
解读索引列中有null值会不会使索引失效
作者:zyjzyjjyzjyz
先说答案
null不会使索引失效,但是会影响优化器对执行计划的选择。
网上很多都说null会导致索引失效,这么说并不严谨。先看实验。
注意:
- count(列)不会把空值算进去。
- distance 列 如果列中有null会把列当成一行输出。
- count(*)会把null值算进去。
实验1
create table null_test( id int PRIMARY KEY, name VARCHAR(10), age VARCHAR(10), KEY inx_test_age(age), KEY inx_test_name(name) ) insert into null_test values(1,'a','2'); insert into null_test values(2,'b','3'); insert into null_test values(3,'c','4'); insert into null_test values(4,'d','5'); insert into null_test values(5,null,'6'); insert into null_test values(6,null,'6'); insert into null_test values(7,null,'9'); insert into null_test values(8,'q',null); insert into null_test values(9,'','5'); insert into null_test values(10,'','7'); insert into null_test values(11,'t','');
创建null_test表,并在name、age列上建普通索引,插入null值。
explain select * from null_test where name is null;

可以看到name is null走了索引,并且type是ref,这是普通索引的等职查询才会有的。
对于explain的详解:explain性能详细分析
explain select * from null_test where name is not null;

可以看到name is not null确实没有走索引,而是全表扫描。这意味着导致索引失效吗?往下看。
实验2
create table null_test2( id int PRIMARY KEY, name VARCHAR(10), age VARCHAR(10), KEY inx_test2_age(age), KEY inx_test2_name(name) ) insert into null_test2 values(1,'a','2'); insert into null_test2 values(2,'b','3'); insert into null_test2 values(3,'c','4'); insert into null_test2 values(4,'d','5'); insert into null_test2 values(5,null,'6'); insert into null_test2 values(6,null,'6'); insert into null_test2 values(7,null,'9'); insert into null_test2 values(8,null,'6'); insert into null_test2 values(9,null,'6'); insert into null_test2 values(10,null,'9'); insert into null_test2 values(11,null,'9'); insert into null_test2 values(12,null,'6'); insert into null_test2 values(13,null,'6'); insert into null_test2 values(14,null,'9');
创建null_test2表,插入很多null值。
explain select * from null_test2 where name is null;

可以看到和上面的条件都是相同的,但是却是走了全表扫描,还没想明白?接着往下看。
explain select * from null_test2 where name is not null;

可以看到name is not null走了索引,和上面的情况正好相反,这是什么情况?
- 其实这和普通索引上的情况相同,我们把null值当成正常的值,mysql默认认为null是相同的,所以重复率特别高的话,优化器肯定不会走索引,而是走全表扫描。
- 还要注意一点,is null时type=ref,is not null时type=range。
实验3
create table null_test3( id int PRIMARY KEY, name VARCHAR(10), age VARCHAR(10), KEY inx_test2_age(age), UNIQUE KEY inx_test2_name(name) ) insert into null_test3 values(1,'a','2'); insert into null_test3 values(2,'b','3'); insert into null_test3 values(3,'c','4'); insert into null_test3 values(4,'d','5'); insert into null_test3 values(5,null,'6'); insert into null_test3 values(6,null,'6'); insert into null_test3 values(7,null,'9'); insert into null_test3 values(8,null,'6'); insert into null_test3 values(9,null,'6'); insert into null_test3 values(12,'q',null); insert into null_test3 values(13,'','5'); insert into null_test3 values(10,'g','7'); insert into null_test3 values(11,'t','');
explain select * from null_test3 where name is null;

explain select NAME from null_test3 where name is null;

可以看到唯一索引也可以插入多个null,并且null就在索引上,因为使用索引就可以查到。
总结
上面我说过mysql内部认为null是相等的,所以导致当插入过多null值,造成重复率过多,is null不会走索引。而is not null因为查询的结果过多,优化器选择了全表扫描。
什么原因让mysql认为null是相等的:
其实是有个参数控制的。
innodb_stats_method
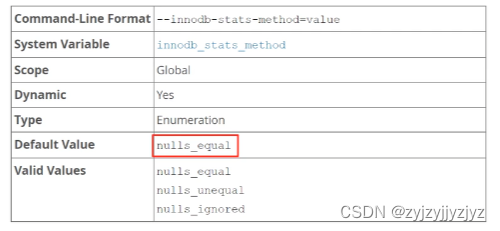
show variables like 'innodb_stats_method'; SET GLOBAL innodb_stats_method=nulls_unequal;
该参数有三个值,默认为nulls_equal
1、null_equal:认为所有的null值都是相等的,也是默认值,这种统计方式,会让优化器认为某个列中的平均一个值的重复次数特别多,倾向于不适用索引去访问。
2、nulls_unequal:认为所有的null值都不相等,这种统计方式,会让优化器认为某个列中的平均一个值的重复次数特别少,更倾向于使用索引去访问。
3、nulls_ignored:直接忽略null
在mysql5.7.2版本之后,mysql将这个值写死为nulls_equal
好了,以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。