
Redis如何解决BigKey
作者:Seapp
一 面试题引入
- 阿里广告平台,海量数据里查询某一固定前缀的key。
- 小红书,你如何在生产上限制keys * / flushdb / flushall等危险命令以防止误删误用?
- 美团:MEMORY USAGE 命令你用过吗?
- BigKey 问题,多大算big,如何发现,如何删除,如何处理?
- BigKey 你做过调优吗?惰性释放lazyfree了解过吗?
- Morekey问题,生产上redis数据库有1000W记录,该如何遍历?key*可以吗?
二 MoreKey案例
2.1 大批量往redis里面插入2000W测试数据key
2.1.1 Linux Bash下执行,插入100W
for((i=1;i<=100*10000;i++)); do echo "set K$i V$i" >> /tmp/redisTest.txt ; done;
2.1.2 通过redis提供的管道 --pipe命令插入100W大批量数据
cat /tmp/redisTest.txt | /opt/redis-7.0.0/src/redis-cli -h 127.0.0.1 -p 6379 -a 111111 --pipe
2.2 key *
key * 这个指令有致命的弊端,在实际环境中最好不要使用
这个指令没有offset、limit参数,是要一次性吐出所有满足条件的key,由于redis是单线程的,其所有操作都是原子的,而keys算法是遍历算法,复杂度是O(n),如果实例中有千万级以上的key,这个指令就会导致Redis服务卡顿,所有读写Redis的其它的指令都会被延后甚至会超时报错,可能会引起缓存雪崩甚至数据库宕机。
2.3 生产上如何限制keys*/flushdb/flushall等危险命令以防止误删误用?
通过配置设置禁用这些命令,redis.conf在SECURITY这一项中:

2.4 不用keys * 不满卡顿,那该用什么?
2.4.1 scan命令
类似mysql limit ,但不完全相同。
Redis SCAN命令及其相关命令 SSCAN,HSCAN,ZSCAN命令都是用于增量遍历集合中的元素。
- SCAN:用于迭代当前数据库中的数据库键
- SSCAN:用于迭代集合键中的元素
- HSCAN:用于迭代哈希键中的键值对
- ZSCAN:用于迭代有序集合中的元素(包括元素成员和元素分值)
2.4.2 scan命令用于迭代数据库中的数据库键
redis SCAN 命令基本语法如下:
SCAN cousor [MATCH pattern] [COUNT count]
- cursor:游标
- pattern:匹配的模式
- count:指定从数据集里返回多少元素,默认值是10

