
MySQL的核心查询语句详解
作者:打工人户户
本文数据分析师必看! 上次讲了数据库和MySQL基础,这回咱们来学点MySQL最常用到的—核心查询语句。
框住的部分是本节重点
一、单表查询
SELECT 字段名 FROM 表名 WHERE 条件 [GROUP BY 字段名 HAVING 条件 ORDER BY 字段名 LIMIT 条数];
1、排序
- 单列排序
- asc升序(默认,可不写),desc降序
- 语法格式:
SELECT 字段名 FROM 表名 [WHERE 字段 = 值] ORDER BY 字段名 [ASC / DESC]
- 组合排序
- 同时对多个字段进行排序, 如果第一个字段相同就按照第二个字段进行排序,以此类推。
- 比如order by 字段1,字段2 desc—代表先按照字段1升序,再按字段2降序。
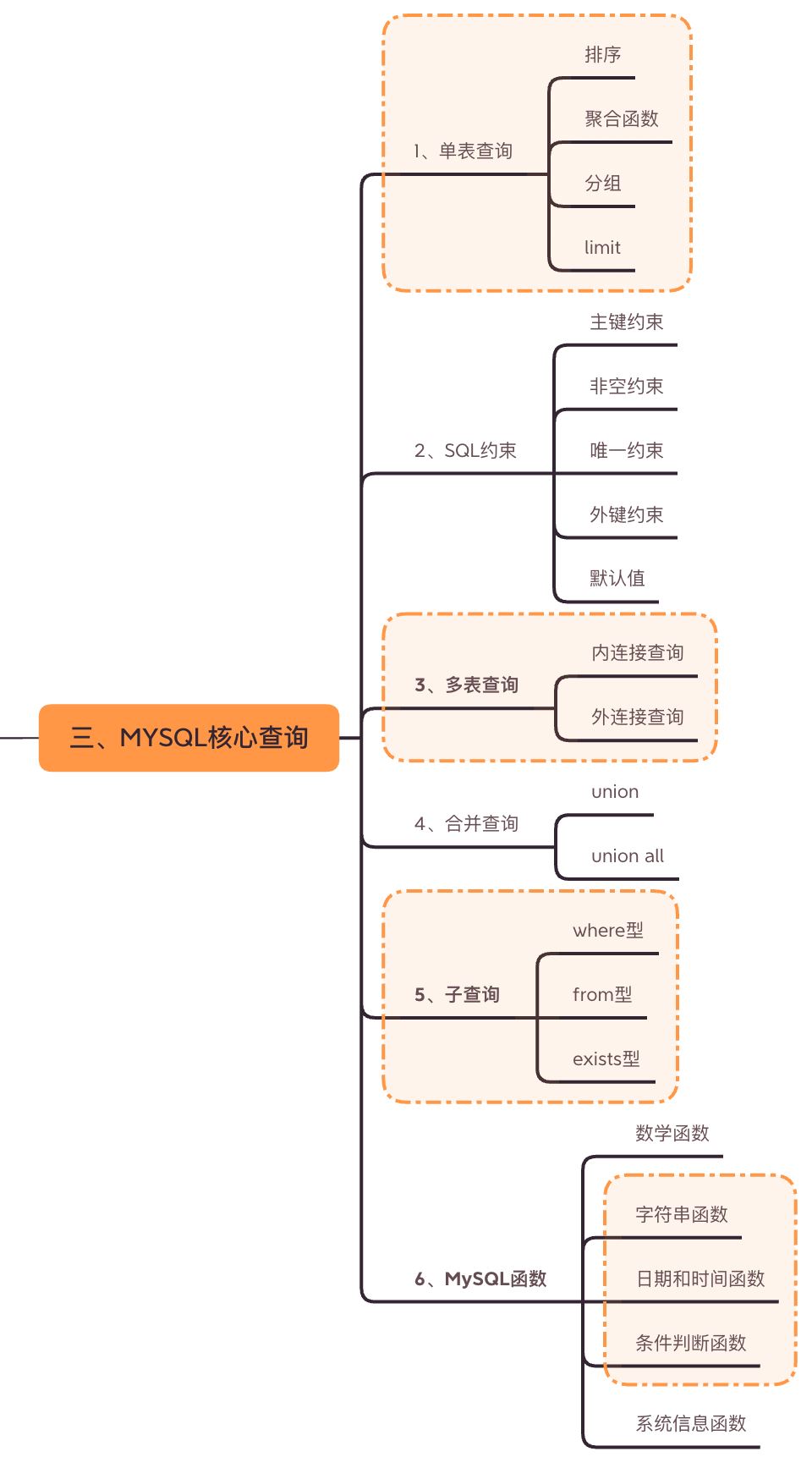
2、聚合函数
#1 查询员工的总数 -- 统计表中的记录条数 使用count() SELECT COUNT(eid) FROM emp; -- 使用某一个字段 SELECT COUNT(*) FROM emp; -- 使用 * SELECT COUNT(1) FROM emp; -- 使用 1,与 * 效果一样 -- 下面这条SQL 得到的总条数不准确,因为count函数忽略了空值 -- 所以使用时注意不要使用带有null的列进行统计 SELECT COUNT(dept_name) FROM emp; #2 查看员工总薪水、最高薪水、最小薪水、薪水的平均值 -- sum函数求和, max函数求最大, min函数求最小, avg函数求平均值 SELECT SUM(salary) AS '总薪水', MAX(salary) AS '最高薪水', MIN(salary) AS '最低薪水', AVG(salary) AS '平均薪水' FROM emp;
