
MySQL 聚合函数及应用
作者:無限進步D
聚合(或聚集、分组)函数:
对一组数据进行汇总的函数,输入一组数据的集合,输出单个值
1. 常见的聚合函数
- 作用: 作用于一组数据,并对一组数据返回一个值

语法:

- 聚合函数不能嵌套调用
- 比如不能出现类似“AVG(SUM(字段名称))”形式的调用
1.1 AVG和SUM函数
- 对象:数值型数据
- 作用:AVG平均值,SUM总和
mysql> SELECT
-> AVG(salary) '平均工资',
-> SUM(salary) '总工资'
-> FROM
-> employees;
+-------------+-----------+
| 平均工资 | 总工资 |
+-------------+-----------+
| 6461.682243 | 691400.00 |
+-------------+-----------+
1 row in set (0.01 sec)
注意:如果应用于字符串等类型,不会报错,但是结果没有意义
1.2 MIN和MAX函数
- 对象:任意数据类型(数值、字符串、时间日期……)
- 作用:MIN最小值,MAX最大值
数值即最大、最小的数值
mysql> SELECT
-> MAX(salary) '最高工资'
-> ,MIN(salary) '最低工资'
-> FROM
-> employees;
+----------+----------+
| 最高工资 | 最低工资 |
+----------+----------+
| 24000.00 | 2100.00 |
+----------+----------+
1 row in set (0.00 sec)
字符串按字典序
mysql> SELECT
-> MAX(last_name)
-> FROM
-> employees;
+----------------+
| MAX(last_name) |
+----------------+
| Zlotkey |
+----------------+
1 row in set (0.00 sec)
1.3 COUNT函数
- 对象:任意数据类型
- 作用:返回表中记录总数
COUNT(*)返回表中记录总数,适用于任意数据类型
mysql> SELECT COUNT(*) FROM employees; +----------+ | COUNT(*) | +----------+ | 107 | +----------+ 1 row in set (0.00 sec)
COUNT(expr) 返回expr不为空的记录总数
mysql> SELECT
-> COUNT(commission_pct)
-> FROM
-> employees;
+-----------------------+
| COUNT(commission_pct) |
+-----------------------+
| 35 |
+-----------------------+
1 row in set (0.00 sec)
Q&A:
Q:AVG(xxx) 等于 SUM(xxx) / COUNT(xxx) 吗?
A:等于,AVG()和SUM()也会过滤NULL
Q:count(*),count(1),count(列名)用谁好?
A1:对于MyISAM引擎的表是没有区别的,引擎内部有一计数器在维护着行数
A2:但若是Innodb引擎的表用count(*),count(1)直接读行数,复杂度是 O(n)O(n)O(n) ,因为innodb真的要去数一遍,但好于具体的count(列名)
Q:能不能使用count(列名)替换count(*)?
A:不要使用 count(列名)来替代 count(*)count(*)是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行
练习:
查询公司中的平均奖金率
mysql> SELECT
-> SUM(commission_pct)/COUNT(IFNULL(commission_pct,0)) '平均奖金率',
-> AVG(IFNULL(commission_pct,0)) '平均奖金率'
-> FROM
-> employees;
+------------+------------+
| 平均奖金率 | 平均奖金率 |
+------------+------------+
| 0.072897 | 0.072897 |
+------------+------------+
1 row in set (0.00 sec)注意:AVG()会把NULL去掉,但平均奖金率应该把0也算进去
