
MySQL覆盖索引与大分页详解
作者:言之。
这篇文章主要介绍了MySQL覆盖索引与大分页,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,望不吝赐教
核心知识点
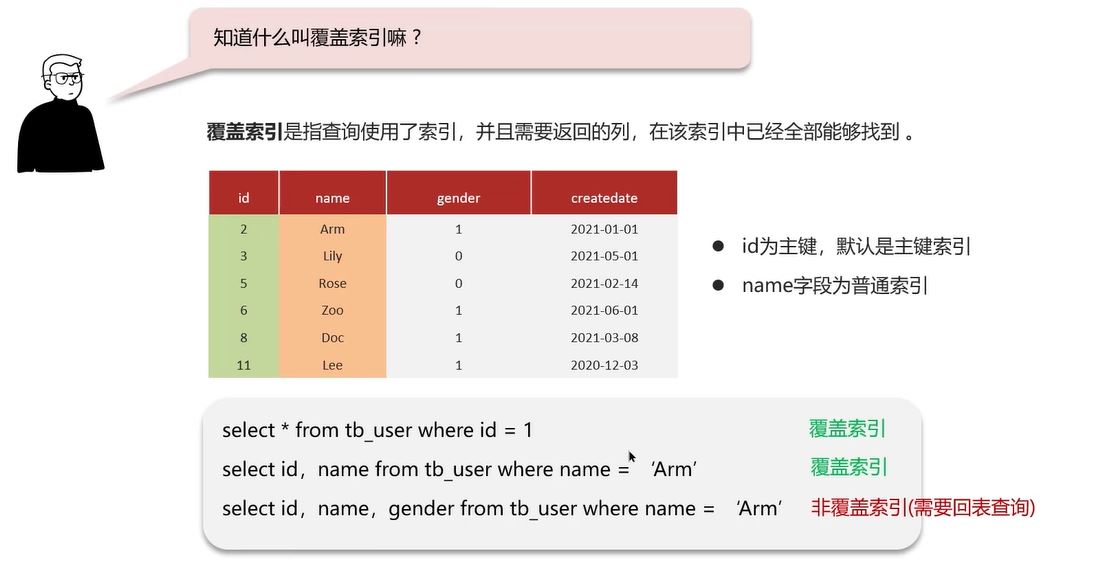
覆盖索引概念
查询使用了索引,且返回的列在该索引中能全部找到。
例如,对于主键索引(聚集索引),能一次性获取整行记录;对于普通索引,若返回列包含在该索引及主键值中,也算覆盖索引,否则可能需要回表查询。
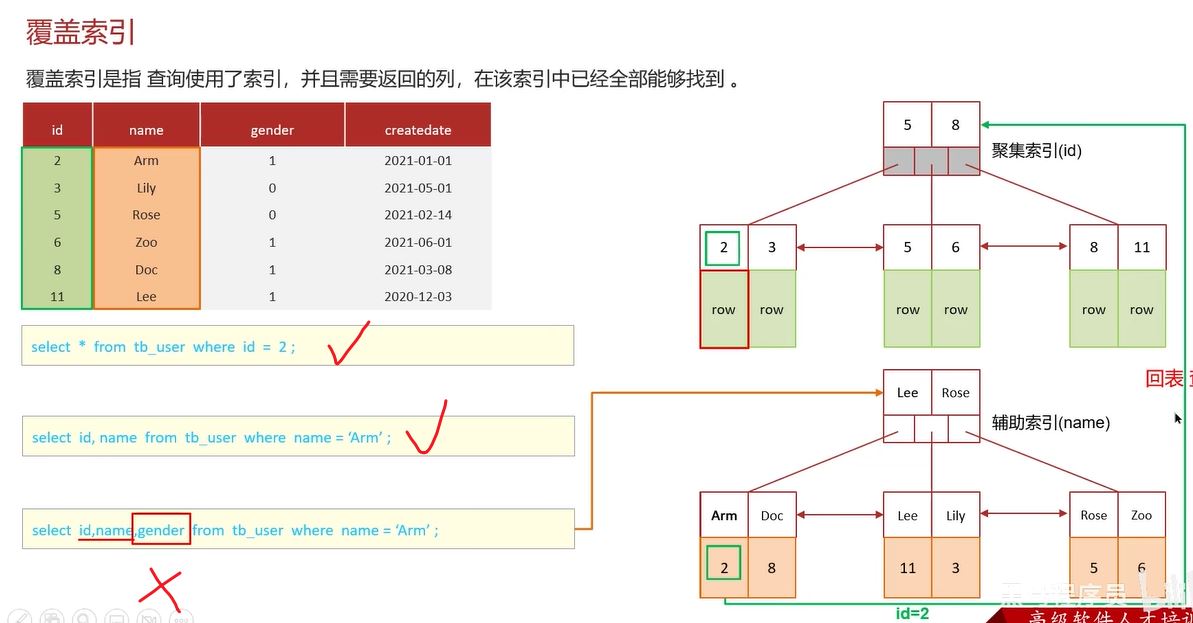
覆盖索引判断方法
根据查询条件所走的索引类型(聚集索引或二级索引),判断返回列是否都在该索引中。如根据id查询走聚集索引,返回所有列是覆盖索引;根据name查询走二级索引,若返回列只有id和name则是覆盖索引,若包含未在该二级索引中的列(如gender)则不是覆盖索引。
覆盖索引性能优势
一次性查询出所有数据,相比回表查询性能更高,所以在开发中应尽量避免使用“select *”,防止因返回列未创建索引而触发回表查询。

覆盖索引在MySQL超大分页问题中的应用