count(1)count(*)count(列名)的区别: count(1)和count(*)统计所有条数,包括null值; count(列名)统计所有不为null的条数。
3、分组
分组往往和聚合函数一起使用,对数据进行分组,分完组之后在各个组内进行聚合统计分析。 语法格式:
SELECT 分组字段/聚合函数 FROM 表名 GROUP BY 分组字段 [HAVING 条件];
代码示例:
#1.查询每个部门的平均薪资 SELECT dept_name AS '部门名称', AVG(salary) AS '平均薪资' FROM emp GROUP BY dept_name; #2.查询每个部门的平均薪资, 部门名称不能为null SELECT dept_name AS '部门名称', AVG(salary) AS '平均薪资' FROM emp WHERE dept_name IS NOT NULL GROUP BY dept_name;
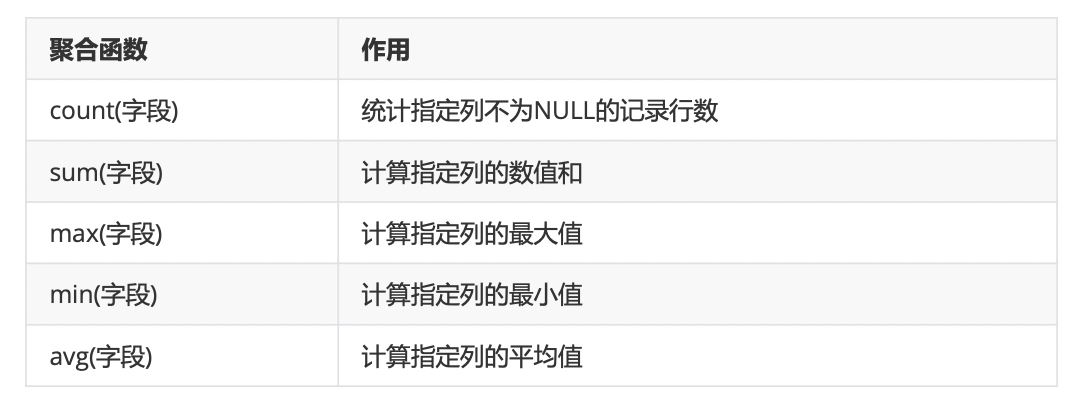
having的用法:
# 查询平均薪资大于6000的部门 -- 需要在分组后再次进行过滤,使用 having SELECT dept_name , AVG(salary) FROM emp WHERE dept_name IS NOT NULL GROUP BY dept_name HAVING AVG(salary) > 6000 ;
where 与 having 的区别:
having要放在where和分组之后
4、limit
语法格式:
SELECT 字段1,字段2... FROM 表名 LIMIT offset,length;
参数说明: offset起始行数,从0开始记数,如果省略则默认为0。 length返回的行数。
# 查询emp表中的前5条数据 SELECT * FROM emp LIMIT 5; SELECT * FROM emp LIMIT 0,5; # 查询emp表中从第4条开始,查询6条 -- 起始值默认是从0开始的 SELECT * FROM emp LIMIT 3,6;
二、SQL约束
