
MySQL与Redis如何保证双写一致性详解
作者:程序员小假
前言
首先,我们必须明确一个核心观点:在分布式环境下,要实现强一致性(在任何时刻读取的数据都是最新的)是极其困难且代价高昂的,通常会严重牺牲性能。因此,在实践中,我们通常追求最终一致性,即允许在短暂的时间内数据不一致,但通过一些手段保证数据最终会保持一致。
下面我将从基础概念、各种策略、最佳实践到最新方案,为你详细讲解。
一、基础概念:为什么会有不一致?
在一个包含 MySQL(作为可靠数据源)和 Redis(作为缓存)的系统中,所有的写操作(增、删、改)都必须同时处理这两个地方。
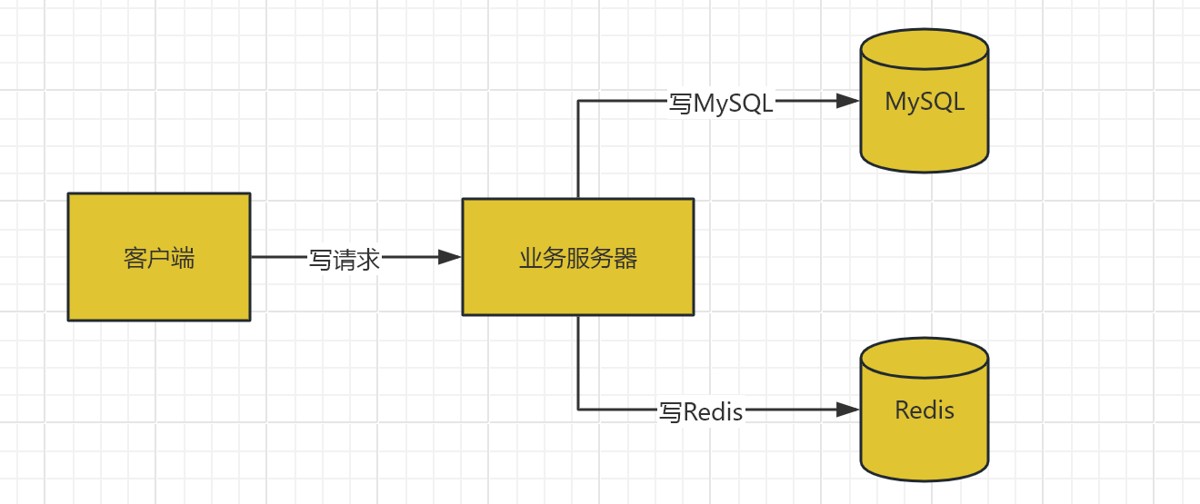
这个过程中,任何一步失败或延迟都会导致不一致:
- 写 MySQL 成功,写 Redis 失败:导致 Redis 中是旧数据。
- 写 Redis 成功,写 MySQL 失败:导致 Redis 中是“脏数据”,数据库中不存在。
- 并发读写:一个线程在更新数据库,但还没更新缓存时,另一个线程读取了旧的缓存数据。
二、核心策略与模式
解决双写一致性有多种策略,我们需要根据业务场景(对一致性的要求、读写的比例等)进行选择。
策略一:Cache-Aside Pattern(旁路缓存模式)
这是最常用、最经典的缓存模式。核心原则是:应用程序直接与数据库和缓存交互,缓存不作为写入的必经之路。
- 读流程:
- 收到读请求。
- 首先查询 Redis,如果数据存在(缓存命中),直接返回。
- 如果 Redis 中没有数据(缓存未命中),则从 MySQL 中查询。
- 将从 MySQL 查询到的数据写入 Redis(以便后续读取),然后返回数据。
- 写流程:
- 收到写请求。
- 更新 MySQL 中的数据。
- 删除 Redis 中对应的缓存。
为什么是删除(Invalidate)缓存,而不是更新缓存?
这是一个关键设计点!
- 性能:如果更新缓存,每次数据库写操作都要伴随一次缓存写操作,如果该数据并不经常被读取,那么这次缓存写入就是浪费资源的。
- 并发安全:在并发写场景下,更新缓存的顺序可能与更新数据库的顺序不一致,导致缓存中是旧数据。而删除操作是幂等的,更为安全。
Cache-Aside 如何保证一致性?
