
NVIDIA RTX 3080显卡怎么样 NVIDIA RTX 3080显卡详细评测
曲楠
在9月2日的发布会中,黄仁勋先生不止一次强调了“这是有史以来最伟大性能提升”。而从发布会展示的效果来看,RTX 30系显卡用双倍加量不加价来形容都不为过。并且第二代RTX的Ampere架构所带来最直接的变化就是在性能方面暴涨,所以发布会前的种种烟雾弹也就显而易见了,下面笔者就给大家带来NVIDIA GeForce RTX 3080的首发评测。
01 NVIDIA GeForce RTX 3080 外观
下面我们先来看看这次NVIDIA RTX 3080 显卡的外观,首先在外包装上,一向是NV的极简风格,方方正正的硬纸盒子,主色调以黑色为主,辅以玫瑰金色纹路,而这次NVIDIA也罕见的没有用绿色,整体看起来有点像Tesla V100。

外包装与显卡
入手显卡之后,给人的第一感觉就是质感极强,堪称工业设计典范。在发布会当中我们也看到此次的RTX 30系显卡在外观方面做了极大改变,卡身大面积被散热鳍片覆盖。
而在拿到显卡后,我居然发现所有散热鳍片上都有哑光涂层,所以触感更偏温润。而显卡的外壳部分,采用了大面积的金属包裹,表面为磨砂材质。

散热鳍片全部采用了哑光涂层
NVIDIA这款RTX 3080拿在手里给人的第一感觉就是——完美。这绝对是件艺术品,虽然以往在公版评测的时候我们都会惊叹其做工精致,但像这次如此巧妙地将大面积的金属融合在一起,形成刚柔并济,绝对在设计之初下了很大功夫,而这种效果弄不好就会成为一个“铁疙瘩”。

GeForce RTX 3080外观展示
之所以RTX 30系显卡的外观需要大改,是因为在散热方面同样做了颠覆性的设计。它采用了双轴流式设计,RTX 3080主动散热的风扇为一前一后,根据官方数据,空气流量相较于之前的设计增加55%,散热效率提升30%,静音效果提升至3倍。

散热系统示意
具体的工作原理如上图所示,这也是NVIDIA显卡第一次将散热系统与机箱整体散热结合,形成协同工作。

散热系统工作原理
新的散热系统,可以吸入外部的冷空气,流经GPU,并将热空气直接从机箱背部排出。另一个背面拉动式风扇同样吸入冷空气,但流经热管上的散热鳍片,并通过机箱整体的散热系统引导至机箱背部排出。

PCB版对比
在显卡内部的PCB板上NVIDIA也做了非常大的调整,为了搭配新的散热系统,此次采用了超高密度的PCB板设计,前端为“V”字造型,体积较之前缩小了50%。
从图中可以看到板子上密密麻麻的元件排布,中间为RTX 3080的核心,四周分布10颗显存颗粒,同时还有两个空焊位置。

GeForce RTX 3080 PCB大图
18相供电依次排列在芯片左右两侧,钽电容分布在边边角角的位置。另外供电接口可以看到位于整块板子的右上方,其空间也真的只能容纳下单接口了,可以说整块PCB板几乎没有任何富裕位置。

内附的供电转接线
由于本次公版显卡采用了单12pin的供电接口,为了方便适配玩家现有的电源,包装内还附带了一根转接线,可以将单12pin专为8+8pin,不过由于接口的方向设计,会正好挡住“GeForce RTX”的信仰logo,略微有些瑕疵。
02 NVIDIA Ampere架构带来的变化
下面我们就来看看,“有史以来最伟大性能提升”相比第一代的RTX Turing架构,NVIDIA Ampere会有哪些变化吧。
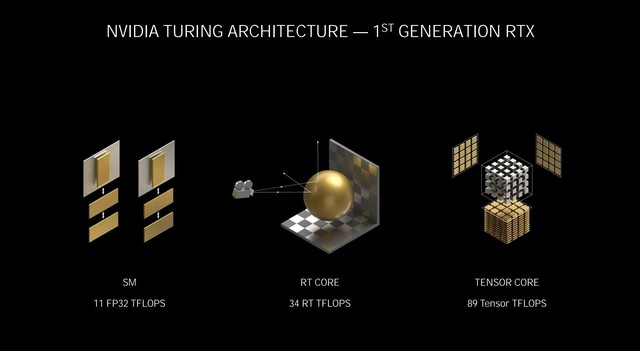
第一代RTX架构 Turing

第二代RTX架构 Ampere
首先来简单回顾一下在9月2日发布会的PPT上我们都看到了什么,相较于初代的Turing RTX架构,NVIDIA Ampere架构在算力上有着成倍的增长,每个时钟执行2次着色器运算,而Turing为1次,着色器性能达到30 TFLOPS单精度性能,而Turing为11 TFLOPS。
NVIDIA Ampere架构翻倍了光线与三角形的相交吞吐量,RT Core达到58 RT TFLOPS,而Turing为34 RT TFLOPS。
另外在全新的Tensor Core中,可自动识别并消除不太重要的DNN权重,处理稀疏网络的速率是Turing的两倍,算力高达238 Tensor TFLOPS,而Turing为89 Tensor TFLOPS。