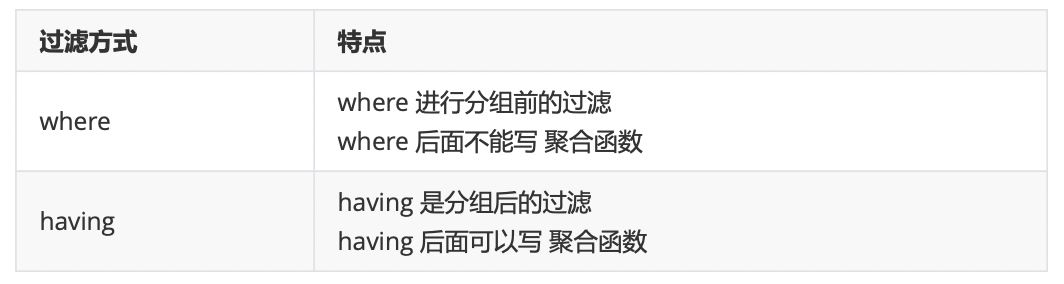
约束的作用: 对表中的数据进行进一步的限制,从而保证数据的正确性、有效性、完整性。 违反约束的不正确数据将无法插入到表中。注意:约束是针对字段的。
一般数据分析师对数据只是查询,基本没有创建修改表的权限,所以这块大家了解就好,不用纠结语法怎么写。在表结构中见到以下约束关键字,知道是对数据的约束就行了。
常见的四种约束
1、主键约束
特点:不可重复、唯一、非空
创建主键
# 方式1 创建一个带主键的表 CREATE TABLE emp2( -- 设置主键 唯一 非空 eid INT PRIMARY KEY, ename VARCHAR(20), sex CHAR(1) ); -- 方式2 创建一个带主键的表 CREATE TABLE emp3( eid INT , ename VARCHAR(20), sex CHAR(1), -- 指定主键为 eid字段 PRIMARY KEY(eid) );
增加主键
-- 创建的时候不指定主键,然后通过DDL语句进行设置 ALTER TABLE emp2 ADD PRIMARY KEY(eid);
2、非空约束
3、唯一约束
4、外键约束
主键:数据表A中有一列,这一列可以唯一的标识一条记录。 外键:数据表A中有一列,这一列指向了另外一张数据表B的主键。
5、默认值
-- 表示性别这字段,若没有数据则会默认填女,若有数据则显示该数据。 CREATE TABLE emp4( eid INT PRIMARY KEY AUTO_INCREMENT, ename VARCHAR(20), sex CHAR(1) DEFAULT '女' );
三、多表查询
数据分析师在实际工作中提取数据,不可能在一张表中就能把所有想要的数据都取到,而是关联多张表,从不同的表中拿到不同的目标数据,这就需要掌握表和表连接的知识了。这块非常重要!!!
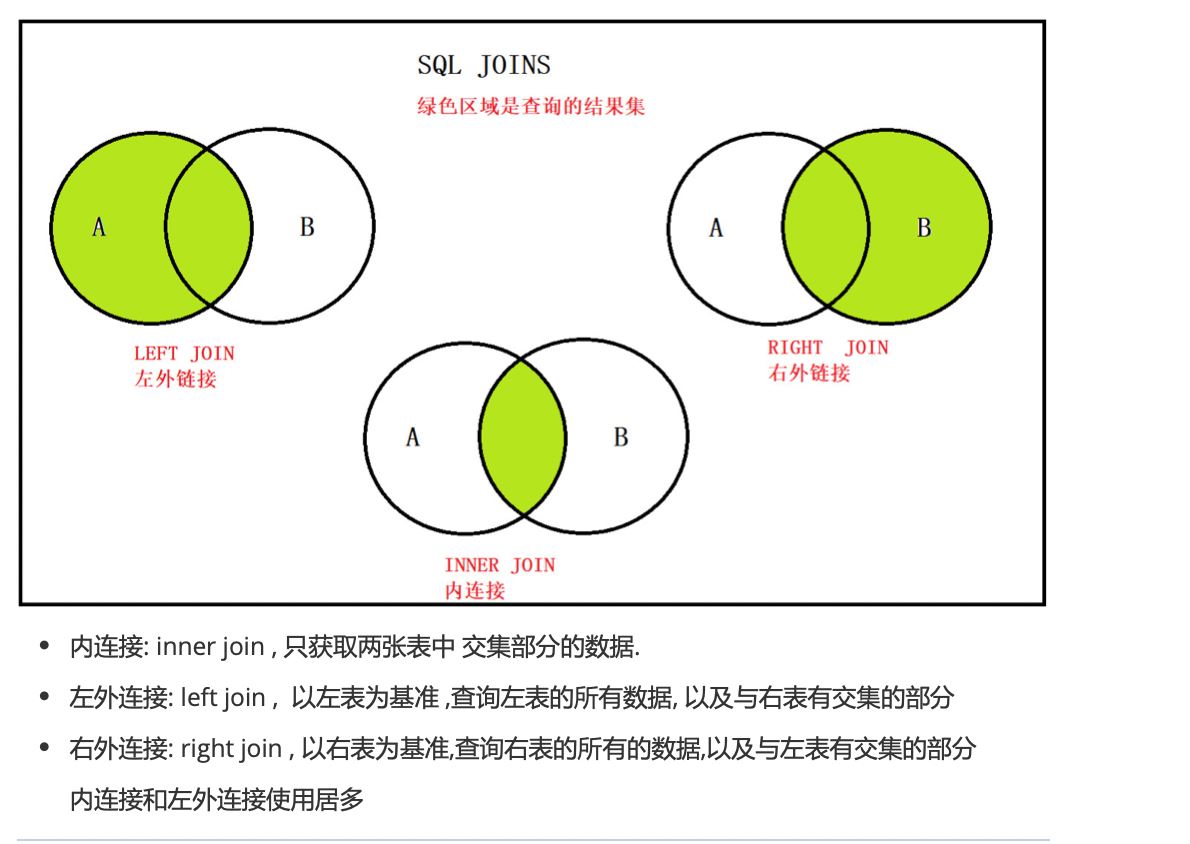