基于游标的迭代器,需要基于上一次的游标延续之前的迭代过程以0作为游标开始一次新的迭代,直到命令返回游标0完成一次遍历,不保证每次执行都返回某个给定数量的元素,支持模糊查询。一次返回的数量不可控,只能是大概率符合count参数。
- SCAN命令是一个基于游标的迭代器,每次被调用之后,都会想用户返回一个新的游标,用户在下次迭代时需要使用这个新游标作为SCAN命令的游标参数,以此来延续之前的迭代过程。
- SCAN返回一个包含两个元素的数组
- 第一个元素:用于进行下一次迭代的新游标
- 第二个元素:是一个数组,这个数组中包含了所有被迭代的元素。如果新游标返回零表示迭代已结束。
SCAN的遍历顺序:非常特别,它不是从第一维数组的第零位一直遍历到末尾,而是采用了高位进位加法来遍历,之所以使用这样特殊的方式进行遍历,是考虑到字典的扩容和缩容时避免槽位的遍历重复和遗漏。
三 BigKey
3.1 多大算Big
- 阿里云Redis开发规范:
拒绝bigkey(防止网卡流量,慢查询)
string类型控制在10KB以内,hash、list、set、zset元素个数不要超过5000。
非字符串的bigkey,不要使用del删除,使用hscan、sscan、zscan方式渐进式删除,同时要注意防止bigkey过期时间自动删除问题(例如一个200万的zset设置1小时过期,会触发del操作,造成阻塞,而且该操作不会出现在慢查询中(latency可查))。
- string和二级结构
- string是value,最大512MB 但是大于10KB就是bigkey。
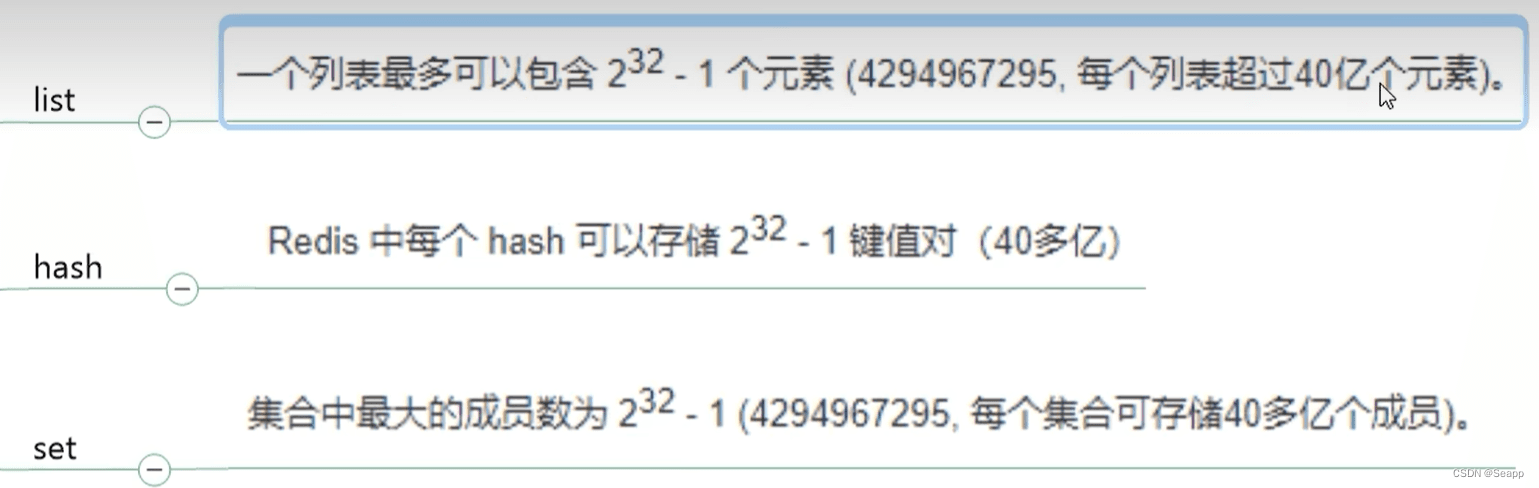
- list/hash/set和zset,个数超过5000就是bigkey

3.2 bigkey的危害
- 内存不均,集群迁移困难
- 超时删除,大key删除作梗
- 网络流量阻塞
3.3 如何产生
- 社交类:典型案例粉丝逐步递增
- 汇总统计:某个报表,月日年的积累
3.4 如何发现
redis-cli --bigkeys
- 好处:给出每种数据结构Top 1 bigkey,同时给出每种数据类型的键值个数 + 平均大小
- 不足:想查询大于10KB的所有key,–bigkeys参数就无能为力了。
需要用到memory usage来计算每个键值的字节数


MOMROY USAGE :给出一个key和它的值在RAM中所占用的字节数(计算每个键值的字节数)。
3.5 如何删除
非字符串的bigkey,不要使用del删除,使用hscan、sscan、zscan方式渐进式删除。
- string:一般用del,如果过于庞大使用unlink
- hash:使用hscan每次获取少量field-value,再使用hdel删除每个field

list:使用ltrim渐进式逐步删除,直到全部删除完成。
Ltrim对一个列表进行修剪(trim),就是说,让列表只保留指定区域内的元素,不在指定区间之内的元素都将被删除。下标0表示列表的第一个元素,以1表示列表的第二个元素,以此类推。也可以使用负数下标,以-1表示列表的最后一个元素,-2表示列表的倒数第二个元素,以此类推。
语法:LTRIM key_NAME START STOP

set:使用sscan每次获取部分元素,再使用srem命令删除每个元素

zset:使用zscan每次获取部分元素,再使用ZREMRANGEBYRANK命令删除每个元素

四 BigKey生产调优
在redis.conf配置文件LAZY FREEING相关说明:


到此这篇关于Redis如何解决BigKey的文章就介绍到这了,更多相关Redis BigKey内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!