芯片说明
全新的NVIDIA Ampere GPU核心拥有280亿个晶体管,628平方毫米的面积,基于三星的8nm NVIDIA定制工艺,来自美光的GDDR6X显存,以及我们上面说的,三大处理核心均为初代Turing的两倍速率,构成了有史以来性能最强大的Ampere。
而NVIDIA Ampere架构的强大性能并不是NVIDIA一蹴而就,可以说在20系显卡中所采用的Turing架构功不可没,下面我们先来看看完整的GA102核心。
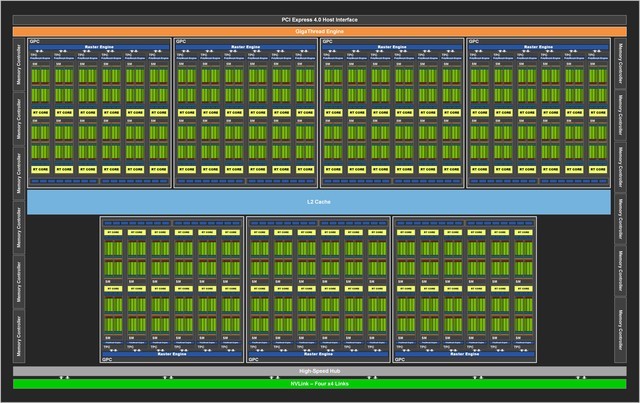
完整的GA102核心
完整的GA102 GPU包含7个GPC(图形处理集群)42个TPC(纹理处理集群)以及84个SM(流处理器)组成。GPC是占据主导地位的高级模块,拥有所有的关键图形处理单元,每个GPC包含一个专用光栅引擎。在新的NVIDIA Ampere架构中,每个GPC还包含了两个ROP分区,每个分区包含8个ROP单元。下面我们来看看每个SM单元的变化。

SM详解
在每个SM中,包含四个大的处理分区共128个CUDA核心,4个第三代Tensor Core,1个第二代RT Core,1个256 KB的缓存文件,1个128 KB的L1缓存,这个L1缓存可以根据不同的工作需求来调配缓存,工作效率发挥至最大。
另外大家都知道本次RTX 3080的CUDA数量暴增至8704个,而RTX 3090的CUDA数量更是达到了惊人的10496个,但是大家要知道专业计算卡Tesla A100的GA100核心,拥有更大的核心面积,更多的晶体管数量,理论上只有8192个CUDA,那RTX 3080又是如何达到这种效果的呢?
其实是因为本次NVIDIA Ampere的SM在Turing基础上增加了一倍的FP32运算单元,这就使得每个SM的FP32运算单元数量提高了一倍。
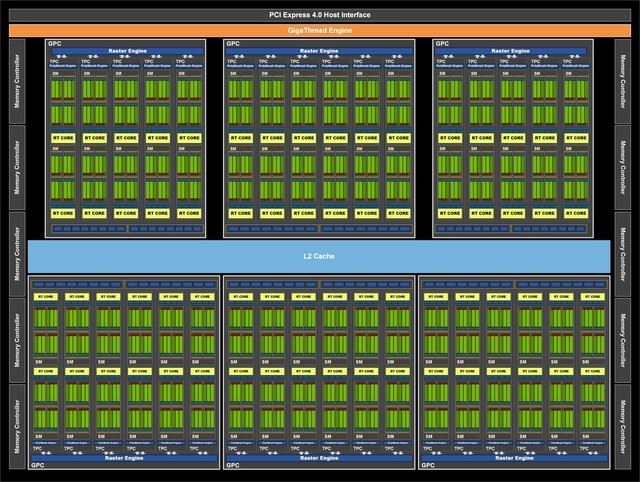
完整的GeForce RTX 3080核心
而通常我们计算显卡的CUDA数量,并不是把SM中的所有单元加起来计数,而是只统计FP32单元的数量,所以这样一来答案就显而易见了,SM中的FP32 : INT32 从 1:1 变为 2:1,如RTX 3080的8704个CUDA,其实它只有4352个INT32单元,但由于内部的FP32数量翻了一倍,所以最终实现了8704这个惊人的数字。
不过这样究竟算不算“虚标”?其实对于现在的游戏来说,浮点运算相比整数计算要常用的多,所以翻倍的FP32真的能带来性能翻倍的提升。
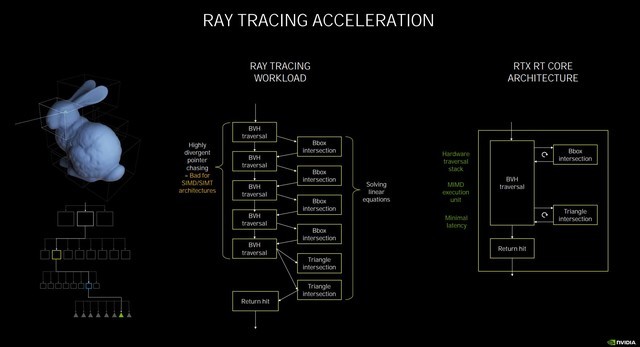
光追工作原理示意
在此次的NVIDIA Ampere架构中,NVIDIA官方宣布为第二代RT Core,它和第一代有什么不同呢。首先要知道RT Core的工作原理是,着色器发出光线追踪的请求,交给RT Core来处理,它将进行两种测试,分别为边界交叉测试(Box Intersection testing)和三角形交叉测试(Triangle Intersection testing)。基于BVH算法来判断,如果是方形,那么就返回缩小范围继续测试,如果是三角形,则反馈结果进行渲染。
而光线追踪最耗时的正是求交计算,因此,要提升光线追踪性能,主要是对两种求交(BVH/三角形求交)进行加速。

