
Mysql大表全表查询的全过程(分析底层的数据流转过程)
作者:it_lihongmin
Mysql大表全表查询
当我们需要对一整张大表的数据执行全量查询操作,比如select * from t 没有where条件,整个数据有几千万条占用内存大概 100G,而Mysql所在服务器的内存只有8G,那就不直接OOM,将整个数据库打崩了吗?
刚开始开发的时候会有这样的疑问,但是随着时间的推移知道是不会打崩的,但是为什么不会崩,慢慢地就没有好奇心了。
下面对整个流程进行分析,主要的冲击点就是Mysql和InnoDB,所以下面还是分成两个部分进行分析。
下面的分析同样适用于所有的查询流程,只是其他查询操作流程更复杂,但是数据量无论大小都会按照下面的流程执行。
查询整张表其实就是查询 主键聚簇索引的那棵B+树,比如查询的就是InnoDB 表 db1. t。
查询和返回按照java方式理解为 request和response流程,request查询流程可以理解为:Mysql架构图 ,即下面分析的是返回的流程:
1、Server层
Server层不会一次调用InnoDB存储引擎接口获取全量数据,也不是一次将所有数据发生给Mysql客户端,Mysql是边读边发送的,发送的过程中依赖两个缓存池:
- Mysql的 net buffer,由参数 net_buffer_length控制,默认大小为 16K;即一个查询不论返回结果多大,读Mysql的影响就是 net_buffer_length大小。
- 本地网络栈: Mysql服务器的 socket send buffer【默认配置在/proc/sys/net/core/wmem_default,当写满时,会暂停接受net buffer的数据】、 Mysql客户端的 socket receive buffer;
具体的查询执行流程如下:
- 获取一行,写到 net buffer 中。这块内存的大小是由参数 net_buffer_length 定义的,默认是 16k。
- 重复获取行,直到 net buffer 写满,调用网络接口发出去。
- 如果发送成功,就清空 net buffer,然后继续取下一行,并写入 net buffer。
- 如果发送函数返回 EAGAIN 或 WSAEWOULDBLOCK,就表示本地网络栈(socket send buffer)写满了,进入等待。直到网络栈重新可写,再继续发送。

并且在此数据查询过程当前,底层的表现就是Mysql服务端的socket send buffer 和 Mysql客户端 socket receive buffer,在不停的发生和接收数据包,因为底层是tcp协议。
而从表象上看,执行 show processlist,查询到的结果为 Sending to client,所以不能简单的理解成发生数据给客户端,仅仅表示服务器端的网络栈写满了。

2、innoDB层
在前面博客分析了InnoDB的架构图,分为内存和磁盘架构。内存架构中最大的一块儿内存就是 Buffer Pool,可以占用到物理内存的 60~80%。
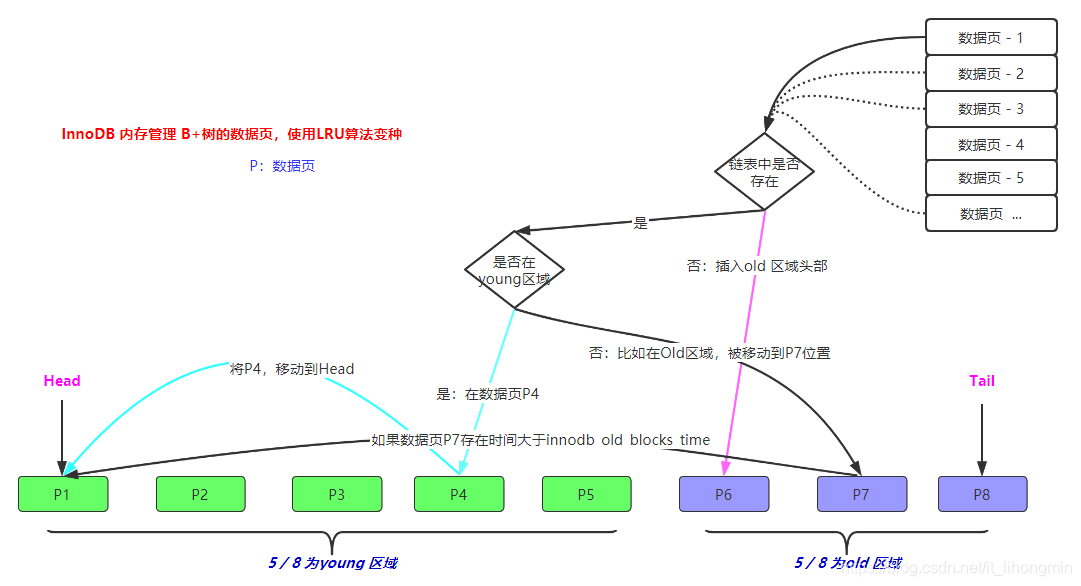
并且分析了针对当前这种大表查询流程,会将所有的B+树缓存页都在变种的 LRU缓存队列中过一遍。
所以Mysql将缓存链表分成young和old区,使用配置参数 innodb_old_blocks_time控制缓存页真正加入的young取余的条件。
即大表查询流程对innodb层的影响就是,将所有主键聚簇索引B+树上的页,全部在 Buffer Pool内部的 LRU链的 old区域全部执行一遍,当超过内存大小限制时,再从 old链的尾部出队列。流程图如下:
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。