
浅析SQL Server中的执行计划缓存(下)
投稿:mrr
在上篇文章给大家介绍了SQL Server中的执行计划缓存(上),本文继续给大家介绍sqlserver执行计划缓存相关知识,小伙伴们一起学习吧。
简介
在上篇文章中我们谈到了查询优化器和执行计划缓存的关系,以及其二者之间的冲突。本篇文章中,我们会主要阐述执行计划缓存常见的问题以及一些解决办法。
将执行缓存考虑在内时的流程
上篇文章中提到了查询优化器解析语句的过程,当将计划缓存考虑在内时,首先需要查看计划缓存中是否已经有语句的缓存,如果没有,才会执行编译过程,如果存在则直接利用编译好的执行计划。因此,完整的过程如图1所示。

图1.将计划缓存考虑在内的过程
图1中我们可以看到,其中有一步需要在缓存中找到计划的过程。因此不难猜出,只要是这一类查找,一定跑不了散列(Hash)的数据结构。通过sys.dm_os_memory_cache_hash_tables这个DMV可以找到有关该Hash表的一些信息,如图2所示。这里值得注意的是,当执行计划过多导致散列后的对象在同一个Bucket过多时,则需要额外的Bucket,因此可能会导致查找计划缓存效率低下。解决办法是尽量减少在计划缓存中的计划个数,我们会在本文后面讨论到。
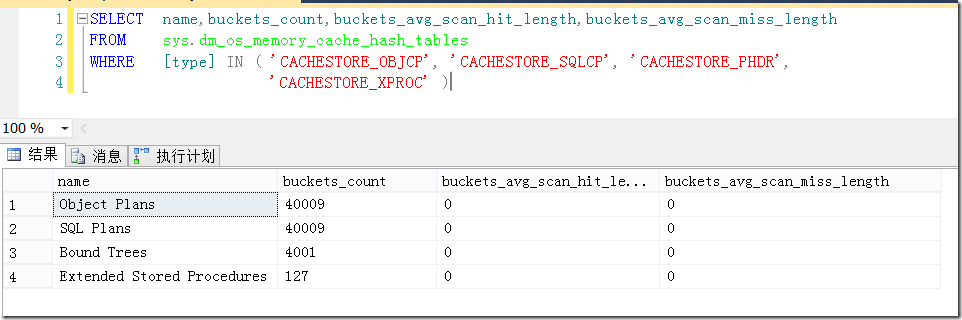
图2.有关存储计划缓存的HashTable的相关信息
当出现这类问题时,我们可以在buckets_avg_scan_miss_length列看出问题。这类情况在缓存命中率(SQL Server: Plan Cache-Cache Hit Ratio)比较高,但编译时间过长时可以作为考虑对象。
参数化和非参数化
查询计划的唯一标识是查询语句本身,但假设语句的主体一样,而仅仅是查询条件谓词不一样,那在执行计划中算1个执行计划还是两个执行计划呢?It's Depends。
假设下面两个语句,如图3所示。
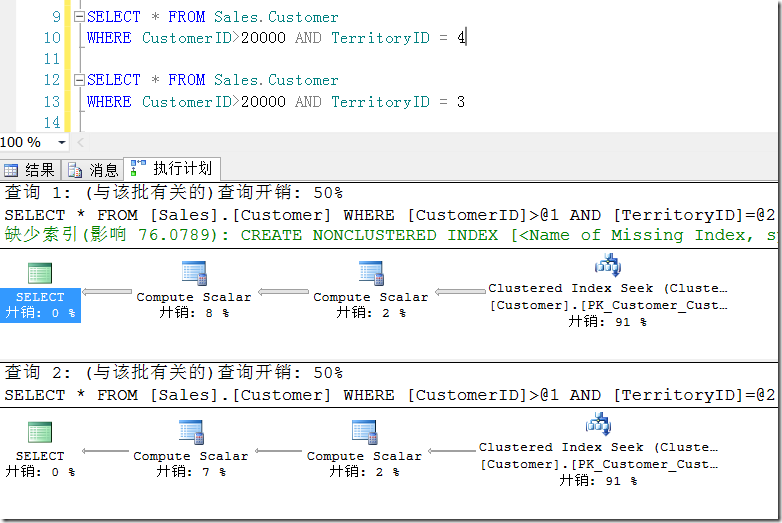
图3.仅仅谓词条件不一样的两个语句
虽然执行计划一样,但是在执行计划缓存中却会保留两份执行计划,如图4所示。

图4.同一个语句,不同条件,有两份不同的执行计划缓存
我们知道,执行计划缓存依靠查询语句本身来判别缓存,因此上面两个语句在执行计划缓存中就被视为两个不同的语句。那么解决该问题的手段就是使得执行计划缓存中的查询语句一模一样。
参数化
使得仅仅是某些参数不同,而查询本身相同的语句可以复用,就是参数化的意义所在。比如说图3中的语句,如果我们启用了数据库的强制参数化,或是使用存储过程等。SQL Server会将这些语句强制参数话,比如说我们根据图5修改了数据库层级的选项。
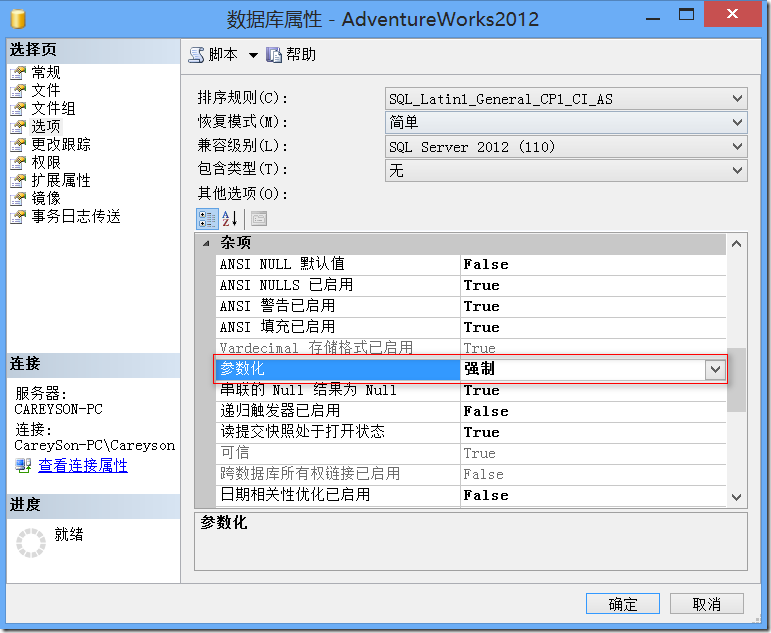
图5.数据库层级的选项
此时我们再来执行图3中的两条语句,通过查询执行计划缓存,我们发现变量部分被参数化了,从而在计划缓存中的语句变得一致,如图6所示,从而可以复用.

图6.参数话之后的查询语句
但是,强制参数会引起一些问题,查询优化器很多时候就无法根据统计信息最优化一些具体的查询,比如说不能应用一些索引或者该扫描的时候却查找。所产生的负面影响在上篇文章中已经说过,这里就不细说了。