RT Core的变化
在Turing的RT Core中,可以每个周期完成5次BVH遍历、4次BVH求交以及一次三角形求交,在第二代RT Core 里,NVIDIA增加了一个新的三角形位置插值模块以及一个的额外的三角形求交模块,这样做的目的是为了提升诸如运动模糊特效时候的光线追踪性能。

运动模糊渲染原理
第二代RT Core可以让光线追踪与着色同时进行,进行的光线追踪越多,加速就越快,它将光线相交的处理性能提升了一倍,在渲染有动态模糊的影像时,按照NVIDIA自己的实测,比Turing快8倍。
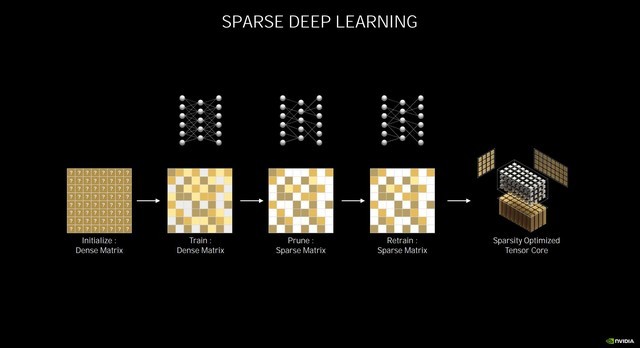
稀疏深度学习
除了光线追踪的强化,Ampere架构的Tensor Core也得到了极大地加强,在第三代Tensor Core中,NVIDIA引入了稀疏化加速,可自动识别并消除不太重要的DNN(深度神经网络)权重,同时依然能保持不错的精度。
首先原始的密集矩阵会经过训练,删除掉稀疏矩阵,再经过训练稀疏矩阵,从而实现稀疏优化,进而提高Tensor Core的性能。
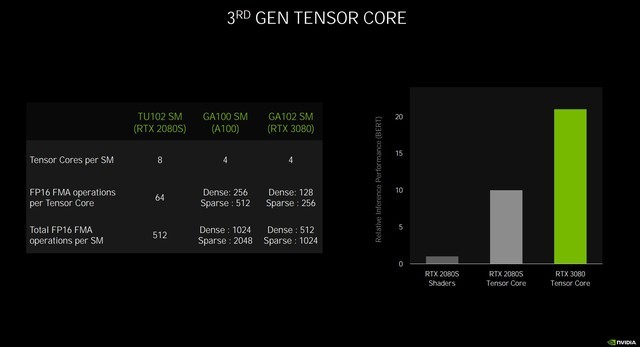
第三代Tensor Core的处理能力大大提升
所以最终的结果就是Tensor Core在处理稀疏网络的速率是Turing的两倍,算力高达238 Tensor TFLOPS,而Turing为89 Tensor TFLOPS。
同时在发布会中,黄仁勋还提到了一项新技术——RTX IO。目前很多游戏动辄几十G甚至百G的安装空间,对于存储空间的负担暂且不提,但存放在硬盘中的数据,如果显卡想要读取到,需要先由CPU从硬盘中读取压缩过的数据,经过解压缩再发送到显存中。