它通过“先更新数据库,再删除缓存”来尽力保证。但它依然存在不一致的窗口期:
- 线程 A 更新数据库。
- 线程 B 读取数据,发现缓存不存在,从数据库读取旧数据(因为 A 还没提交或刚提交)。
- 线程 B 将旧数据写入缓存。
- 线程 A 删除缓存。
这种情况发生的概率较低,因为通常数据库写操作(步骤1)会比读操作(步骤2)耗时更长(因为涉及锁、日志等),所以步骤2在步骤1之前完成的概率很小。但这是一种理论上的可能。
策略二:Write-Through / Read-Through Pattern(穿透读写模式)
在这种模式下,缓存层(或一个独立的服务)自己负责与数据库交互。对应用来说,它只与缓存交互。
- 写流程:应用写入缓存,缓存组件同步地写入数据库。只有两个都成功后才会返回成功。
- 读流程:应用读取缓存,如果未命中,缓存组件自己从数据库加载并填充缓存,然后返回。
优点:逻辑对应用透明,一致性比 Cache-Aside 更好。
缺点:性能较差,因为每次写操作都必然涉及一次数据库写入。通常需要成熟的缓存中间件支持。
策略三:Write-Behind Pattern(异步写回模式)
Write-Through 的异步版本。应用写入缓存后立即返回,缓存组件在之后某个时间点(例如攒够一批数据或定时)批量异步地更新到数据库。
优点:写性能极高。
缺点:有数据丢失风险(缓存宕机),一致性最弱。适用于允许少量数据丢失的场景,如计数、点赞等。
三、保证最终一致性的进阶方案
为了弥补 Cache-Aside 模式中的缺陷,我们可以引入一些额外的机制。
方案一:延迟双删
针对 Cache-Aside 中提到的“先更新数据库,再删除缓存”可能带来的并发问题,可以引入一个延迟删除。
- 线程 A 更新数据库。
- 线程 A 删除缓存。
- 线程 A 休眠一个特定的时间(如 500ms - 1s)。
- 线程 A 再次删除缓存。
第二次删除是为了清理掉在第1次删除后、其他线程可能写入的旧数据。这个休眠时间需要根据业务读写耗时来估算。
优点:简单有效,能很大程度上解决并发读写导致的不一致。
缺点:降低了写入吞吐量,休眠时间难以精确设定。
方案二:通过消息队列异步删除
为了解耦和重试,可以将删除缓存的操作作为消息发送到消息队列(如 RocketMQ, Kafka)。
- 更新数据库。
- 向消息队列发送一条删除缓存的消息。
- 消费者消费该消息,执行删除 Redis 的操作。如果删除失败,消息会重试。
这保证了删除缓存的操作至少会被执行一次,大大提高了可靠性。
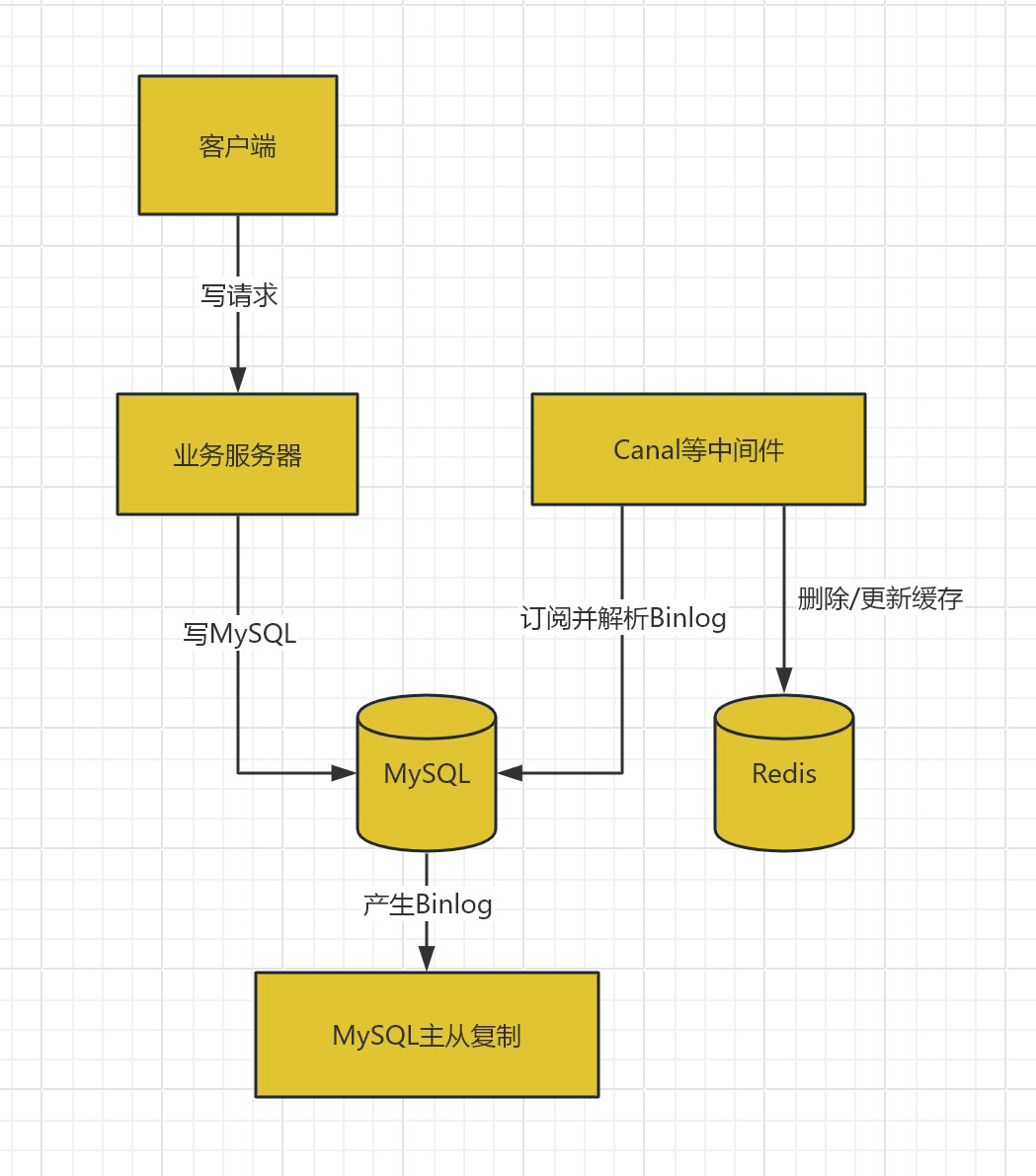
方案三:通过数据库 Binlog 同步(最优解)
