08CMS v3.4 版本采集系统使用教程
脚本之家
虽然现在坛子里人气不咋滴,有不少提问贴没有解决,但是这些都会过去,G大说再进行一轮开发之后就将进入市场推广了,也就意味着官方不会再一味的闭门开发
这个所谓的 “再一轮开发”或许就是指V3.5版本吧,GBK编码版本已经发布了,再出UTF8的就应该算是完成了吧,具体还看官方的日程安排了
这个教程版的版主也当了不短的一段时间了,最郁闷的事就是老看见人在那吼:不会用啊,文档太少了……云云。汗颜哪,貌似有点占着茅坑不拉屎的嫌疑
这也不能全怪我啊,我也很想吼一句:G大你丫也太低调了点吧,让不让人活了,自己不出来也就算了,多少给个日程表,俺也好有个方向啊,盲棍探路呢,好歹给老娘指条路啊
---------------- 美丽分割线 ----------------
抱怨到这里结束吧,上正题
08CMS采集系统的使用说明
因为08CMS架构上的特殊性,目前市面上还没有完美支持的外部采集器提供(我没看到,有知道的分享下哈)
单篇采集一般的采集器都能应付,问题主要出在合辑的采集
不过即使有我也会选择系统自带的采集器,毕竟合适的才是最好的,系统自带的采集器明显是量身定做的
个人感觉,即使目前系统自带的采集器还有不少不足,但是也不是一般的采集器能替代的,契合度上的先天优势哈
下面开始介绍08CMS内置的采集系统
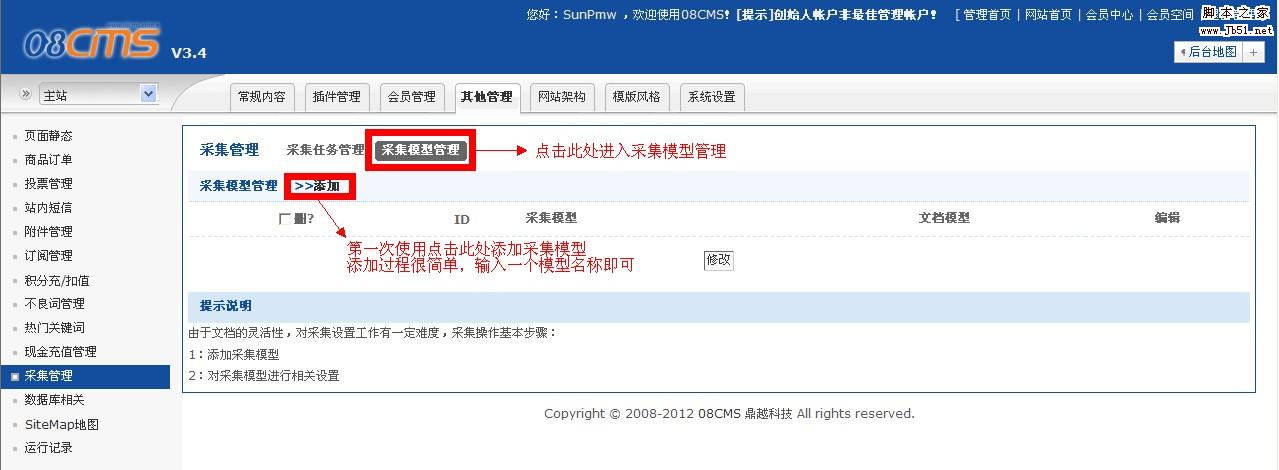
第一、登陆后台进入采集管理
[attach]1646[/attach]
那些个什么怎么登陆后台,点击先后顺序就别问我了哈
第二、第一次使用采集系统,系统会要求添加采集模型