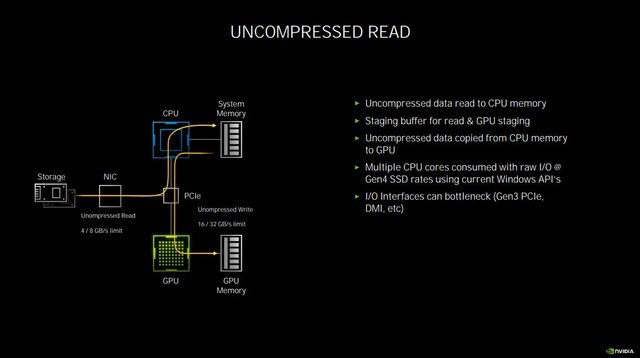
传统的数据交换
在这个过程中,会占用多个CPU核心,压力急剧增大,占用较多的内存,而此时其实GPU是处于闲置状态的。RTX IO的作用就是越过CPU解压再传输数据这一步,直接从PCIE总线读取硬盘上经过压缩的数据,并且完成解压,降低CPU占用,变向提升了性能。
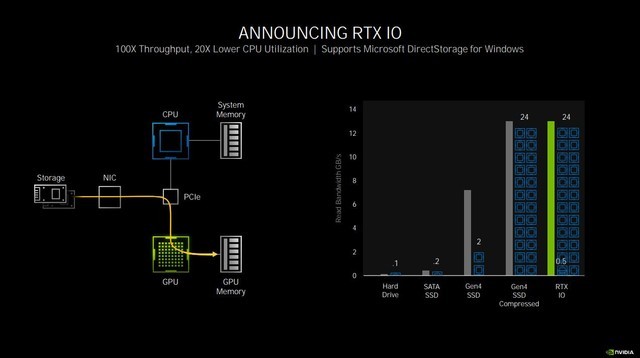
RTX IO可以极大解放CPU负担
当然这项技术作为系统底层的运行方式改变,还需要借助微软发布的DirectStorage来实现,对于目前容量的游戏来说,RTX IO的改善效果有限,但假以时日等游戏容量上百G成为常态的时候,这项技术将会发挥巨大的功效。
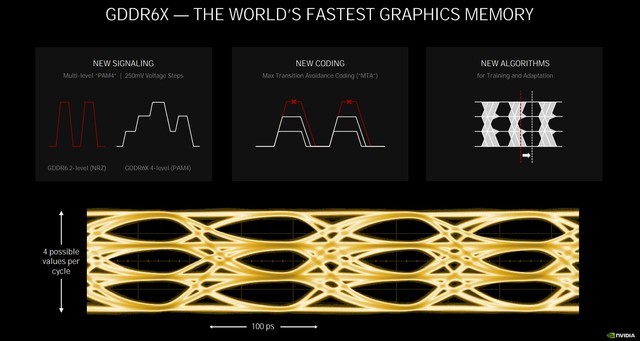
GDDR6X
在RTX 3080中,采用了GDDR6X显存,GDDR6X拥有320bit的位宽以及19Gbps的带宽速度,与采用GDDR6的Turing相比可提升40%的速度,在相同时间内GDDR6X可以比GDDR6传输多2倍的数据。这对于需要大量数据负载的工作尤为重要,如光线追踪的游戏、AI学习和8K视频渲染。
同时搭配新增的HDMI2.1接口,可以支持单线8K的视频输出,而上一代HDMI2.0仅支持4K 98Hz的视频输出,如果想要连接8K电视,则需要更多的线缆支持。
03 3DMARK 理论性能测试
首先介绍一下测试平台,为了保证此次评测能够发挥RTX 3080显卡的最佳性能,主板和CPU采用了目前桌面旗舰级配置,具体如下。