1、内连接
**特点:**通过指定的条件去匹配两张表中的数据,匹配上就显示,匹配不上就不显示。
1)隐式内连接:
SELECT 字段名 FROM 左表, 右表 WHERE 连接条件;
示例代码:
SELECT
p.pname,
p.price,
c.cname
FROM products p , category c
WHERE p.category_id = c.cid;2)显式内连接:
SELECT 字段名 FROM 左表 [INNER] JOIN 右表 ON 条件 -- inner 可以省略
示例代码:
SELECT * FROM products p INNER JOIN category c ON p.category_id = c.cid;
2、外连接
1)左外连接
特点: 以左表为基准,匹配右边表中的数据,如果匹配的上就展示匹配到的数据; 如果匹配不到,左表中的数据正常展示,右边的展示为null。
语法格式:
SELECT 字段名 FROM 左表 LEFT [OUTER] JOIN 右表 ON 条件
示例代码:
-- 左外连接查询 SELECT * FROM category c LEFT JOIN products p ON c.cid= p.category_id;
2)右外连接
特点: 以右表为基准,匹配左边表中的数据,如果匹配的上就展示匹配到的数据; 如果匹配不到,右表中的数据正常展示,左边的展示为null。
语法格式:
SELECT 字段名 FROM 左表 RIGHT [OUTER ]JOIN 右表 ON 条件
示例代码:
-- 右外连接查询 SELECT * FROM products p RIGHT JOIN category c ON p.category_id = c.cid;
各种连接方式的总结:
四、合并查询
1、UNION
UNION 操作符用于合并两个或多个SELECT语句的结果集,并消除重复行。 注意,UNION内部的SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。 同时,每条 SELECT 语句中的列的顺序必须相同。
