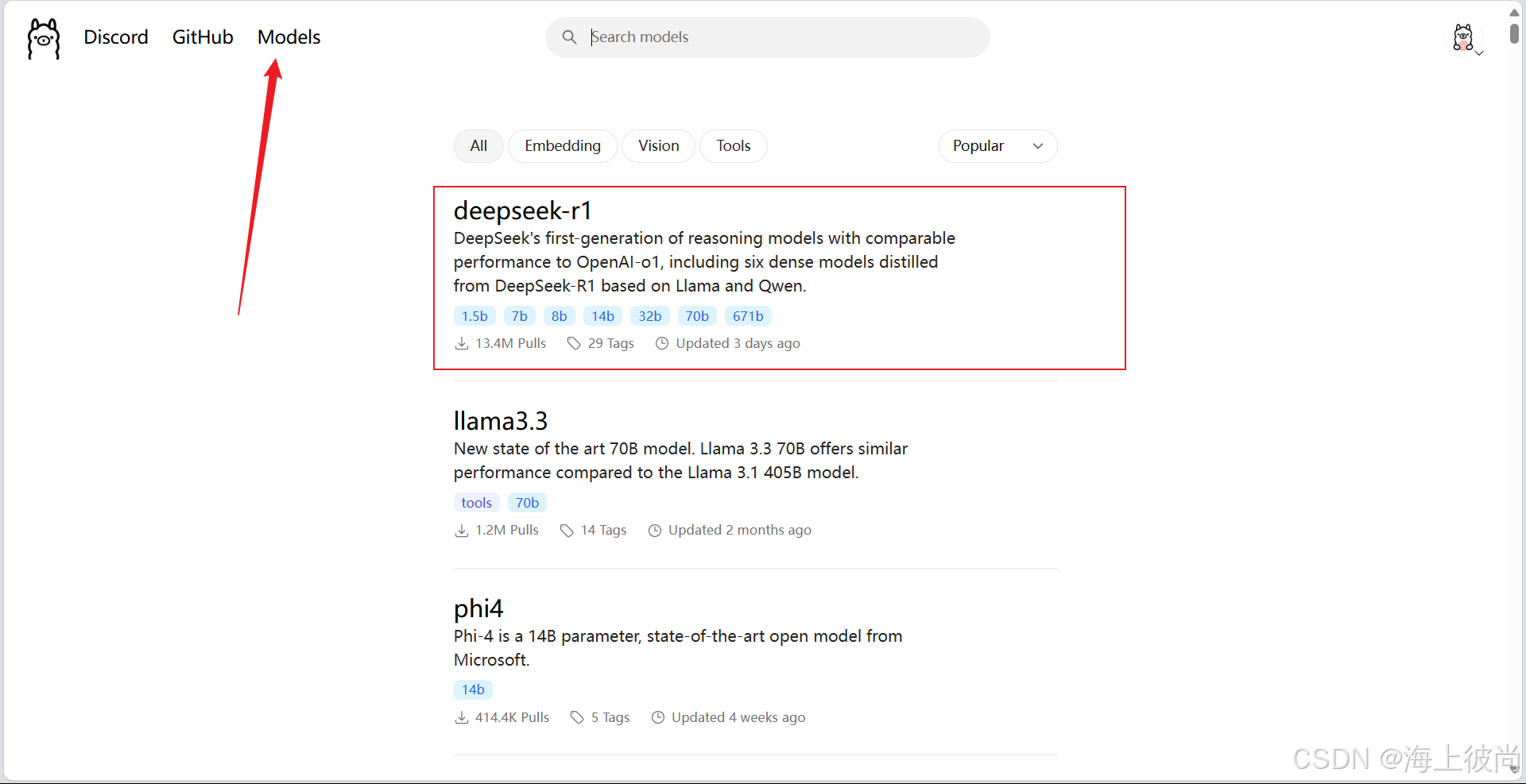
然后选择自己对应配置的模型,在复制右侧指令到cmd窗口,就可以把模型下载到本地了。
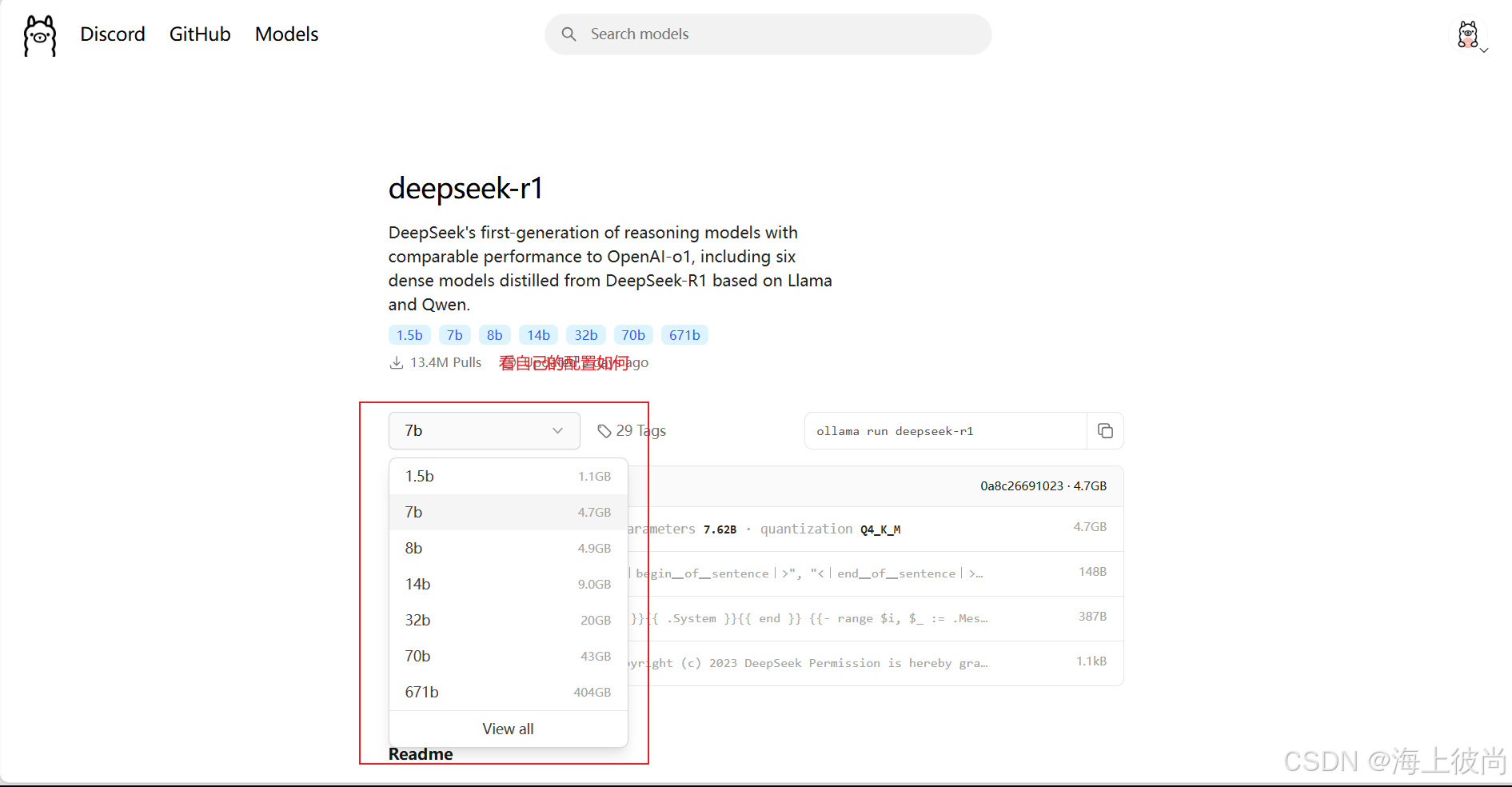
3.下载 ollama.js
npm下载方式:
npm i ollama
yarn下载方式:
yarn add ollama
pnpm下载方式:
pnpm i ollama
下载完成后,按照ollama.js 官方文档指示则可使用,下面是一个最简单的案例:
import { Ollama } from 'ollama'
const ollama = new Ollama({
host: 'http://127.0.0.1:11434'
})
const response = await ollama.chat({
model: 'deepseek-r1:1.5b',
messages: [{ role: 'user', content: '你好' }],
})
console.log(response.message.content)输出结果:
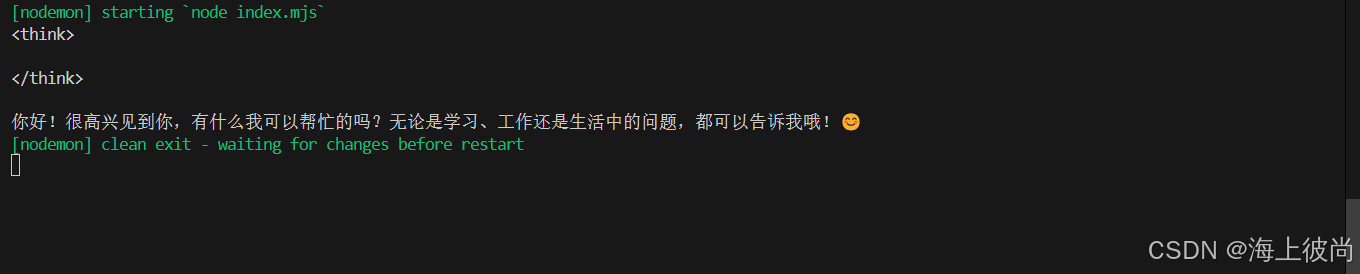
最后,如果大家不熟悉 Ollama 的指令,可以参考下文
4.ollama基本使用教程
Ollama 是一个开源的大型语言模型服务工具,能够帮助用户在本地运行大模型。通过简单的安装指令,用户可以在本地运行开源的大型语言模型,如 Llama 21。
1. 安装 Ollama
支持 macOS、Linux 和 Windows(通过 WSL)。