所谓采集模型,就是搭建采集的框架,设定需要采集的字段以及采集到的内容添加至哪个文档模型
这里的设置有个让人小郁闷的地方,只要填写模型名称就可以建立模型
相关设置得在建立之后才能编辑,个人觉得在建立模型中设置采集模型相关参数比较靠谱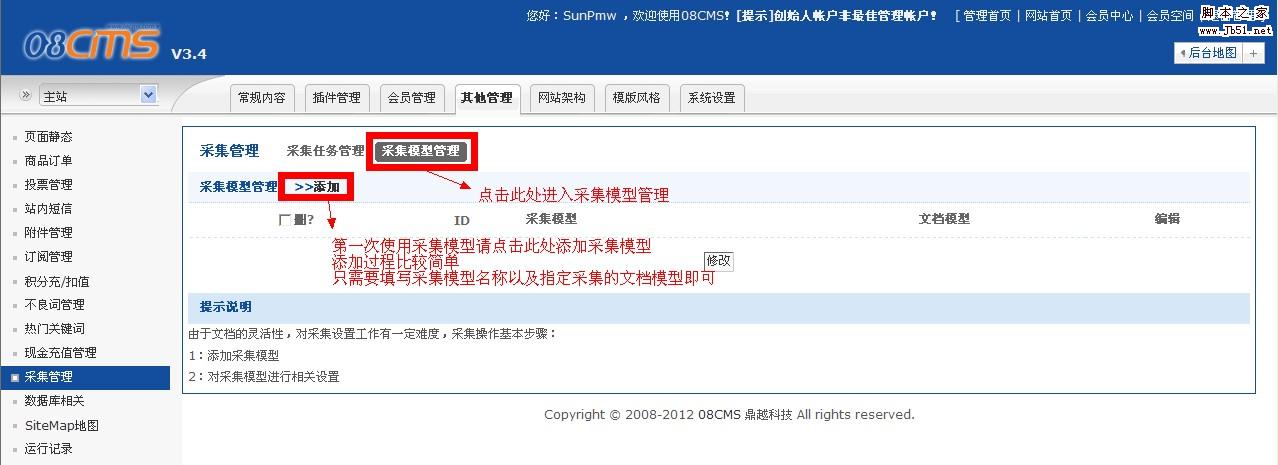
第三步、编辑采集模型
请看图解:
图一、编辑模型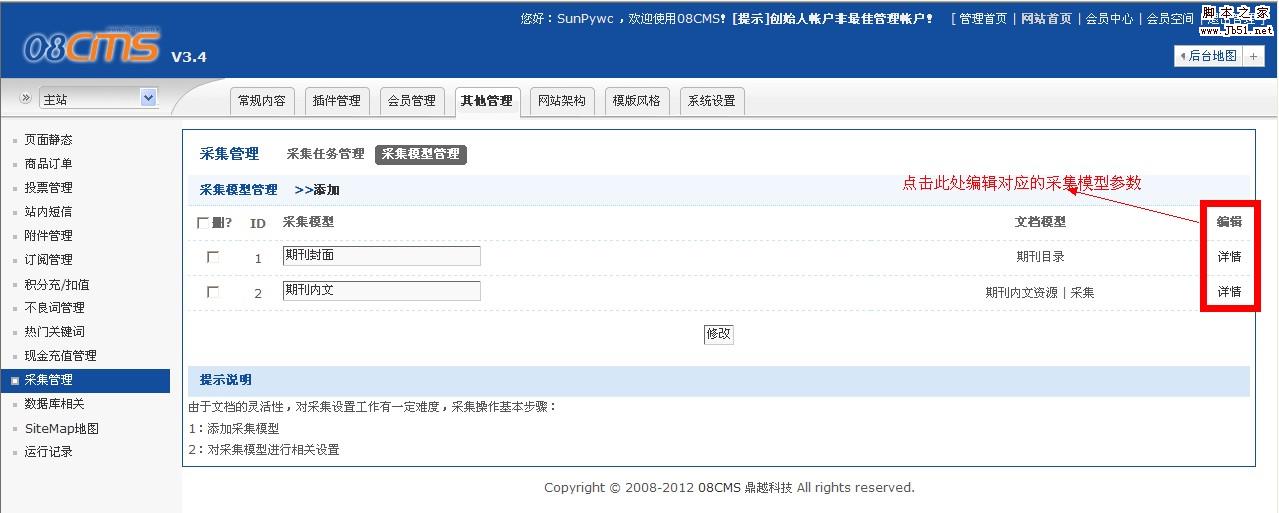
图二、
模型编辑界面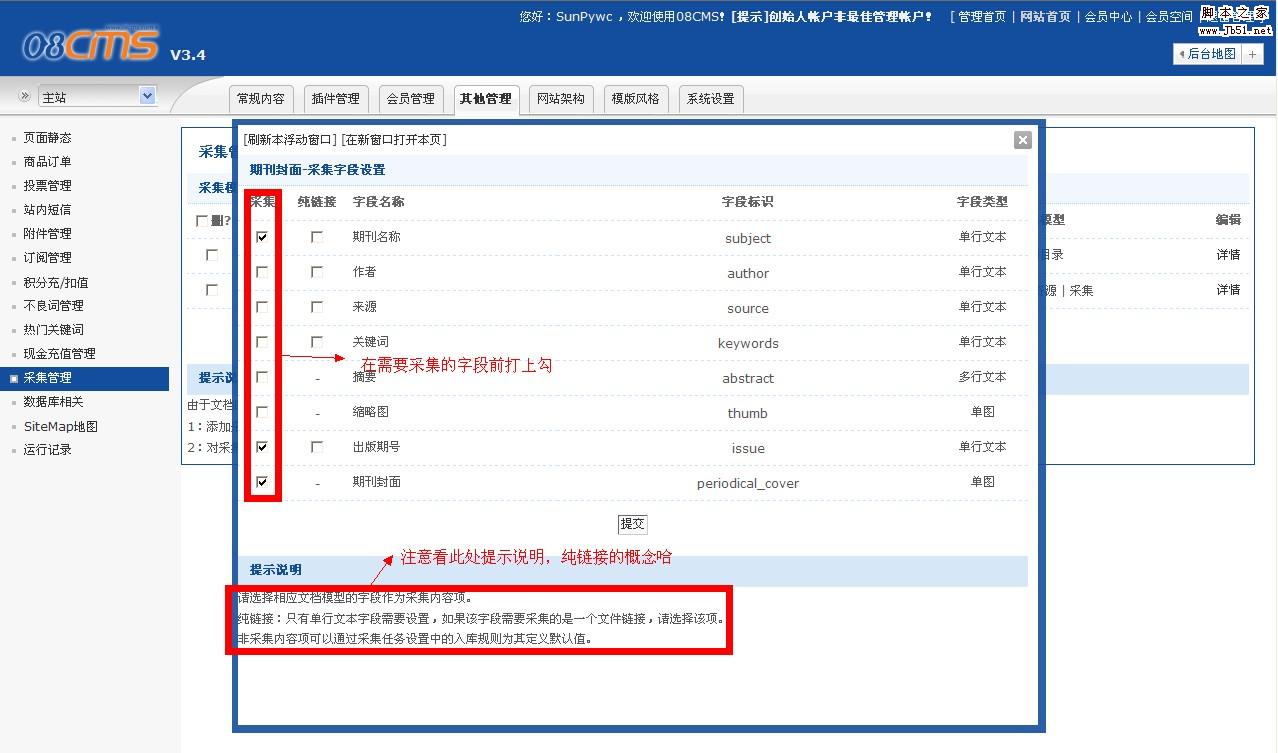
到这里,采集模型的添加完成了
下面开始添加采集任务
第四步、采集任务的添加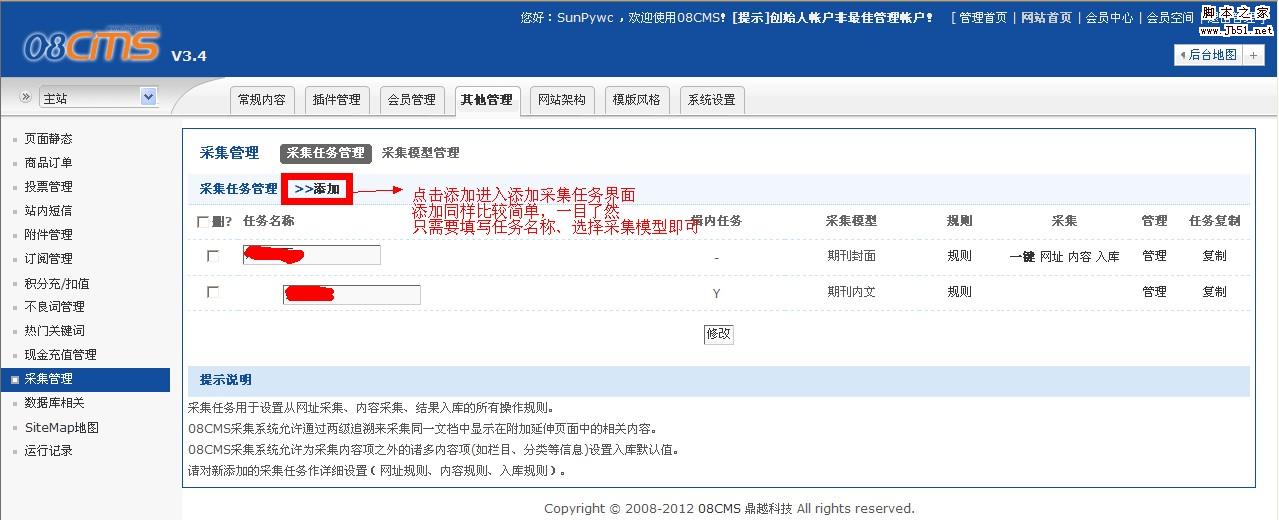