在测试成绩上,基准测试采用3DMARK,游戏性能测试使用游戏自带Benchmark和FrameView取同场景平均值。

飞利浦猛腾275M1RZ
配合全新的Nano IPS显示器可以畅快的体验画质和色彩的全方位升级,飞利浦猛腾275M1RZ显示器不但带来了全新的面板技术,还带来了流光溢彩的灯效。在游戏和创作时也能给我们新的灵感和体验。

鑫谷昆仑KL-750G电源
鑫谷昆仑KL-750G是为高端游戏平台打造的金牌电源,这款产品沿用了昆仑系列的中国风设计,750W额定功率可以满足高端游戏平台的用电需求,80 PLUS金牌效能带来了更好的节能表现,全模组输出还能提供清爽的背线效果,和30系显卡搭配相得益彰。
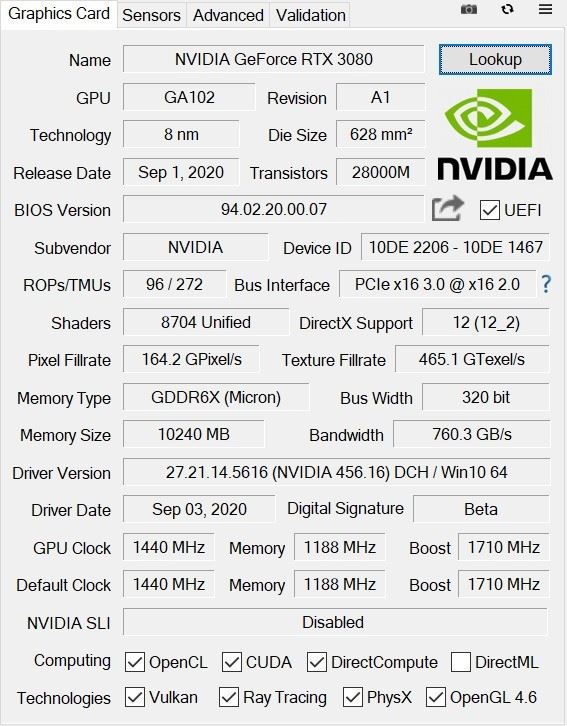
GPU-Z参数
首先看一下GPU-Z的参数,RTX 3080采用了GA102核心,三星8nm,芯片面积达到了628平方毫米,拥有8704个CUDA,频率为1440-1710MHz,采用10GB GDDR6X显存,位宽为320bit,显存带宽达到了760.3GB/s,光栅单元和纹理单元分别为96和272。
下面先进行的是用来衡量显卡DX11理论性能的3DMARK FS套装:FS,FSE,FSU三者分别对应显卡在1080P、2K、4K的理论性能,取显卡分数实际测试结果如下:
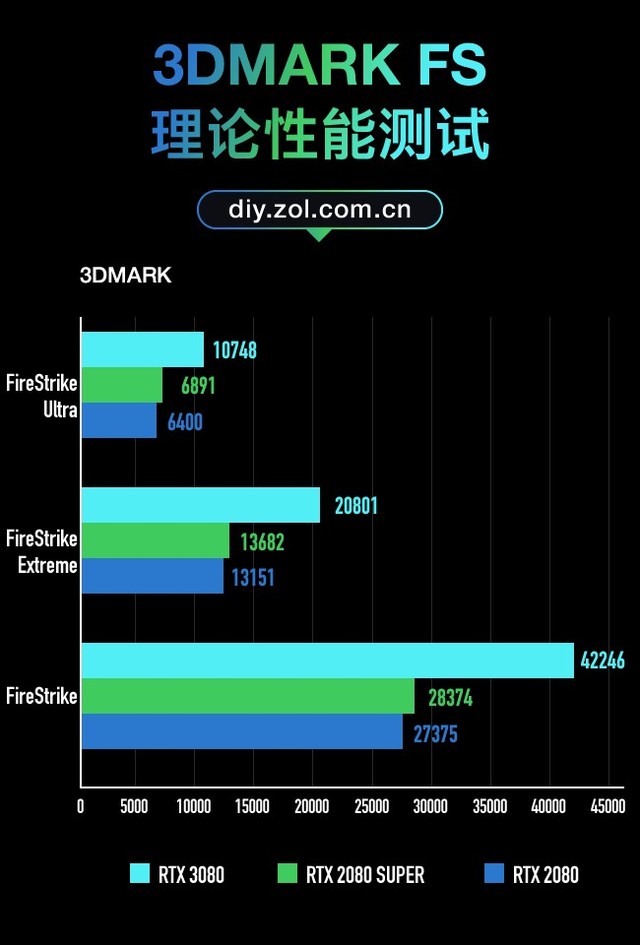
3D MARK FS套装测试
在针对显卡DX11性能的3DMARK FS套装测试中,RTX 3080比RTX 2080在FS中分数高54%,在FSE中分数高58%,在FSU中分数高67%。不难发现在越高的分辨率分数差距越大,同样的在光追效果和DLSS效果中差距也会更大,下面我们会详细介绍。
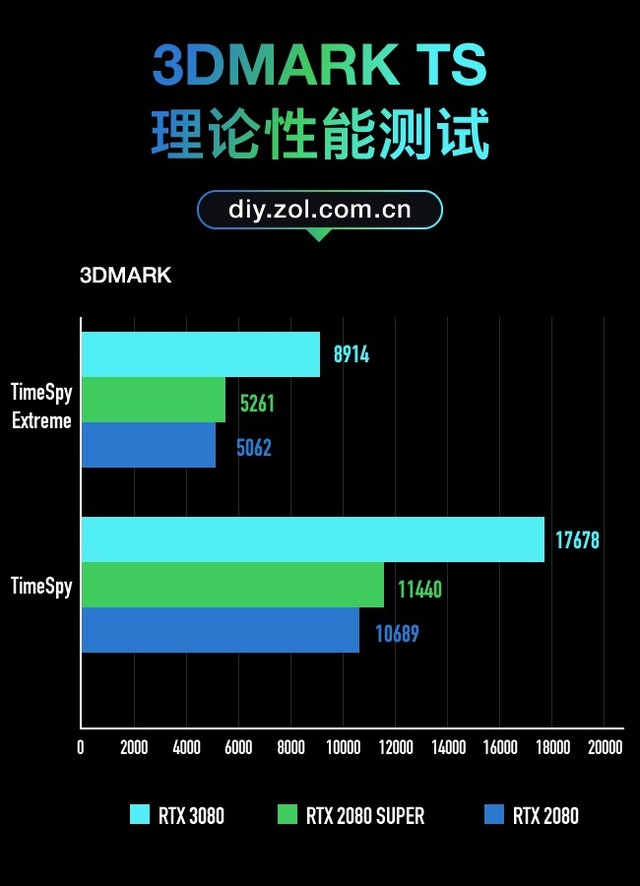
