
探讨MySQL 约束下的查询功能
作者:robin_suli
一. 数据库约束:
1.约束类型汇总:
| 约束类型 | 说明 |
| NULL约束 | 使用NOT NULL指定列不为 空 |
| UNIQUE唯一约束 | 指定列为唯一的、不重复的 |
| DEFAULT默认值约 束 | 指定列为空时的默认值 |
| 主键约束(primary key) | NOT NULL 和 UNIQUE 的 结合 |
| 外键约束 | 关联其他表的主键或唯一键 语法:foreign key (列) references 主表(列) |
| CHECK约束 | 保证列中的值符合指定的条件 |
1.1 NULL约束:
创建表时,可以指定某列不为空:
DROP TABLE IF EXISTS student; CREATE TABLE student ( id INT NOT NULL, sn INT, name VARCHAR(50), qq_mail VARCHAR(50) );
1.2 DEFAULT:默认值约束:
mysql> CREATE TABLE student (
-> id INT NOT NULL,
-> name VARCHAR(20) DEFAULT '默认为无名氏');
1.3 PRIMARY KEY:主键约束:
CREATE TABLE student2 (
-> id bigint primary key auto_increment,
-> name VARCHAR(20) DEFAULT '默认为无名氏');这里还使用了auto_increment,在插入时不指定,可以让id字段自增。
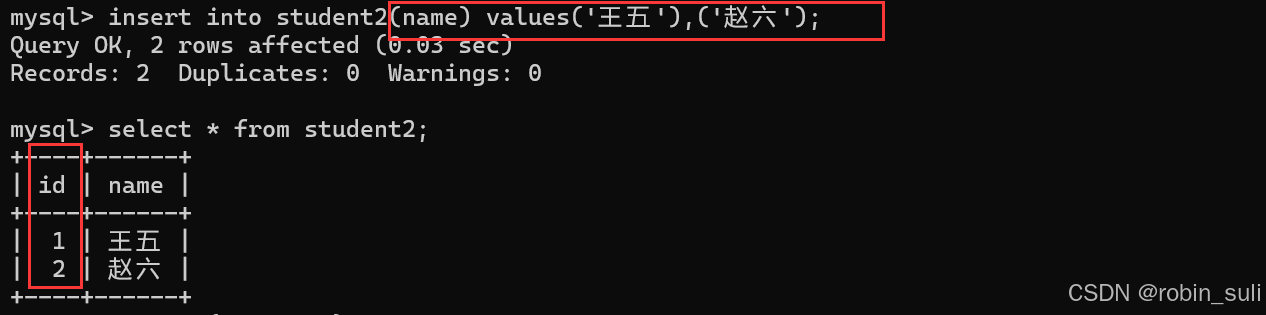
注意这里一个表不可以有多个主键,都是可以有复合主键
如下:
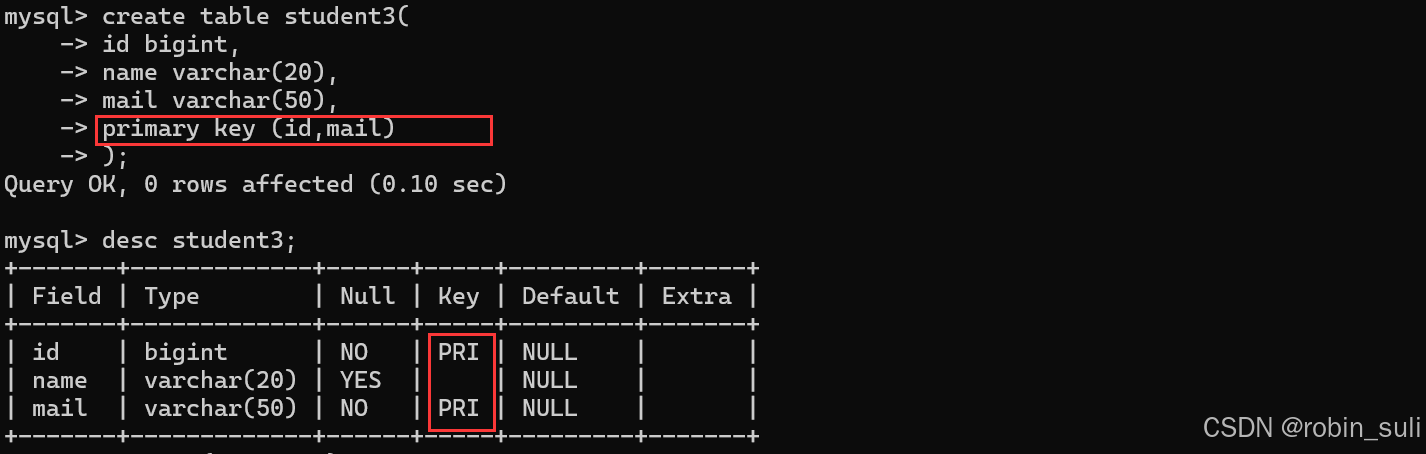
1.4 FOREIGN KEY:外键约束:
外键用于关联其他表的主键或唯一键
语法:
foreign key (本表要关联的字段) references 主表(列)
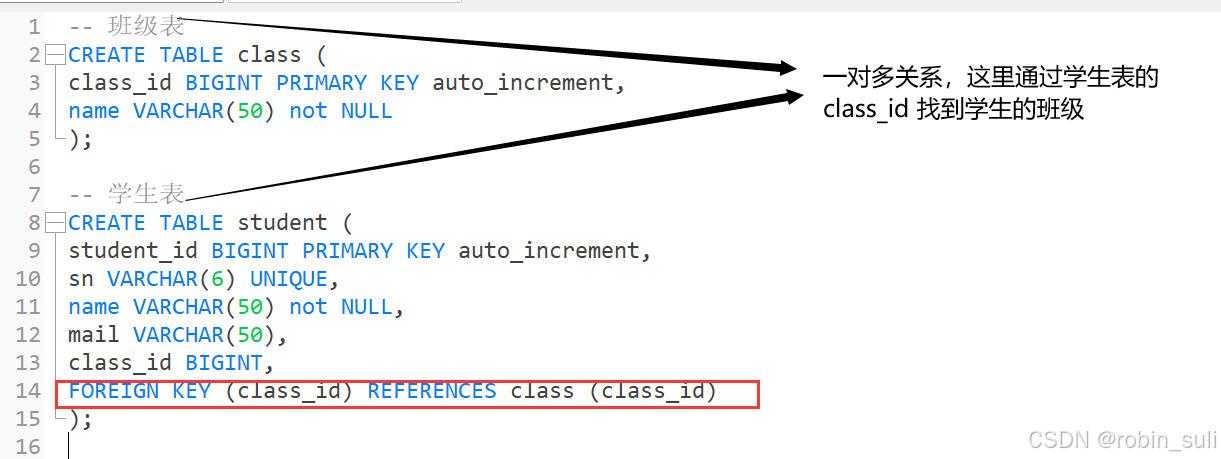
例子:创建班级表classes,id为主键;
创建学生表student,一个学生对应一个班级,一个班级对应多个学生。使用id为主键, classes_id为外键,关联班级表id。