2. GROUP BY
group 组
2.1 基本使用
可以使用GROUP BY子句将表中的数据分成若干组
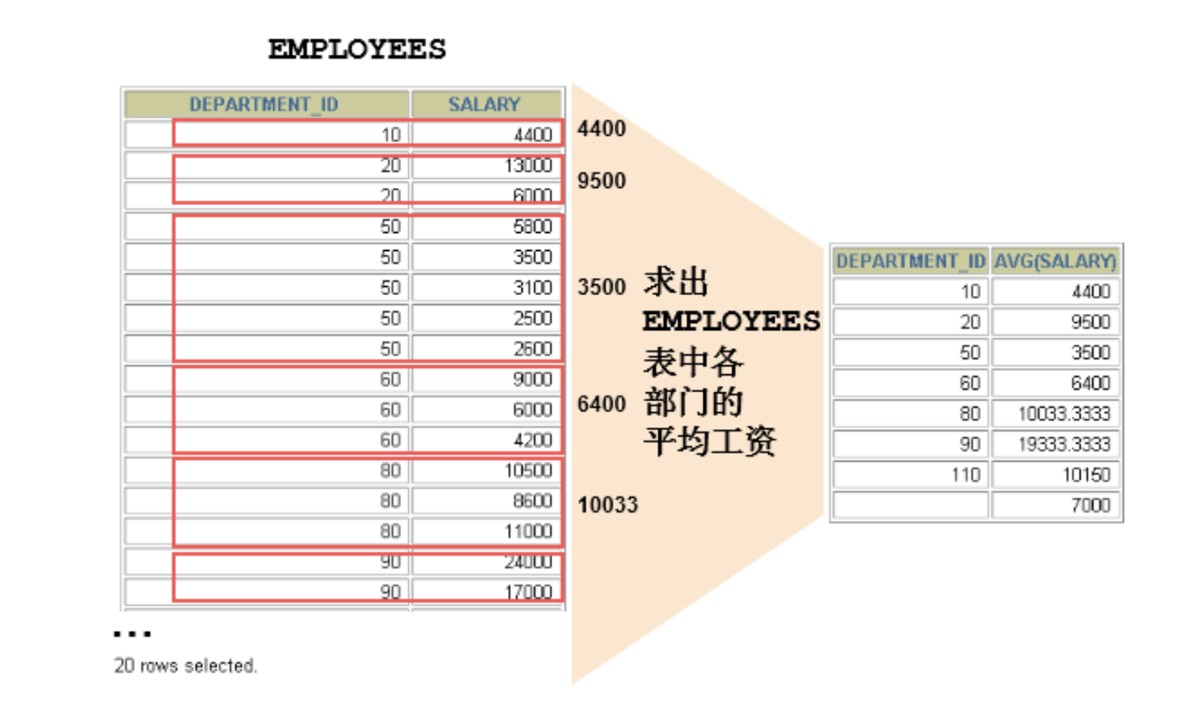
mysql> SELECT
-> department_id,
-> AVG( salary )
-> FROM
-> employees
-> GROUP BY
-> department_id;
+---------------+---------------+
| department_id | AVG( salary ) |
+---------------+---------------+
| NULL | 7000.000000 |
| 10 | 4400.000000 |
| 20 | 9500.000000 |
| 30 | 4150.000000 |
| 40 | 6500.000000 |
| 50 | 3475.555556 |
| 60 | 5760.000000 |
| 70 | 10000.000000 |
| 80 | 8955.882353 |
| 90 | 19333.333333 |
| 100 | 8600.000000 |
| 110 | 10150.000000 |
+---------------+---------------+
12 rows in set (0.00 sec)
2.2 使用多个列分组
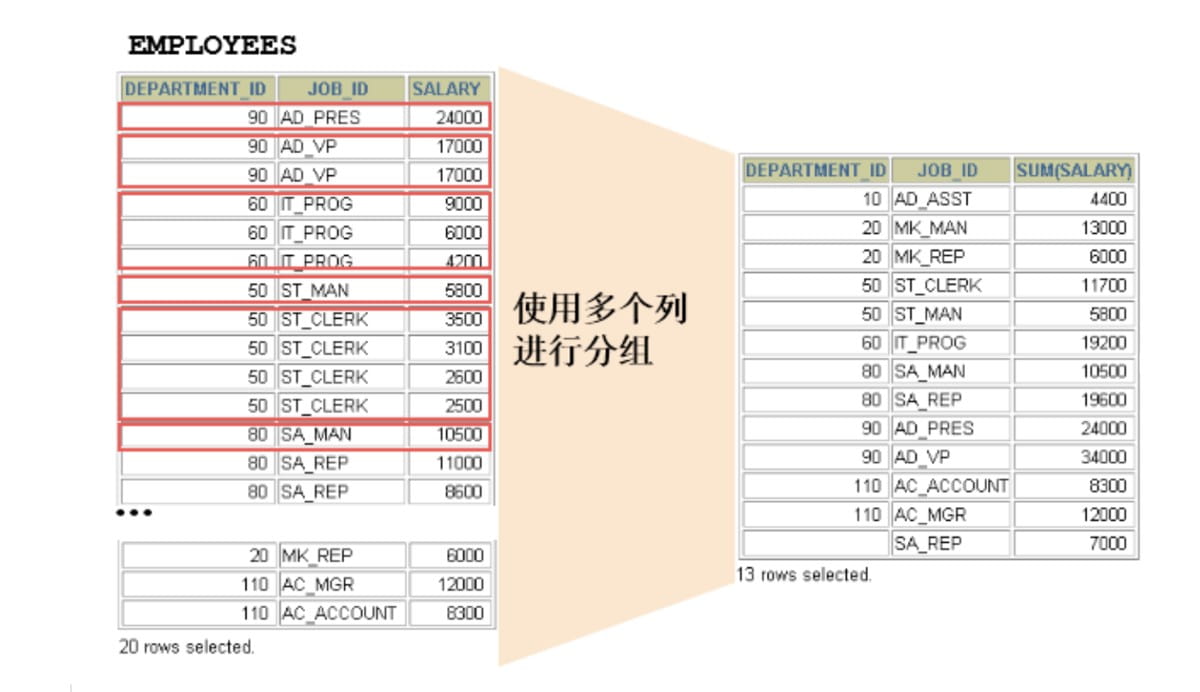
mysql> SELECT
-> department_id,
-> job_id,
-> SUM( salary )
-> FROM
-> employees
-> GROUP BY
-> department_id,
-> job_id;
+---------------+------------+---------------+
| department_id | job_id | SUM( salary ) |
+---------------+------------+---------------+
| 90 | AD_PRES | 24000.00 |
| 90 | AD_VP | 34000.00 |
| 60 | IT_PROG | 28800.00 |
| 100 | FI_MGR | 12000.00 |
| 100 | FI_ACCOUNT | 39600.00 |
| 30 | PU_MAN | 11000.00 |
| 30 | PU_CLERK | 13900.00 |
| 50 | ST_MAN | 36400.00 |
| 50 | ST_CLERK | 55700.00 |
| 80 | SA_MAN | 61000.00 |
| 80 | SA_REP | 243500.00 |
| NULL | SA_REP | 7000.00 |
| 50 | SH_CLERK | 64300.00 |
| 10 | AD_ASST | 4400.00 |
| 20 | MK_MAN | 13000.00 |
| 20 | MK_REP | 6000.00 |
| 40 | HR_REP | 6500.00 |
| 70 | PR_REP | 10000.00 |
| 110 | AC_MGR | 12000.00 |
| 110 | AC_ACCOUNT | 8300.00 |
+---------------+------------+---------------+
20 rows in set (0.00 sec)
注意:
- SELECT 中出现的非组函数的字段必须声明在GROUP BY 中
- GROUP BY 子句中声明的字段可以不出现在SELECT 中
- GROUP BY 声明在 FROM 、WHERE 后面,ORDER BY、LIMIT 前面
2.3 GROUP BY中使用WITH ROLLUP
使用 WITH ROLLUP 关键字之后,在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的总和,即统计记录数量
mysql> SELECT
-> department_id,
-> AVG( salary )
-> FROM
-> employees
-> WHERE
-> department_id > 80
-> GROUP BY
-> department_id WITH ROLLUP;
+---------------+---------------+
| department_id | AVG( salary ) |
+---------------+---------------+