3D MARK TS套装测试
而在针对DX12性能的Time Spy和Time Spy Extreme测试中,RTX 3080比RTX 2080的TS分数高65%,TSE中分数高76%。不难发现,在DX12环境中RTX 3080的表现尤其突出。
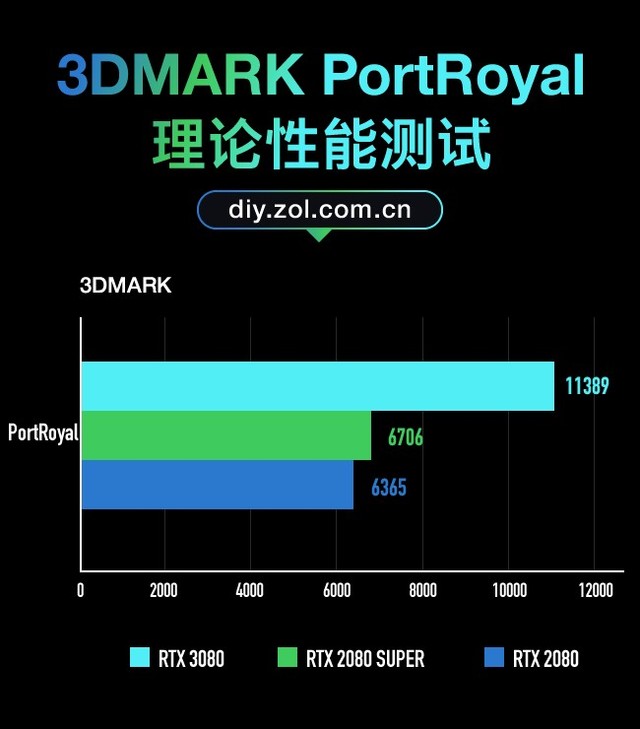
3D MARK 光追测试
PortRoyal是3DMARK中专门针对光追性能的测试项,RTX 3080相比RTX 2080的分数提升了79%。
理论测试的分数虽然是显卡性能非常重要的评判标准,不过实际的游戏帧数表现可能才是玩家最关心的,下面我们来看游戏实测。
04 游戏性能测试
在游戏性能测试中,我们选择了《控制》、《古墓丽影暗影》、《DOOM Eternal》、《德军总部新血脉》《孤岛惊魂5》、《刺客信条奥德赛》、国产游戏《边境》、《光明记忆:无限》的benchmark跑分软件。其中《控制》和《DOOM Eternal》没有游戏自带benchmark,所以我们选择FrameView取同场景游戏的平均值来做计算,但准确性肯定无法和benchmark相比。
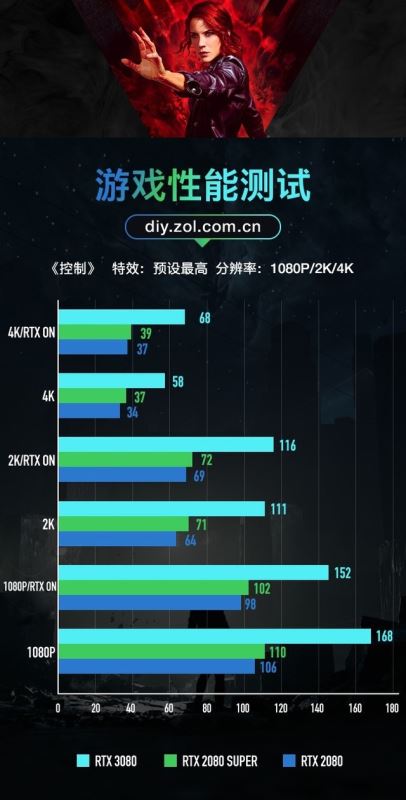
《控制》游戏测试
首先是大作《控制》,目前《控制:最终合辑》登录steam,这款游戏在物理破坏和光影效果十分出色,并且由于设置中自带多项选择,所以我们的测试分为2组6测,第一组为预设最高画质下,RTX OFF/DLSS OFF,第二组为预设最高画质下,RTX 高/DLSS ON,我们可以看到上图中的具体表现。
其中在1080P分辨率下RTX 3080比RTX 2080的分数高58%和55%;2K分辨率下高73%和68%;4K分辨率下高71%和84%,可以看出分辨率越高,光追效果越好,RTX 3080领先分数就越多。