create table student(
-> id INT PRIMARY KEY auto_increment,
-> class_id int,
-> foreign key (class_id) references class (id)
-> );
create table class(
-> id INT PRIMARY KEY auto_increment,
-> name varchar(50)
-> );
注意:这里的class_id的类型,要和主表class的id类型一致这里都是(int)
不然会报类型不兼容错误导致定义失败

二. 表的设计:
1.设计表的时候要遵循三大范式。
第一范式:表里的字段不可以再进行拆分
第二范式:再满足第一范式的基础上,不存在非关键字段对任意候选键的部分函数依赖
(简单来说就是非主键字段对任意主键,外键,唯一键的部分函数依赖)
小结:一个表没有复合主键就天然满足第二范式
第三范式:再满足第二范式的基础上,不存在非关键字段对任意候选键的传递依赖
第三范式可以解决数据冗余,更新异常,插入异常,删除异常等问题
2.设计时表之间的三大关系:
一. 一对一:比如用户和账号信息,可以建立在一个表中
二. 一对多:一个班级有多个学生设计如下:
三. 多对多:一个学生可以选多门课,一门课可以被多个学生选
学生表和课程表是多对多的关系,这里通过课程表(关系表)关联

三. 聚合查询:
1.常见的统计总数、计算平局值等操作,可以使用聚合函数来实现,常见的聚合函数有:
| 函数 | 说明 |
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
例子:
1.1COUNT:统计行数
统计班里有多少同学:

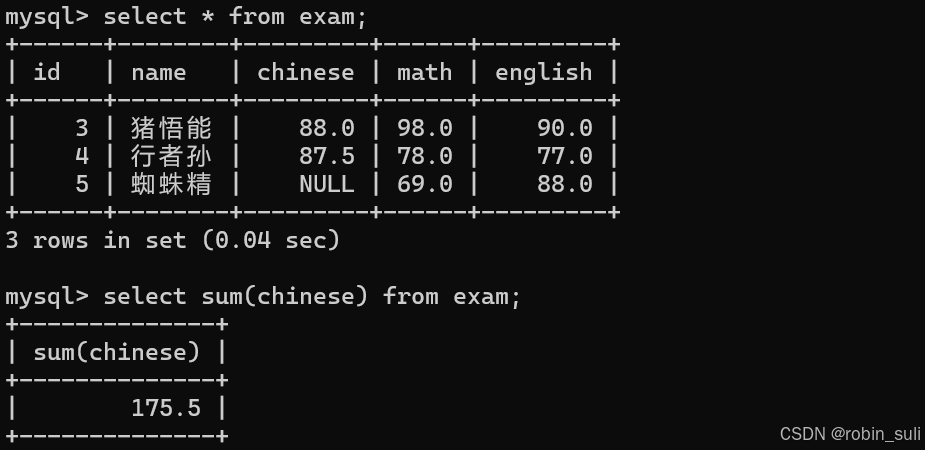
1.2 SUM:
统计语文成绩总分:
1.3 AVG:
统计语文平均分:

1.4 MAX:
语文最高分:
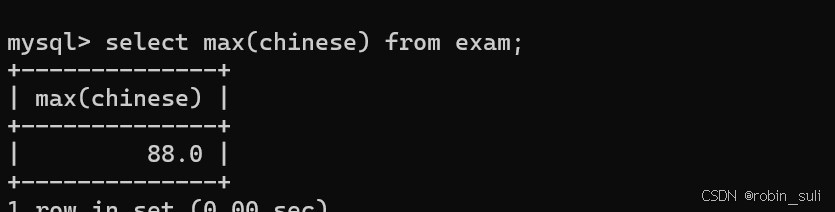
1.5 MIN
语文最低分:

2.GROUP BY子句:
2.1 SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函 数中。
2.2:语法:
select 需要分组的列, sum(column2), .. from table group by 需要分组的列
2.3:例子:
mysql> create table emp(
-> id int primary key auto_increment,
-> name varchar(20) not null,
-> role varchar(20) not null,
-> salary numeric(11,2)
-> );
Query OK, 0 rows affected (0.07 sec)
mysql> insert into emp(name, role, salary) values
-> ('马云','服务员', 1000.20),
-> ('马化腾','游戏陪玩', 2000.99),
-> ('孙悟空','游戏角色', 999.11),
-> ('猪无能','游戏角色', 333.5),
-> ('沙和尚','游戏角色', 700.33),
-> ('隔壁老王','董事长', 12000.66);
Query OK, 6 rows affected (0.04 sec)查询每个角色的最高工资:
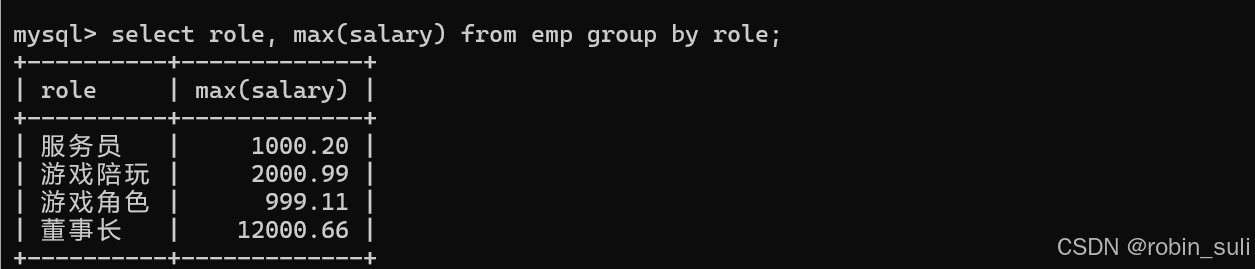