代码示例:
SELECT id,name,amount,date FROM customers LEFT JOIN orders on customers.Id = orders.customers_id UNION SELECT id,name,amount,date from customers RIGHT JOIN orders on customers.Id = orders.customers_id;
注意:
1. 选择的列数必须相同;
2. 所选列的数据类型必须在相同的数据类型组中(如数字或字符);
3. 列的名称不必相同;
4. 在重复检查期间,NULL值不会被忽略;
2、UNION ALL
UNION ALL 运算符用于将两个 SELECT 语句的结果组合在一起,重复行也包含在内。 UNION ALL 运算符所遵从的规则与UNION一致。
总结: UNION和UNION ALL关键字都是将两个结果集合并为一个,也有区别。
1、重复值:UNION在进行表连接后会筛选掉重复的记录,而UNION All不会去除重复记录。
2、UNION ALL只是简单的将两个结果合并后就返回。
3、在执行效率上,UNION ALL 要比UNION快很多。因此,若可以确认合并的两个结果集中不 包含重复数据,那么就使用UNION ALL。
五、子查询
定义:一条select 查询语句的结果, 作为另一条select语句的一部分。
1、where型:
子查询的结果作为查询条件
SELECT 查询字段 FROM 表 WHERE 字段=(子查询);
代码示例:
-- 查询价格最高的商品信息 SELECT * FROM products WHERE price = (SELECT MAX(price) FROM products);
2、from型:
将子查询的结果作为一张表
SELECT 查询字段 FROM (子查询)表别名 WHERE 条件;