下面是采集任务界面图解,请仔细阅读图中注释
第六步、重头戏开始了,采集规则的设置
首先分析采集目标页的代码结构,这里以IE浏览器为例
查看采集目标页,点击IE的
页面 ---- 查看源文件
很简单就能看到目标页面的代码结构
采集页面的代码分析,主要是找采集目标的特征
页面太大这里不好拿上来解析,上图解释网址采集界面相关规则的设置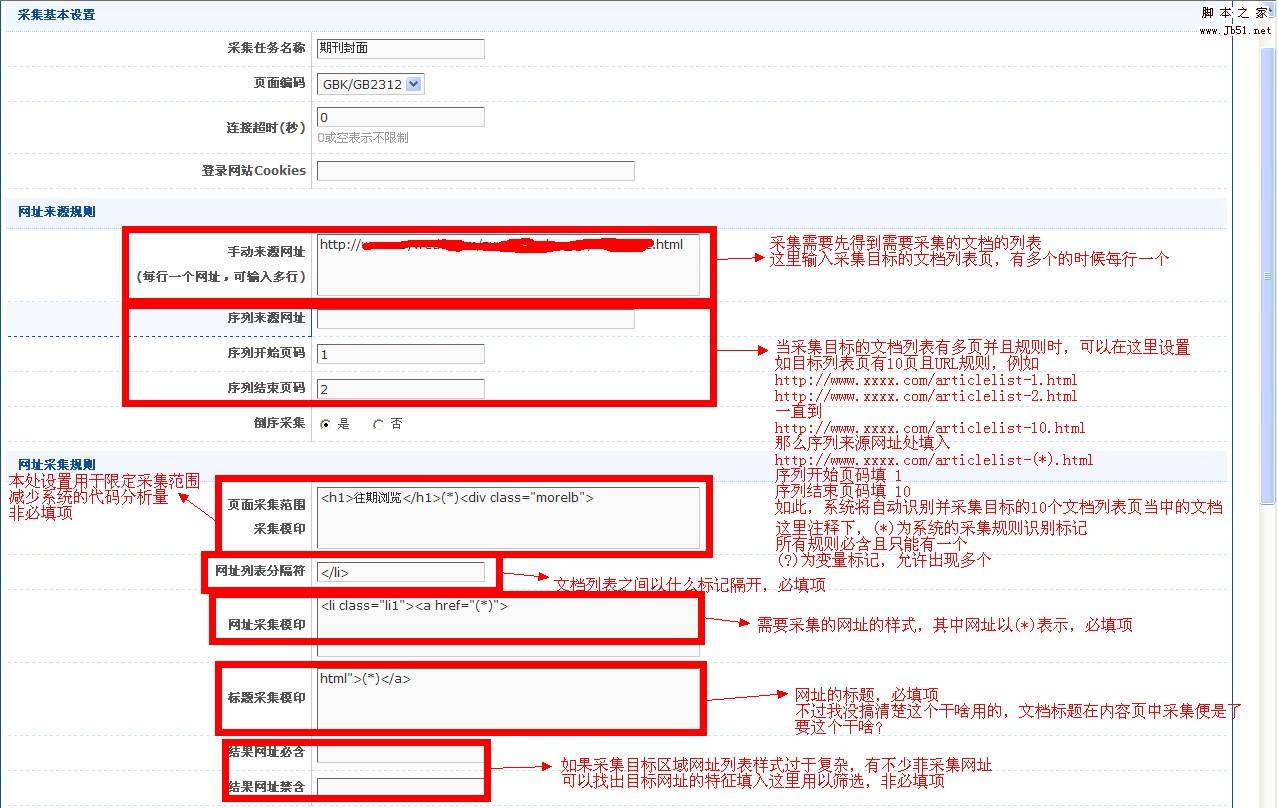
点击提交保存这里的设置
我很奇怪为什么不直接跳到下一步内容采集而是提交之后回到这个页面
在这个截图页面的下面还有一部分,称之为追溯网址规则
这个不是非必填项,一般不用
而且这个只能得到一个网址,而不是网址列表,个人感觉有点鸡肋,附上官方的解释