这是目前最成熟、对业务侵入性最小、一致性最好的方案。其核心是利用 MySQL 的二进制日志(Binlog)进行增量数据同步。
工作原理:
- 业务系统正常写入 MySQL。
- 由一个中间件(如 Canal, Debezium)伪装成 MySQL 的从库,订阅 Binlog。
- 中间件解析 Binlog,获取数据的变更详情(增、删、改)。
- 中间件根据变更,调用 Redis 的 API 来更新或删除对应的缓存。
优点:
- 业务无侵入:业务代码只关心写数据库,完全不知道缓存的存在。
- 高性能:数据库和缓存的同步是异步的,不影响主业务链路的性能。
- 强保证:由于基于 Binlog,它能保证只要数据库变了,缓存最终一定会被同步。顺序也与数据库一致。
缺点:
- 架构复杂,需要维护额外的同步组件。
- 同步有毫秒级到秒级的延迟。
四、总结与最佳实践选择
策略 | 一致性保证 | 性能 | 复杂度 | 适用场景 |
Cache-Aside + 删除 | 最终一致性(有微弱不一致风险) | 高 | 低 | 绝大多数场景的首选,读多写少 |
Cache-Aside + 延迟双删 | 更好的最终一致性 | 中 | 低 | 对一致性要求稍高,且能接受一定延迟的写操作 |
Write-Through | 强一致性 | 中 | 中 | 写多读少,且对一致性要求非常高的场景 |
Binlog 同步 | 最终一致性(推荐) | 高 | 高 | 大型、高要求项目的最佳实践,对业务无侵入 |
通用建议:
- 首选方案:对于大多数应用,从 Cache-Aside(先更新数据库,再删除缓存) 开始。它简单、有效,在大多数情况下已经足够。
- 进阶保障:如果 Cache-Aside 的不一致窗口无法接受,可以引入延迟双删或消息队列异步删除来增强。
- 终极方案:当业务发展到一定规模,对一致性和系统解耦有更高要求时,投入资源搭建基于 Binlog 的异步同步方案。这是业界证明最可靠的方案。
- 设置合理的过期时间:无论如何,都给 Redis 中的缓存设置一个过期时间(TTL)。这是一个安全网,即使同步逻辑出现问题,旧数据也会自动失效,最终从数据库加载新数据,保证最终一致性。
- 业务容忍度:最重要的是,与产品经理确认业务对一致性的容忍度。很多时候,1-2秒内的数据不一致用户是感知不到的,不需要为此付出巨大的架构和性能代价。
总结
到此这篇关于MySQL与Redis如何保证双写一致性的文章就介绍到这了,更多相关MySQL与Redis保证双写一致性内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!