macOS 或 Linux
# 一键安装脚本 curl -fsSL https://ollama.com/install.sh | sh
Windows (WSL2)
安装 WSL2 和 Ubuntu。
在 WSL 终端中运行上述安装脚本。
2. 基础命令
启动与停止
# 启动 Ollama 服务(后台运行) ollama serve # 停止服务 ollama stop
更新 Ollama
ollama upgrade
3. 模型管理
下载预训练模型
# 下载官方模型(如 llama2、mistral) ollama pull <model-name> # 示例 ollama pull llama2
运行模型
# 启动交互式对话 ollama run <model-name> # 示例 ollama run llama2
查看已安装模型
ollama list
删除模型
ollama rm <model-name>
从 Modelfile 创建自定义模型
创建一个 Modelfile 文件:
FROM llama2 # 基础模型 SYSTEM """你是一个友好的助手,用中文回答。""" PARAMETER temperature 0.7 # 控制生成随机性(0-1)
构建自定义模型:
ollama create my-model -f Modelfile
运行自定义模型:
ollama run my-model
4. 高级功能
服务器模式与 API
启动 API 服务(默认端口 11434):
ollama serve
通过 HTTP 调用 API:
curl http://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt": "你好,请介绍一下你自己",
"stream": false
}'
多会话管理
# 启动一个会话并命名 ollama run llama2 --name chat1 # 在另一个终端启动新会话 ollama run llama2 --name chat2
环境变量配置
# 更改默认端口 OLLAMA_HOST=0.0.0.0:8080 ollama serve # 使用 GPU 加速(需 NVIDIA 驱动) OLLAMA_GPU_METAL=1 ollama run llama2
5. 常见问题与技巧
加速模型下载
# 使用镜像源(如中国用户) OLLAMA_MODELS=https://mirror.example.com ollama pull llama2
查看日志
tail -f ~/.ollama/logs/server.log
模型参数调整
在 Modelfile 中可设置:
- temperature: 生成随机性(0=确定,1=随机)
- num_ctx: 上下文长度(默认 2048)
- num_gpu: 使用的 GPU 数量
模型导出与分享
# 导出模型 ollama export my-model > my-model.tar # 导入模型 ollama import my-model.tar
到此这篇关于Nodejs本地部署DeepSeek的教程详解的文章就介绍到这了,更多相关Nodejs本地部署DeepSeek内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!