追溯网址:内容网址的一种延伸。有部分被采集文档,个别字段的内容不在主内容页,而是在附加页面,特别是有关附件的内容,追溯网址用于采集其附加页面网址,每个内容网址可追溯两级附加页面,追溯网址2是在追溯网址1的基础上采集的。
追溯概念举例:我们去下载站的时候,往往点进去的页面只有软件信息说明和一个或多个进入下载页面的链接
注意:这里是进入下载页面的链接,而不是下载地址。当我们要下载该软件的时候要先打开这个下载页面才能看到下载地址
这里就是一级追溯,因为我们要再点一次才能到达下载页面。这时我们的1级追溯地址就是那个进入下载页面的链接
接下来是内容页的规则
同样用图来解析,本处只选用一个字段的规则设置为例,其他字段基本类同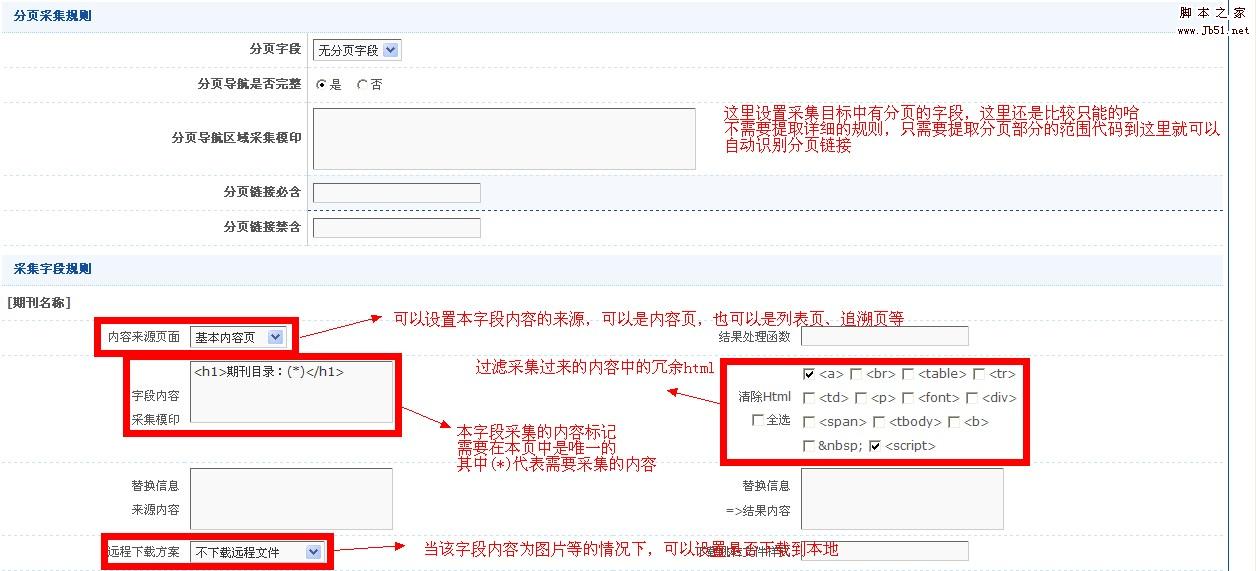
入库参数设置
如果是非合辑也就是单文档采集,那么规则到此就设置结束了