《古墓丽影暗影》游戏测试
在《古墓丽影暗影》中,由于加入了光追和DLSS效果,所以我们也分为2组6测,第一组为预设最高画质下,RTX OFF/DLSS OFF,第二组为预设最高画质下,RTX 超高/DLSS ON。其中RTX 3080比RTX 2080在1080P分辨率下,高30%和45%;2K分辨率下高57%和55%;4K分辨率下高70%和65%,整体提升幅度在50%-70%之间。

《DOOM Eternal》游戏测试
《DOOM Eternal》是毁灭战士系列的最新作品,对于机器的配置要求比较低,主要以爽快为主。其中RTX 3080比RTX 2080在1080P分辨率下高47%;2K分辨率下高59%;4K分辨率下高74%。不过由于《DOOM Eternal》同样没有benchmark,只能去场景平均值,并且场景内存在大量烟雾效果,帧数并不准确,仅供参考。

《德军总部新血脉》游戏测试
在《德军总部新血脉》中,由于自带两个benchmark,所以我们的数据取跑分均值。其中RTX 3080比RTX 2080在1080P分辨率下的分数高23%,2K分辨率下高44%;4K分辨率下高57%。

《刺客信条奥德赛》游戏测试
接下来是众生平等奥德赛,虽然叫众生平等,但从图中我们可以看到真的有显卡能在4K分辨率下稳定60帧以上了。其中RTX 3080比RTX 2080在1080P分辨率下分数高38%;2K分辨率下高42%;4K分辨率下高54%。
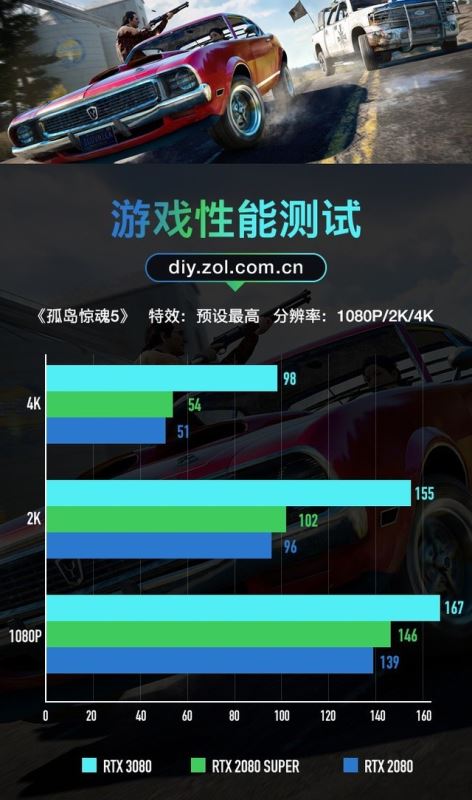
《孤岛惊魂5》游戏测试
《孤岛惊魂5》同样算是优化比较到位的3A大作,RTX 3080比RTX 2080在1080P分辨率下分数高20%;2K分辨率下高61%;4K分辨率下高92%。

《光明记忆:无限》游戏测试
《光明记忆:无限》是由飞燕群岛工作室开发的《光明记忆》新系列,目前还没有游戏提供试玩,不过benchmark的跑分软件官方已经提供,我们在测试的时候由于无法关闭光追选项,故所有测试成绩均为“RTX 高/DLSS 质量”模式下进行。
在1080P分辨率下,RTX 3080比RTX 2080分数高58%,2K分辨率下高91%,4K分辨率下高105%。
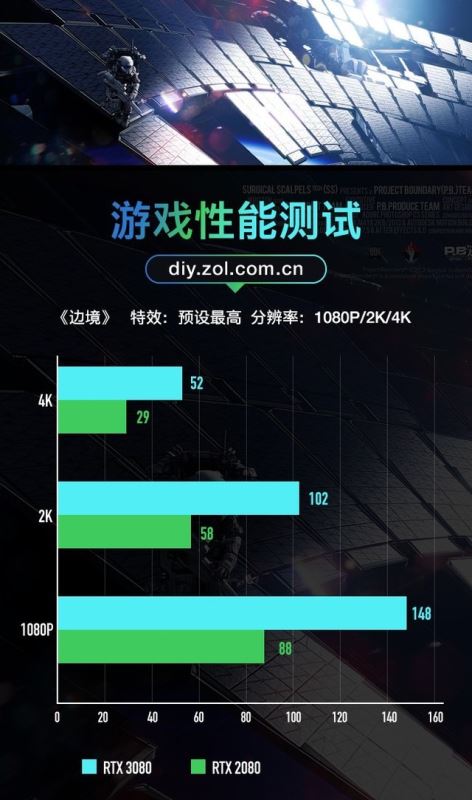
《边境》游戏测试
《边境》同样是一款来自柳叶刀工作室的国产3A大作,具体发售日期不明,目前仅提供了benchmark跑分软件。同样的目前跑分软件不支持关闭光追选项,所以在测试时我们选择“RTX 高/DLSS 质量”下进行。
在1080P分辨率下,RTX 3080比RTX 2080分数高68%,2K分辨率下高75%,4K分辨率下高79%。
05 温度功耗测试
在温度功耗测试方面,室温24℃,我们并没有采用全封闭式的机箱,而是采用测试平台的方法,这样做可以最大限度的保证显卡除了自身散热外将风道等外因减小到最低。
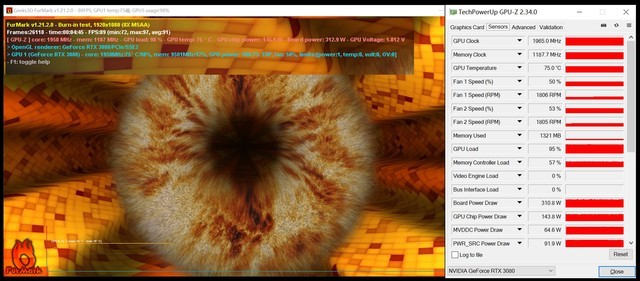
功耗测试(点击查看大图)
功耗测试中,我们选择FurMark软件进行拷机测试,功耗仅计算显卡自身。可以看到新的NVIDIA Ampere架构显卡,确实是功耗大户在峰值情况下两款软件略有出入,但整体平均在310W-315W之间。

