
node+express制作爬虫教程
作者:xianyulaodi
最近开始重新学习node.js,之前学的都忘了。所以准备重新学一下,那么,先从一个简单的爬虫开始吧。
什么是爬虫
百度百科的解释:
爬虫即网络爬虫,是一种自动获取网页内容的程序。是搜索引擎的重要组成部分,因此搜索引擎优化很大程度上就是针对爬虫而做出的优化。
通俗一点讲:
把别人网站的信息给弄下来,弄到自己的电脑上。然后再做一些过滤,比如筛选啊,排序啊,提取图片啊,链接什么的。获取你需要的信息。
如果数据量很大,而且你的算法又比较叼,并且可以给别人检索服务的话,那么你的爬虫就是一个小百度或者小谷歌了
什么是robots协议
了解完什么是爬虫之后,我们再来了解一下爬虫的协议了,也就是哪些东西才已去爬。
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
robots.txt文件是一个文本文件,它是一个协议,而不是一个命令。它是搜索引擎中访问网站的时候要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。
当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;
如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。百度官方建议,仅当您的网站包含不希望被搜索引擎收录的内容时,才需要使用robots.txt文件。如果您希望搜索引擎收录网站上所有内容,请勿建立robots.txt文件。
如果将网站视为酒店里的一个房间,robots.txt就是主人在房间门口悬挂的“请勿打扰”或“欢迎打扫”的提示牌。这个文件告诉来访的搜索引擎哪些房间可以进入和参观,哪些房间因为存放贵重物品,或可能涉及住户及访客的隐私而不对搜索引擎开放。但robots.txt不是命令,也不是防火墙,如同守门人无法阻止窃贼等恶意闯入者。
环境搭建
需要的环境:node环境
需要安装的东西: express、require、cherrio
可以在这里找到模块的用法:https://www.npmjs.com,直接输入模块名字即可,比如:require
1、express这里就不做介绍了,中文网址在这里,可以查看:http://www.expressjs.com.cn/
2、request模块让http请求变的更加简单。最简单的一个示例:
var express = require('express');
var app = express();
app.get('/', function(req, res){
res.send('hello world');
});
app.listen(3000);
安装:npm install request
3、cherrio 是为服务器特别定制的,快速、灵活、实施的jQuery核心实现。
通过cherrio,我们就可以将抓取到的内容,像使用jquery的方式来使用了。可以点击这里查看:https://cnodejs.org/topic/5203a71844e76d216a727d2e
var cheerio = require('cheerio'),
$ = cheerio.load('<h2 class="title">Hello world</h2>');
$('h2.title').text('Hello there!');
安装:npm install cherrio
爬虫实战
假设你的电脑里已经安装好了node和express。那么我们现在开始进行我们的爬虫小程序:
1、首先随便进入一个硬盘,假如是F盘,cmd环境下执行: express mySpider
然后你发觉你的F盘上多了一个 mySpider的文件夹和一些文件,进入文件,cmd下执行 npm install
2、然后安装我们的require ==》npm installrequire --save 、再安装我们的cherrio==》npm install cherrio --save
3、安装好后,执行npm start,如果想监听窗口的变化,可以执行:supervisor start app.js,然后在浏览器输入:localhost:3000,这样我们就可以在浏览器看到express的一些欢迎语啊什么的
4、打开app.js文件,你会发觉里面有一大堆东西,因为是爬虫小程序嘛,所以都是不需要滴,删,在express的API里有这段代码,粘贴在app.js里面
app.js
var express = require('express');
var app = express();
app.get('/', function(req, res){
res.send('hello world');
});
app.listen(3000);
5、我们的require登场了。继续修改一下app.js改为:
var express = require('express');
var app = express();
var request = require('request');
app.get('/', function(req, res){
request('http://www.cnblogs.com', function (error, response, body) {
if (!error && response.statusCode == 200) {
res.send('hello world');
}
})
});
app.listen(3000);
其中request的链接就是我们要爬的网址,加入我们要爬的是博客园的网站,所以输入的是博客园的网址
6、引入cherrio,来让我们可以操做爬到的网站的内容,继续修改一下app.js
var express = require('express');
var app = express();
var request = require('request');
var cheerio = require('cheerio');
app.get('/', function(req, res){
request('http://www.cnblogs.com', function (error, response, body) {
if (!error && response.statusCode == 200) {
//返回的body为抓到的网页的html内容
var $ = cheerio.load(body); //当前的$符相当于拿到了所有的body里面的选择器
var navText=$('.post_nav_block').html(); //拿到导航栏的内容
res.send(navText);
}
})
});
app.listen(3000);
我们抓到的内容都返回到了request的body里面。cherrio可以获取所有的dom选择器。假如我们要获取导航的内容:ul的class为:post_nav_block

然后我们就可以将里面的内容显示出来了:
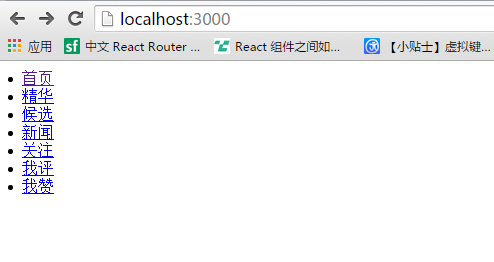
这个说明,我们的爬虫小程序就成功了。当然,这是一个简单的不能再简单的爬虫了。不过今天的文章就暂时介绍到这里,只是大概了解一下爬虫的过程而已。
接下来的第二篇文章会对这个爬虫进行升级,改版。比如异步啦,并发啦,定时去爬啦等等。
代码地址:https://github.com/xianyulaodi/mySpider