经过测试没问题即可进行采集
如果你有足够的信心,完全可以不用测试直接采集哦
如果是合辑的采集,比如小说,那么采集的设置还只进行到一半哦
合辑的采集还需要设置子任务的的规则
如图: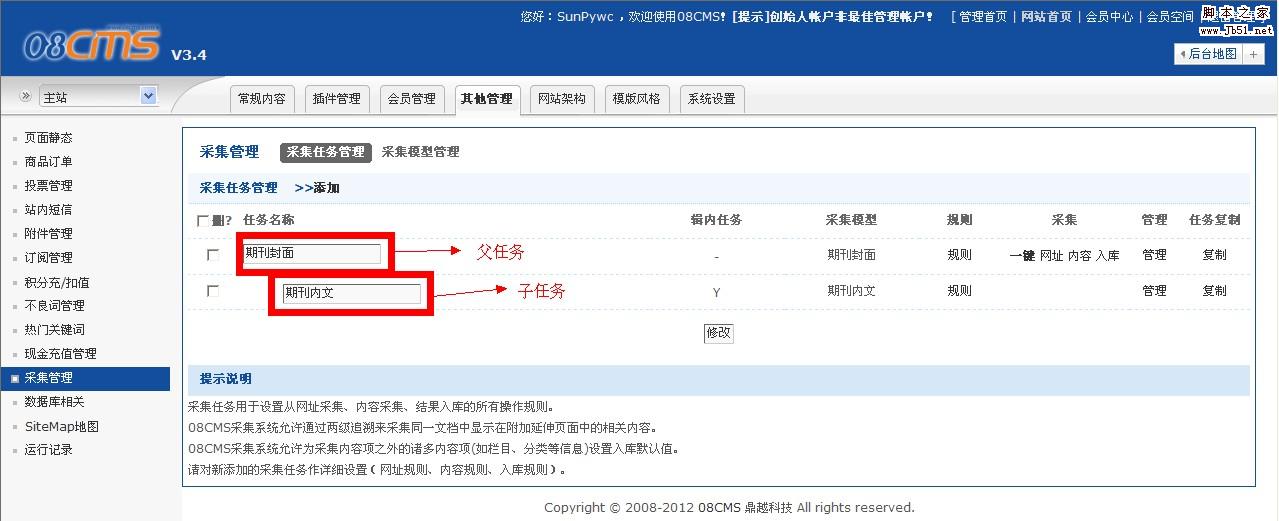
子任务在父任务下方,而且任务名称前有缩进
子任务的规则设置跟父任务的规则设置基本相同,不赘述了
理论上采集到这里就结束了,开始愉快的采集之旅吧
采集,你可以自己按照网址、内容、入库一步步来
直接 一键 采集就更干脆了
不过这里有个让人
采集任务除非是合辑采集中的父任务跟子任务
不然你就得一个个任务一键过去,不让排队。。。。
虽然有不少地方有不足,不过总体上来说采集体验还是良好的
教程就到这里结束了,有什么不明白的可以跟帖提出