因此对于上面的问题可以有几种解决办法。
平衡参数化和非参数化
在具体的情况下,参数化有些时候是好的,但有些时候却是性能问题的罪魁祸首,下面我们来看几种平衡这两者之间关系的手段。
使用RECOMPILE
当查询中,不准确的执行计划的成本要高于编译的成本时,在存储过程中使用RECOMPILE选项或是在即席查询中使用RECOMPILE提示使得每次查询都会重新生成执行计划,该参数会使得生成的执行计划不会被插入到执行计划缓存中。对于OLAP类查询来说,不准确的执行计划所耗费的成本往往高于编译成本太多,所以可以考虑该参数或选项,您可以如代码清单1中的查询所示这样使用Hint。
SELECT * FROM Sales.Customer WHERE CustomerID>20000 AND TerritoryID = 4 OPTION (recompile)
代码清单1.使用Recompile
除去我们可以手动提示SQL Server重编译之外,SQL Server也会在下列条件下自动重编译:
元数据变更,比如说表明称改变、删除列、变更数据类型等。
统计信息变更。
连接的SET参数变化,SET ANSI_NULLS等的值不一样,会导致缓存的执行计划不能被复用,从而重编译。这也是为什么我们看到缓存的执行计划中语句一模一样,但就是不复用,还需要相关的参数一致,这些参数可以通过sys.dm_exec_plan_attributes来查看。
使用Optimize For参数
RECOMPILE方式提供了完全不使用计划缓存的节奏。但有些时候,特性谓语的执行计划被使用的次数h更多,比如说,仅仅那些谓语条件产生大量返回结果集的参数编译,我们可以考虑Optimize For参数。比如我们来看代码清单2。
DECLARE @vari INT SET @vari=4 SELECT * FROM Sales.Customer WHERE CustomerID>20000 AND TerritoryID = @vari OPTION (OPTIMIZE FOR (@vari=4))
代码清单2.使用OPTIMIZE FOR提示
使用了该参数会使得缓存的执行计划按照OPTIMIZE FOR后面的谓语条件来生成并缓存执行计划,这也可能造成不在该参数中的查询效率低下,但是该参数是我们选择的,因此通常我们知道哪些谓语条件会被使用的多一些。
另外,自SQL Server 2008开始多了一个OPTIMIZE FOR UNKNOWN参数,这使得在优化查询的过程中探测作为谓语条件的局部参数的值,而不是根据局部变量的初始值去探测统计信息。
在存储过程中使用局部变量代替存储过程参数
在存储过程中不使用过程参数,而是使用局部变量相当于直接禁用参数嗅探。毕竟,局部变量的值只有在运行时才能知道,在执行计划被查询优化器编译时是无法知道该值的,因此强迫查询分析器使用条件列的平均值进行估计。
虽然这种方式使得参数估计变得非常不准确,但是会变得非常稳定,毕竟统计信息不会变更的过于频繁。该方式不被推荐,如果可能,尽量使用Optimizer的方式。
代码清单3展示了这种方式。