| 90 | 19333.333333 |
| 100 | 8600.000000 |
| 110 | 10150.000000 |
| NULL | 11809.090909 |# 多的一行
+---------------+---------------+
# 算的平均,所以这里是总的平均值
4 rows in set (0.00 sec)[!注意]
当使用ROLLUP时,不能同时使用ORDER BY子句进行结果排序,即ROLLUP和ORDER BY是互相排斥的
3. HAVING
注意: WHERE不能使用聚合函数,所以过滤条件中出现聚合函数,就得用HAVING
过滤分组: HAVING子句
- 行已经被分组
- 使用聚合函数
- 满足HAVING 子句中条件的分组将被显示
- HAVING 不能单独使用,必须要跟 GROUP BY 一起使用,且HAVING 必须声明在 GROUP BY 后面
mysql> SELECT
-> department_id,
-> MAX( salary )
-> FROM
-> employees
-> GROUP BY
-> department_id
-> HAVING
-> MAX( salary )> 10000;
+---------------+---------------+
| department_id | MAX( salary ) |
+---------------+---------------+
| 20 | 13000.00 |
| 30 | 11000.00 |
| 80 | 14000.00 |
| 90 | 24000.00 |
| 100 | 12000.00 |
| 110 | 12000.00 |
+---------------+---------------+
6 rows in set (0.00 sec)
练习:查询部门id为10,20,30,40这4个部门中最高工资比10000高的部门信息息
方法一:用WHERE
mysql> SELECT
-> department_id,
-> MAX( salary )
-> FROM
-> employees
-> WHERE
-> department_id IN(10,20,30,40)
-> GROUP BY
-> department_id
-> HAVING
-> MAX( salary )> 10000;
+---------------+---------------+
| department_id | MAX( salary ) |
+---------------+---------------+
| 20 | 13000.00 |
| 30 | 11000.00 |
+---------------+---------------+
2 rows in set (0.00 sec)
方法二:用HAVING
mysql> SELECT
-> department_id,
-> MAX( salary )
-> FROM
-> employees
-> GROUP BY
-> department_id
-> HAVING
-> MAX( salary )> 10000
-> AND department_id IN ( 10, 20, 30, 40 );
+---------------+---------------+
| department_id | MAX( salary ) |
+---------------+---------------+
| 20 | 13000.00 |
| 30 | 11000.00 |
+---------------+---------------+
2 rows in set (0.00 sec)
推荐使用方式一,方式一执行效率高于方式二
[!结论]
当过滤条件中有聚合函数时,则此过滤条件必须声明HAVING中
当过滤条件中没有聚合函数时,则此过滤条件在WHERE或HAVING 中都可以,但是建议声明在WHERE中
[!WHERE和HAVING的对比]
- HAVING的适用范围更广
- 若没有聚合函数,WHERE的执行效率比HAVING高(从下面的执行原理中可见一斑)
4. SQL 底层执行原理
4.1 SELECT 语句的完整结构
- SQL92语法
SELECT ...,...,...(存在聚合函数) FROM ...,...,... WHERE 多表的连接条件 AND 不包含聚合函数的过滤条件 GROUP BY ...,... HAVING 包含聚合函数的过滤条件 ORDER BY ...,...(ASC/DESC) LIMIT ...,...