3.HAVING条件语句:
GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用 HAVING
例子:查询每个角色小于一万的最高工资:

四.联合查询:
1.实际开发中往往数据来自不同的表,所以需要多表联合查询。多表查询是对多张表的数据取笛卡尔积。
笛卡尔积其实是个全排列的过程
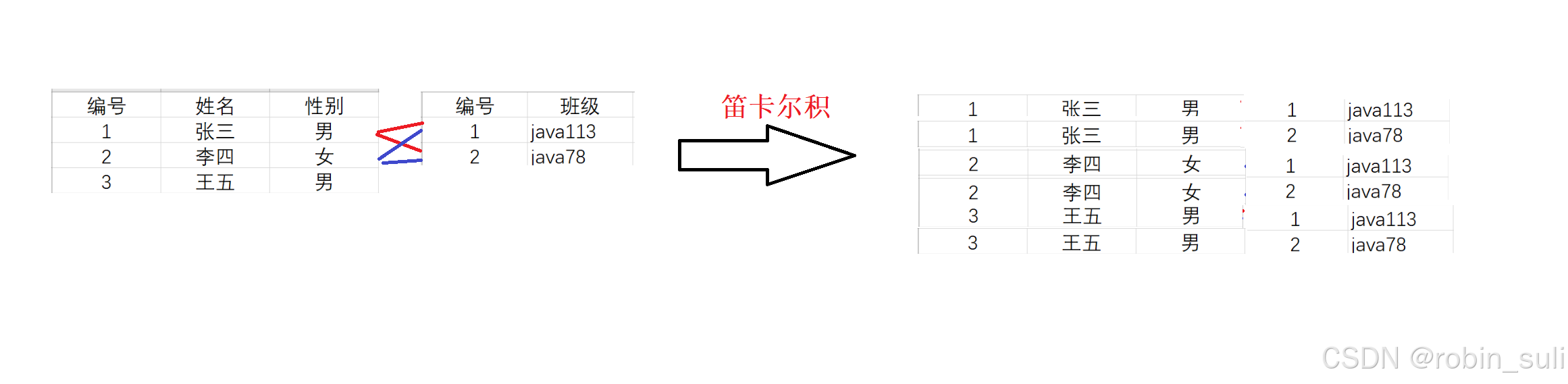
语法:
select * from 表名 表名
如图:
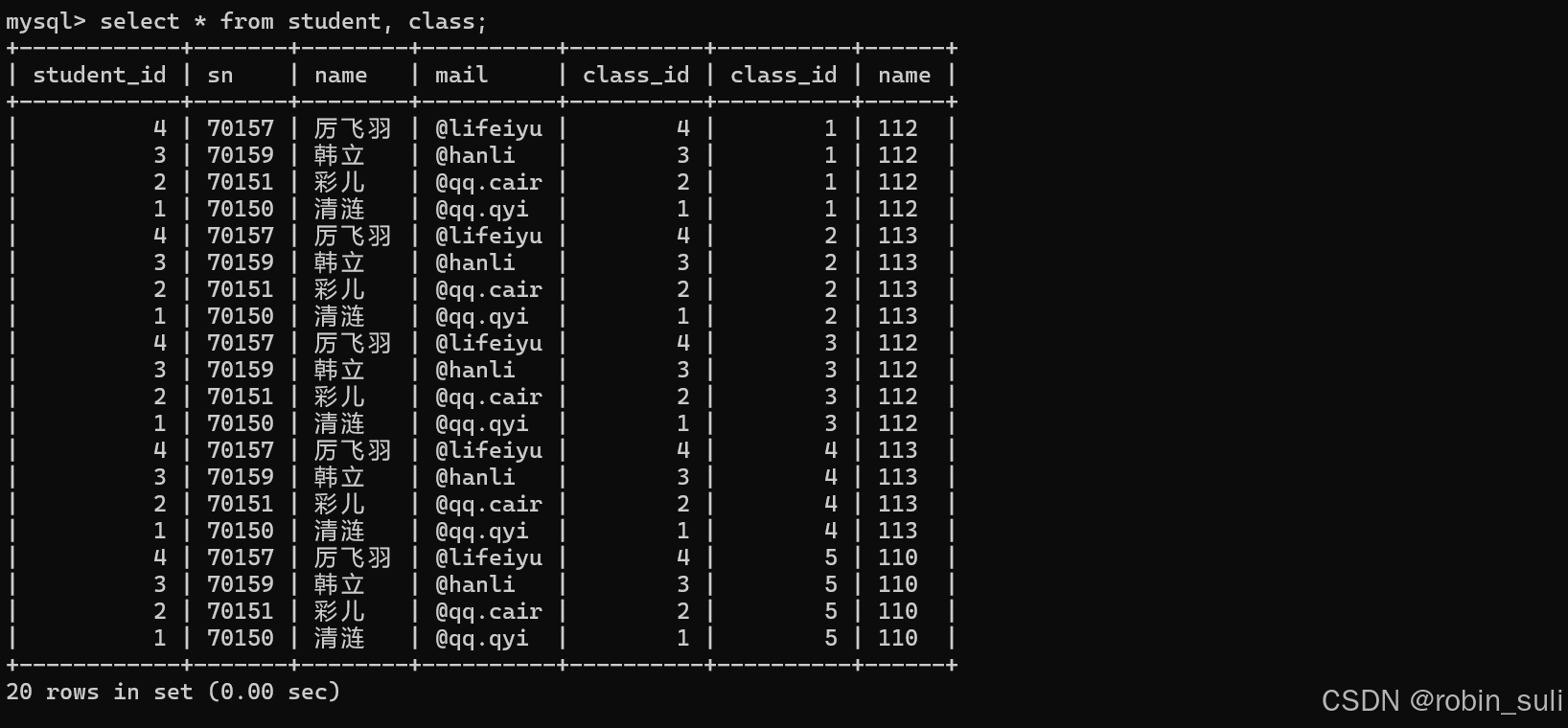
上面有很多无用数据,我们可以通过连接条件过滤
2.内连接:
写法一:select 字段 from 表1 别名1 join 表2 别名2 on 连接条件 and 其他条件;
写法二:select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
例子:这里我们过滤一下上面的class和student的查询
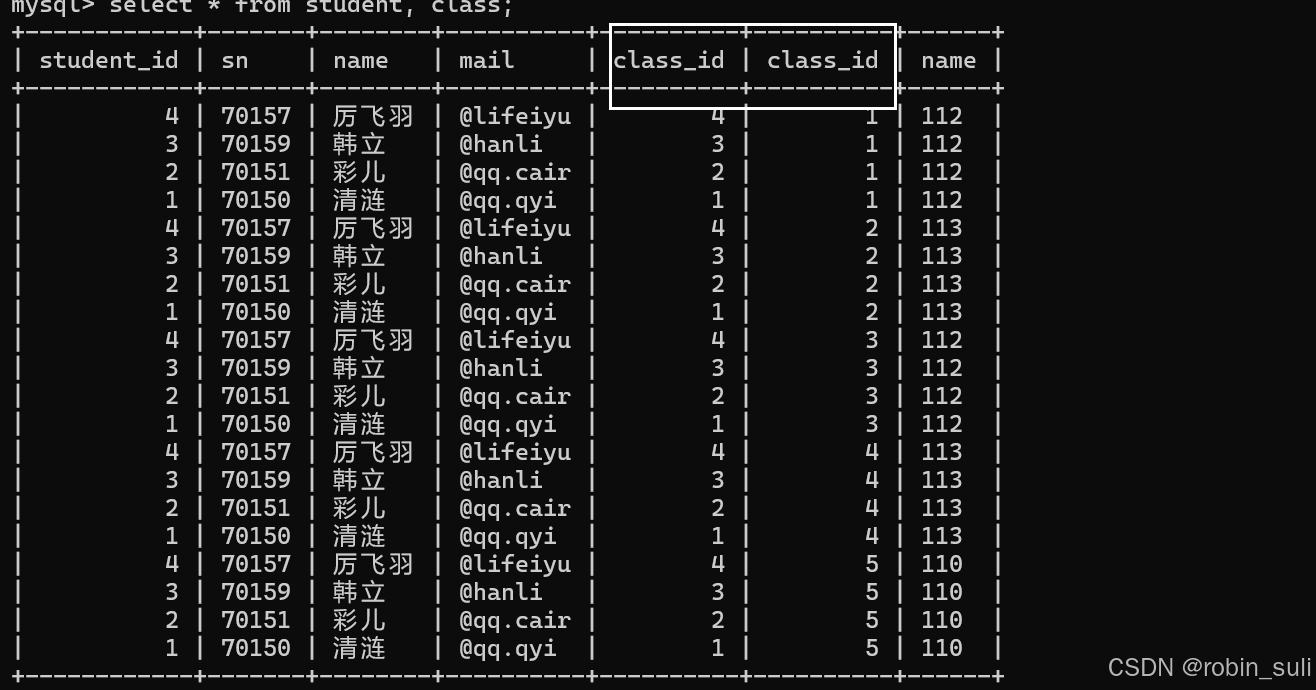