代码示例:
-- 查询商品中,价格大于500的商品信息,包括商品名称、商品价格、商品所属分类名称
SELECT
p.pname,
p.price,
c.cname
FROM products p
-- 子查询作为一张表使用时要起别名,才能访问表中字段
INNER JOIN (SELECT * FROM category) c ON p.category_id = c.cid
WHERE p.price > 500;3、exists型:
子查询结果是单列多行
SELECT 查询字段 FROM 表 WHERE 字段 IN (子查询);
代码示例:
--查询价格小于2000的商品,来自于哪些分类 SELECT * FROM category WHERE cid in (SELECT DISTINCT category_id FROM products WHERE price < 2000);
总结:
1. 子查询如果查出的是一个字段(单列),那就在where后面作为条件使用。 单列单行 = 单列多行 in
2. 子查询如果查询出的是多个字段(多列),就当做一张表使用(要起别名)。
六、MySQL函数
函数常用的就这些了,不用硬记,不会的百度查就行了,写着写着就记住了。
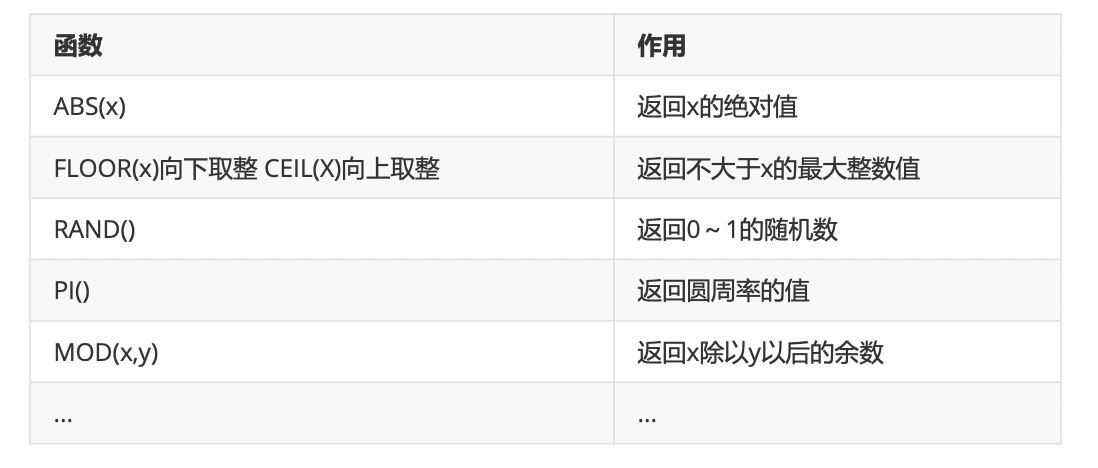
1、数学函数
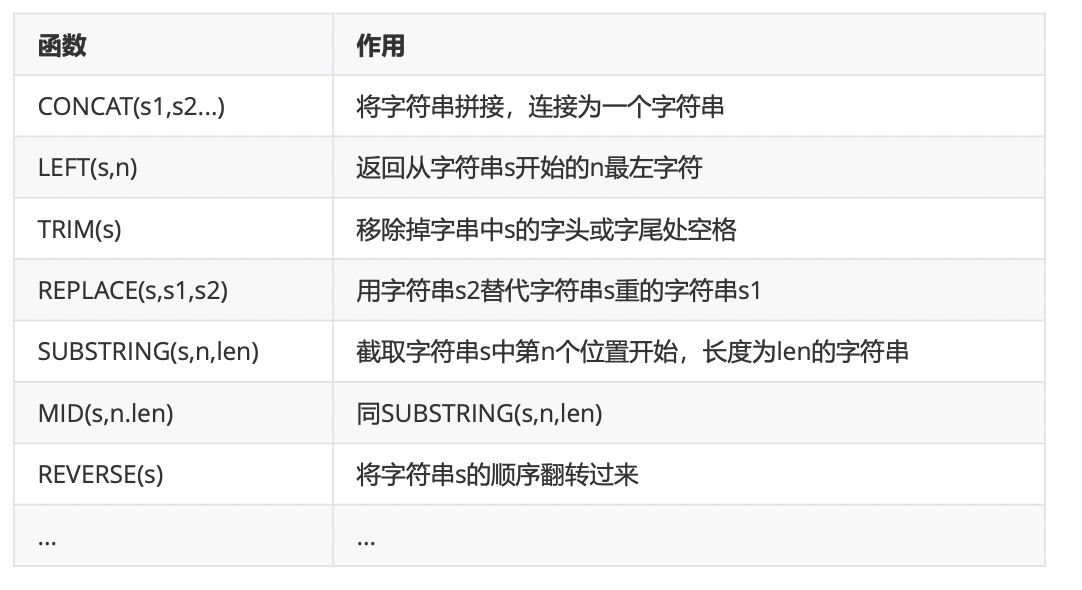
2、字符串函数
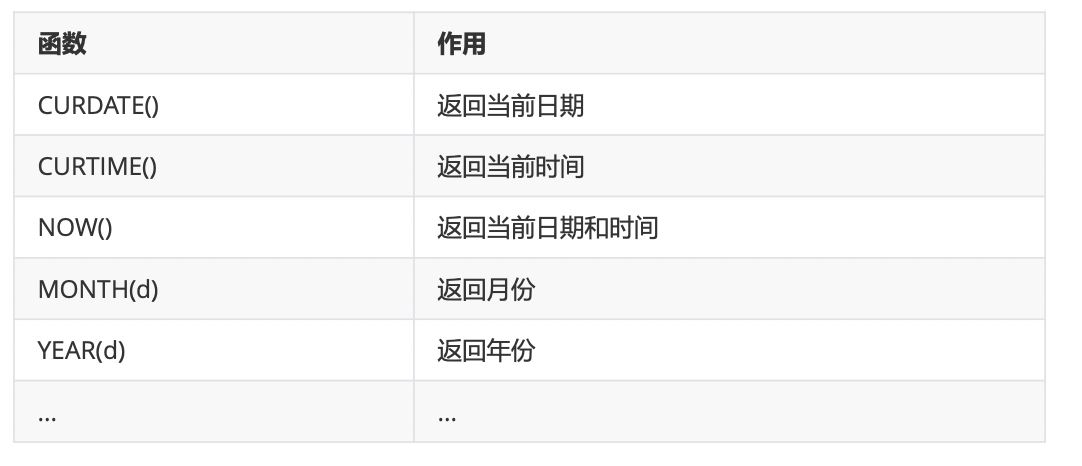
3、日期和时间函数(必学)
4、条件判断函数(这个必须掌握!!!)
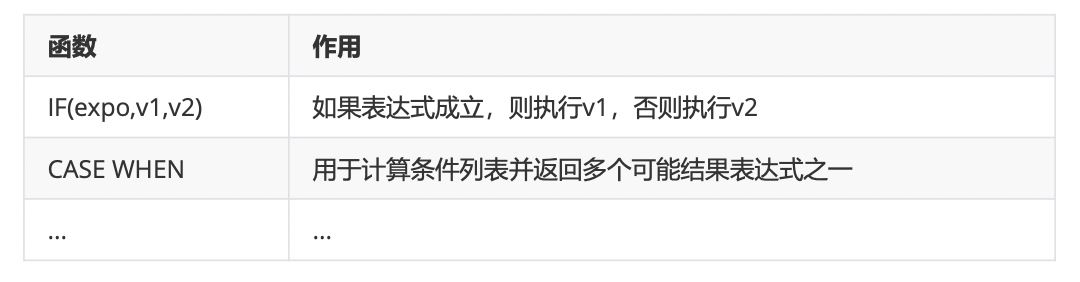
5、系统信息函数(可忽略)
到此这篇关于MySQL的核心查询语句详解的文章就介绍到这了,更多相关MySQL的核心查询内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!