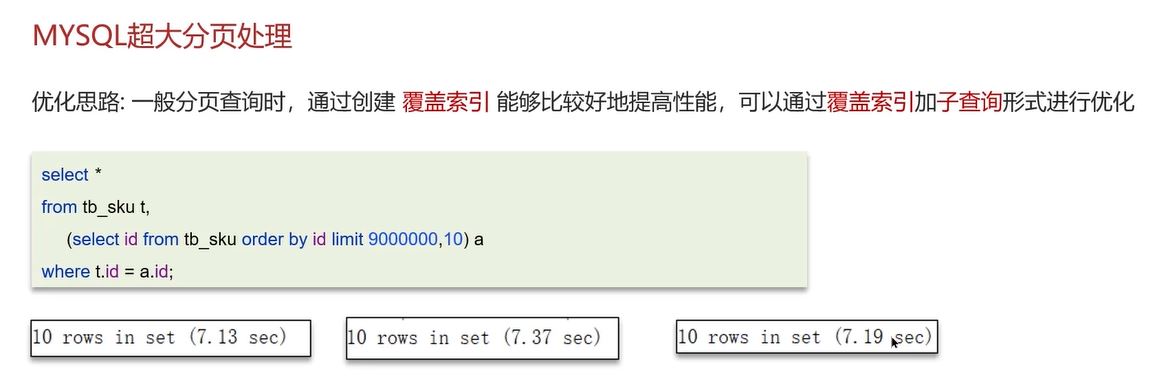
超大分页问题
当表数据量很大时,使用limit进行分页,越往后分页效率越低。如查询“limit 9000000, 10”,MySQL会排序前9000010条记录,但仅取十条,900多万条记录的排序代价高导致性能低。
解决方法
使用覆盖索引加子查询优化。先通过覆盖索引分页查询获取表中按id排序后的分页id集合(操作id效率高,因id是覆盖索引),再通过该id集合到原表做关联查询提升效率。
面试回答思路
- 覆盖索引定义解释:覆盖索引指查询使用索引且返回列都在索引中能找到,如根据id查询走聚集索引可一次获取所有数据。
- 开发中的注意事项:避免使用“select *”,防止因返回列未建索引触发回表查询影响性能。
- 超大分页问题阐述:说明表数据量大时用limit分页,越往后效率越低,如“limit 9000000, 10”的查询,MySQL会排序大量记录但仅取少量,导致性能低。
- 解决方案说明:用覆盖索引加子查询优化,先分页查询按id排序获取id集合,再用id集合关联原表查询提升效率。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。