CREATE PROC TestForLocalVari @vv INT AS DECLARE @vari INT SET @vari=@vv SELECT * FROM Sales.Customer WHERE CustomerID>20000 AND TerritoryID = @vari
代码清单3.直接引用局部变量,而不是存储过程参数
强制参数化
在本篇文章的前面已经提到过了强制参数化,这里就不再提了。
使用计划指导
在某些情况下,我们的环境不允许我们直接修改SQL语句,比如所不希望破坏代码的逻辑性或是应用程序是第三方开发,因此无论是加HINT或参数都变得不现实。此时我们可以使用计划指导。
计划指导使得查询语句在由客户端应用程序扔到SQL Server的时候,SQL Server对其加上提示或选项,比如说通过代码清单4可以看到一个计划指导的例子。
EXEC sp_create_plan_guide N'MyPlanGuide1', @stmt=N'SELECT * FROM Sales.Customer WHERE CustomerID>20000 AND TerritoryID=@vari', @type=N'sql', @module_or_batch=NULL, @params=N'@vari int', @hints=N'OPTION (RECOMPILE)'
代码清单4.对我们前面的查询设置计划指导
当加入了计划指导后,当批处理到达SQL Server时,在查找匹配的计划缓存时也会去找是否有计划指导和其相匹配。如果匹配,则应用计划指导中的提示或选项。这里要注意的是,这里@stmt参数必须和查询语句中的一句一模一样,差一个空格都会被认为不匹配。
PARAMETERIZATION SIMPLE
当我们在数据库层级启用了强制参数化时,对于特定语句,我们却不想启用强制参数化,我们可以使用PARAMETERIZATION SIMPLE选项,如代码清单5所示。
DECLARE @stmt NVARCHAR(MAX) DECLARE @params NVARCHAR(MAX) EXEC sp_get_query_template N'SELECT * FROM Sales.Customer WHERE CustomerID>20000 AND TerritoryID=2', @stmt OUTPUT, @params OUTPUT PRINT @stmt PRINT @params EXEC sp_create_plan_guide N'MyTemplatePlanGuide', @stmt, N'TEMPLATE', NULL, @params, N'OPTION(PARAMETERIZATION SIMPLE)'
代码清单5.通过计划指南对单条语句应用简单参数化
小结
执行计划缓存希望尽量重用执行计划,这会减少编译所消耗的CPU和执行缓存所消耗的内存。而查询优化器希望尽量生成更精准的执行计划,这势必会造成大量的执行计划,这不仅仅可能引起重编译大量消耗CPU,还会造成内存压力,甚至当执行计划缓存过多超过BUCKET的限制时,在缓存中匹配执行计划的步骤也会消耗更多的时间。
因此利用本篇文章中所述的方法基于实际的情况平衡两者之间的关系,就变得非常重要。