从图可以看出两个表的class_id有依赖关系,只要他们相等即可。
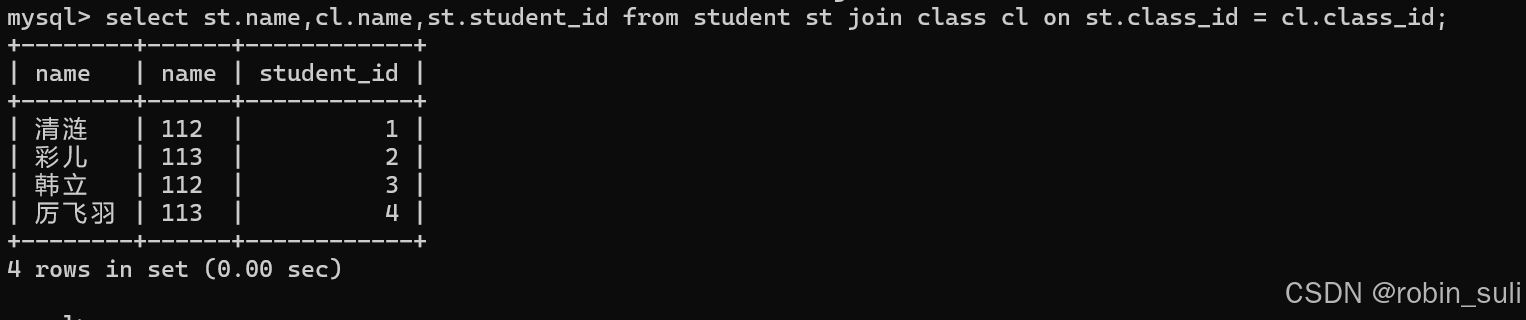
3.外连接:
外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完 全显示我们就说是右外连接
语法:
-- 左外连接,表1完全显示 select 字段名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示 select 字段 from 表名1 right join 表名2 on 连接条件;
如果是left join,就以左边的表为基准显示;
如果是right join ,就以右边的表为基准显示;
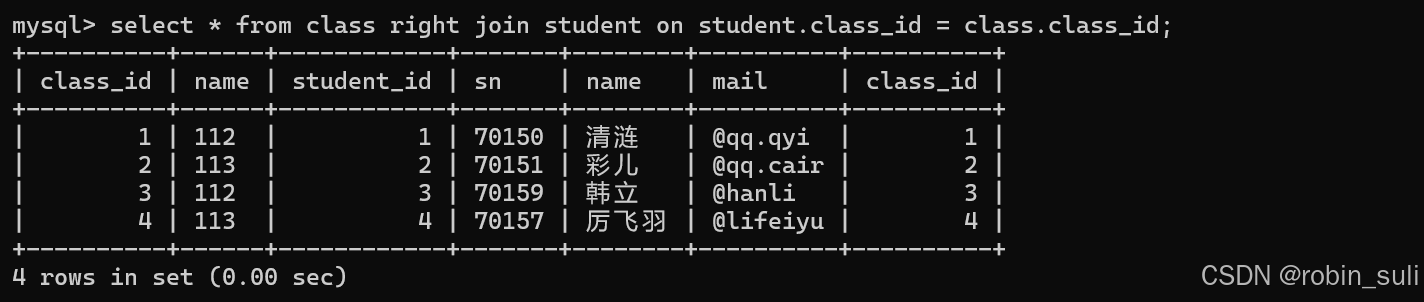
这里就是以右边student表为基准表显示的
4.自连接:
自连接是指在同一张表连接自身进行查询
5.子查询:
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询。
分为:
5.1.单行子查询:返回一行记录的子查询(返回一个对象)