温度测试
温度方面,本次的RTX 3080依然控制在75℃左右,而RTX 2080的核心面积为545平方毫米,RTX 3080的核心面积为628平方毫米,足足大了15%,但温度依然控制的不错,在散热设计方面,RTX 3080确实是下了功夫的。
06 Ampere On the Way
关于NVIDIA GeForce RTX 3080显卡的测试在这里就告一段落,而NVIDIA在发布会中公布的更多软件及技术我们后续也将会为大家带来详细的体验和测试。
相信在看完发布会后,所有玩家大呼“过瘾!真香!”性能显著提升但价格不变,用震惊世界这个词来说也丝毫不为过。当年GTX 10系显卡性能翻倍的神化,在RTX 30系显卡中再次实现了。
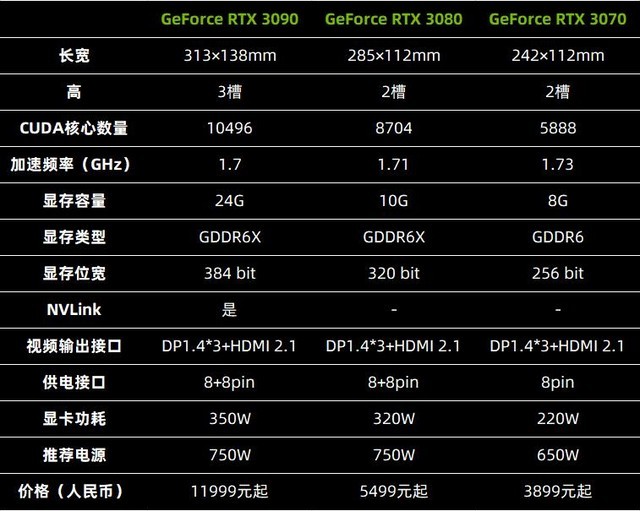
30系显卡综合参数
其实在整场发布会下来,最让笔者感到不可思议的还是Marbles场景演示。在两个月前发布GA100中的厨房演讲上,黄仁勋展示了完全光线追踪的实时图型Marbles,当时使用的显卡为 Quadro RTX 8000 专业图形卡,但仅能以720P 每秒25帧来呈现。而发布会中黄仁勋带来了增强版的夜间Marbles模型,增加了更多光线效果并且还增加了景深效果,最终能以1440P分辨率 每秒30帧来呈现,性能提升了4倍。

更加复杂的Marbles模型场景
演示中的动画完全由光线追踪完成实时渲染,无光栅化处理,并且场景中多达数百个光源,完全没有预烘焙,所以最终呈现在我们眼前的是这样电影级的画质。
完全的纯光线追踪,完全的路径追踪,这在图形学是作为圣杯级别的存在,而现在它竟是标配,对于视频的演示效果,笔者只想说,Ampere作为有史以来最大的性能飞跃,毫不夸张。

未来可期
而价格方面,30系显卡的整体定价非常良心,RTX 3080相比RTX2080性能接近2倍提升下,售价保持不变。而RTX 3080的定位大家不要忘了是目前的旗舰级产品,对于大部分玩家来说是性能过剩的,所以在不久的将来30系普及后,相信3000-5000元的价位就能让用户轻轻松松享受到顶级体验。即便预算不够,后续NVIDIA还将会推出甜品级的显卡,性能较今天的甜品级也是有翻倍提升。至于万元以上的RTX 3090显卡,会用在更多有深度学习需求的用户上,至少以目前来说,它的定位依旧是在游戏之上。
同时也有玩家会问,RTX 20系显卡如此“短寿”算不算失败的一代,我认为不算。Turing为我们开创了光线追踪和AI学习的新世界,奠定了GPU未来的发展方向,真正意义上实现从性能的堆砌到质的改变。而Ampere则是站在巨人的肩膀,将上一代的路走的更宽更扎实。
本文转载自http://diy.zol.com.cn/749/7495167.html