- SQL99语法
SELECT ...,...,...(存在聚合函数) FROM ...(LEFT/RIGHT)JOIN...ON 多表的连接条件 WHERE 不包含聚合函数的过滤条件 GROUP BY ...,... HAVING 包含聚合函数的过滤条件 ORDER BY ...,...(ASC/DESC) LIMIT ...,...
4.2 SELECT执行顺序

FROM -> ON -> (LEFT/RIGHT)JOIN -> WHERE -> GROUP BY -> HAVING -> SELECT 的字段 -> DISTINCT -> ORDER BY -> LIMIT
- 在 SELECT 语句执行这些步骤的时候,每个步骤都会产生一个虚拟表 ,然后将这个虚拟表传入下一个步骤中作为输入
- 这些步骤隐含在 SQL 的执行过程中,对于我们来说是不可见的
4.3 SQL 的执行原理
SQL 是声明式语言,我们写的是“要什么”,数据库引擎负责“怎么实现”。其底层执行遵循固定的逻辑顺序(≠ 书写顺序),该顺序决定了查询如何逐步生成结果
| 阶段 | 关键字/操作 | 作用 | 输出虚拟表 |
|---|---|---|---|
| 1. FROM + JOIN | FROM + JOIN(含 CROSS JOIN, INNER JOIN, LEFT JOIN 等) | 构建初始数据集: • 多表时先做笛卡尔积( CROSS JOIN)→ 得 vt1-1• 再通过 ON 条件筛选 → vt1-2• 若有外连接(LEFT/RIGHT/FULL),添加外部行 → vt1-3 | vt1(最终原始数据集) |
| 2. WHERE | WHERE | 对 vt1 进行行级过滤(条件筛选) | vt2 |
| 3. GROUP BY | GROUP BY | 在 vt2 上按指定列分组 | vt3(分组后中间表) |
| 4. HAVING | HAVING | 对 vt3 的分组结果进行过滤(聚合函数可用) | vt4 |
| 5. SELECT | SELECT | 提取指定字段(可含表达式、别名) | vt5-1 |
| 6. DISTINCT | DISTINCT | 去除重复行(在 vt5-1 上操作) | vt5-2 |
| 7. ORDER BY | ORDER BY | 按指定字段排序(稳定排序) | vt6 |
| 8. LIMIT / OFFSET | LIMIT [n] [OFFSET m] | 截取前 n 行(或跳过 m 行后取 n 行) | vt7(最终结果集) |
虚拟表命名说明:
vt1-x:FROM+JOIN 阶段的子步骤vt1~vt7:各主阶段输出的逻辑中间结果
补充:
- 并非所有阶段都存在
- 若无
GROUP BY,则跳过GROUP BY和HAVING - 若无
DISTINCT,则跳过该步 - 若无
ORDER BY或LIMIT,对应阶段省略
- 若无
- 关键字顺序 ≠ 执行顺序
- 书写顺序:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... LIMIT - 执行顺序:FROM → WHERE → GROUP BY → HAVING → SELECT → DISTINCT → ORDER BY → LIMIT
- 书写顺序:
- 为什么理解执行顺序很重要?
- 解释为何
WHERE中不能用SELECT别名(此时尚未执行 SELECT) - 理解
HAVING可用聚合函数而WHERE不行(分组未完成) - 优化查询:避免在
WHERE中使用函数导致索引失效(因 WHERE 早于 SELECT)
- 解释为何
到此这篇关于MySQL 聚合函数及应用的文章就介绍到这了,更多相关mysql 聚合函数内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!