例子:查询与“韩立” 同学的同班同学
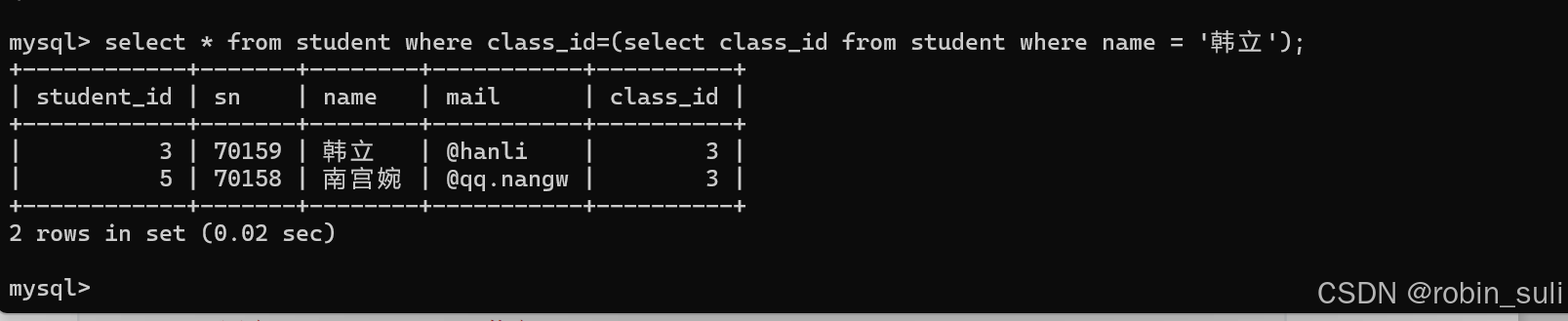
5.2.多行子查询:返回多行记录的子查询(返回一个集合,包含多个对象);用到IN关键字
例子:在成绩表中查询彩儿和清涟同学的成绩的成绩信息

6.合并查询:
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用UNION 和UNION ALL时,前后查询的结果集中,字段需要一致也就是两张表要完全一致。
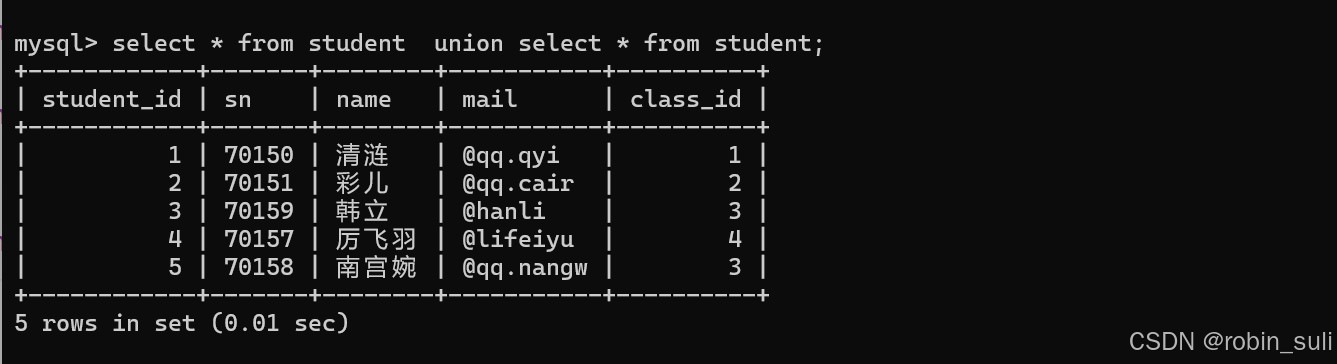
6.1 UNION:
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行
例子:
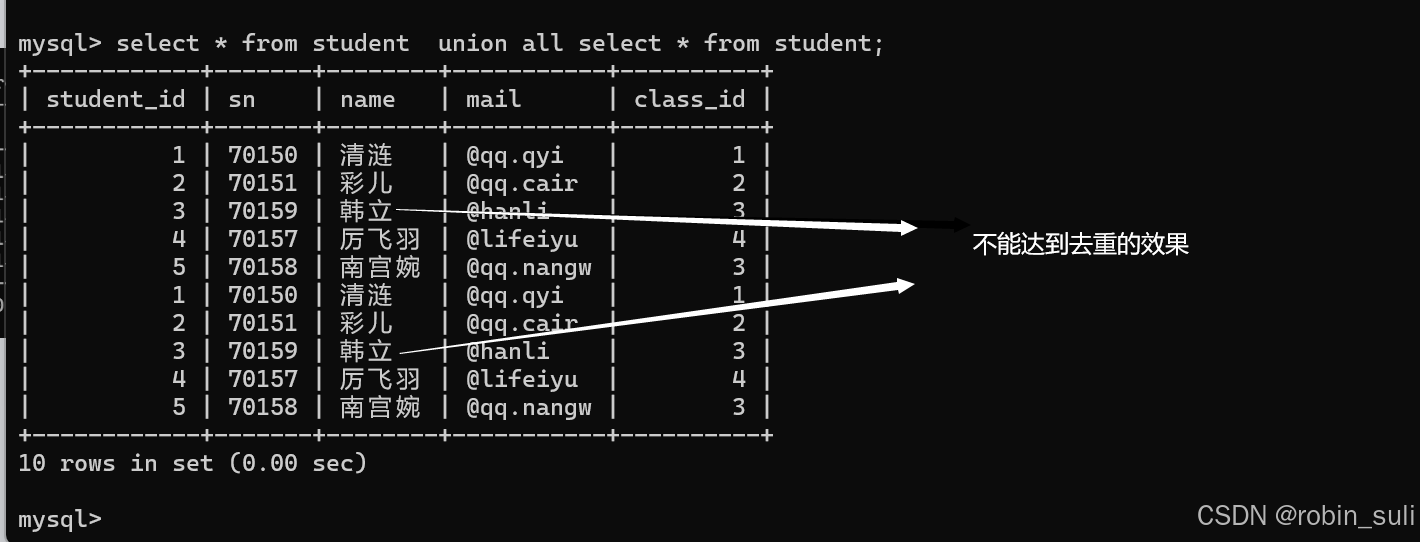
6.2.nion all:
到此这篇关于探讨MySQL中 “约束“ 下的查询的文章就介绍到这了,更多相关mysql约束查询内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!