
Python 爬虫修养-处理动态网页
脚本之家
在爬虫开发中,大家可以很轻易地 bypass 所谓的 UA 限制,甚至用 scrapy 框架轻易实现按照深度进行爬行。但是实际上,这些并不够。关于爬虫的基础知识比如数据处理与数据存储多线程之类的。
请大家移步 FB:
该系列文章都是本人所写,能力有限请多包涵。
0x01 前言
在进行爬虫开发的过程中,我们会遇到很多的棘手的问题,当然对于普通的问题比如 UA 等修改的问题,我们并不在讨论范围,既然要将修养,自然不能说这些完全没有意思的小问题。
0x02 Selenium + PhantomJS
这个东西算是老生长谈的问题吧,基本我在问身边的朋友们的时候,他们都能讲出这条解决方案:
Selenium + PhantomJS(Firefox Chrome之类的)
但是真正的有实践过的人,是不会把这个东西投入生产环境的,首先最大的问题就是Selenium + PhantomJS 非常的慢,这种慢的原因就是因为他要加载这个网页所有的内容,比如图片资源,link 中的 CSS,JS 都会加载,而且还会渲染整个网页,在渲染结束之后才会允许你操作网页的元素。当然可能会有读者问,Selenium 作为可以自动化编写测试脚本的一个模块,他是自带 HOOK 功能的,在 Selenium 的 API 中也有介绍说 Selenium 可以控制等待某一个元素加载成功时返回页面数据。
没错的确是这样的,我们确实可以使用 Selenium 的内置 api 去操作浏览器完成各种各样的操作,比如模拟点击,模拟填表,甚至执行 js,但是最大的问题我们还是没有解决:归根结底是操作浏览器来进行工作的,启动需要打开浏览器(等待一定时间),访问网页之后渲染,下载相应资源,执行 JS,这么多的步骤,每一个步骤都需要或多或少的等待时间,这就好比,我们就是在使用浏览器做这样的事情,只不过是加上了精准的鼠标定位而已。
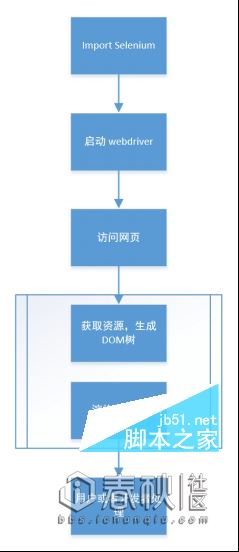
当然说了这么多,Selenium 虽然不适合做生产解决方案,也并不是没有别的解决办法了。
0x03 execjs
execjs 是一个在 Python 中执行 js 的模块,听到这个,大家可能会觉得耳目一新:欸?那我是不是可以爬虫爬下来 js 代码然后手动控制 js 执行,然后就可以控制自己想要的元素,拿到想要的结果,而且也并不丢失效率。
但是我要说这样的想法,实际上是非常的 naive,虽然有了这个 js 引擎,但是,我们需要很多很多的轮子,为什么呢?来听我一步一步解释:
1. js 的强大之处其实并不在于松散的语法与容错,而是在于对 BOM 对象和 DOM 对象的操作。举个例子来说,比如,一个网页的表单,是通过操作执行 js 来提交的。 那么,问题就在于你有办法仅仅用这个 execjs 来执行这段 js 来提交表单么? 显然,这是行不通的。为什么呢?因为对于我们来说的话 execjs 是一个独立的模块,我们没有办法把我们静态扒下来的html 文档和 execjs 建立联系。
2. 如果非要建立联系,那么你需要自己完成 js 对 html 的 DOM 对象的绑定,具体怎么完成呢?js 在浏览器中怎么与 DOM 树绑定,你就需要怎么去做。但是要怎么做啊,首先你需要一个自己构建 DOM 树,然后才能进行手动绑定。这个轮子,确实是非常的大。
但是如果你真的有大把的时间,那么应该怎么去做这个事情呢?没错要不你去 HOOK 一个webkit 要不你去自己构建一个 html 的解析器。那么我就在这里稍微提一下这个很有趣的事情:如果构建一个 HTML 解析器:

最近有用 PLY 写过一个 Lexer 当时准备做个解析 DOM 树的 HTML 解析器,自己实践第一步也是觉得这个东西理论上是完全可行的,但是能不能完成就要看个人毅力和你个人的编程能力了。
0x04 Ghost
关于 Ghost 的话,其实我个人是比较推崇的,但是其实他也并不是特别完美,它对我来说,更像是一个 Selenium 与PhantomJS 的结合体,怎么说呢,实际上 ghost 这个模块用的是QT 中的 webkit,在安装的时候就得被迫安装 pyside 或者 pyqt4,实际上我当时还是很难理解为什么一个这个东西没有图形界面要使用 qt 和 pyside 这种东西作为引擎呢?单独构造一个浏览器引擎真的就这么困难么?其实装好了也没什么关系,毕竟我觉得还是要比Selenium 配 PhantomJS 好用的。
话说回来,我们就来讨论一下这个 Ghost 的一些问题。
首先,使用 Ghost 的一个好处是我们并不需要再将一个 binary 的浏览器放在路径下了,以至于我们不需要去花费时间打开浏览器了,因为 ghost 就是一个功能完全的 Python 实现(借助 qt 的 webkit)的轻量级没有图形化的浏览器。
而且,ghost 在初始化的时候,有一个选项可以不下载图片,但是没有办法阻止它下载 js 和css, 其实这个也是可以原谅的,毕竟自己在使用的时候,也是需要自己去下载 js 在本地筛选。
于此同时 ghost 还是提供了相应的 API 这些 API 和 selenium 的 API 功能基本差别不是特别大,也会有处理表单,执行 ajax 去加载动态页面,这样来说 ghost 是一个完美的解决方案么?
其实还是有他自己的缺点的,就是我们还是不能完全控制每一个过程,比如我们如果只想让它解析 DOM 树,不动态执行 js 脚本,而且,我想获取他的 DOM 树手动进行一些操作。这些都是没有办法的。但是也并不是完全没有办法,比如国内某厂他们就做了 HOOK 了一个浏览器去检测 XSS 这个思路我们可以在以后的文章中提出,具体的操作的话,这就要看大家的编程功底了。

0x05 原理总结
当然,懂得归纳的读者其实早就已经看出来了,对动态网页(通过 js 加载)的网页的信息采集,主要分成三种方案:
1. 基于实体浏览器操作解决方案(适用于测试环境不适用于大量信息采集)。
2. 基于深度控制 JS 脚本执行的解决方案(速度最快,编写难度最大)。
3. 基于 webkit 的解决方案。(相对较为折衷)
本文转自:i春秋社区
原文地址:http://bbs.ichunqiu.com/thread-11098-1-1.html?from=jbzj