
SqlServer应用之sys.dm_os_waiting_tasks 引发的疑问(中)
作者:aiyouheiya
通过上篇文章给大家介绍了SqlServer应用之sys.dm_os_waiting_tasks 引发的疑问(上) ,说了一下sys.dm_exec_requests 和 sys.dm_os_waiting_tasks 在获取并行等待的时候得不同结果,这一篇我们谈论下我的第二个疑问:为什么一个并行计划(4线程)却一下出现了那么多等待,SQL的并行到底是怎么执行的!!!!
先贴以下上篇sys.dm_os_waiting_tasks 的结果图:

我们分析一下这个结果的task_address 可以看出去掉重复其实只有9个,也就是说一个并行(4线程,配置不同,情况也不同)会有9个task。 又是线程,又是task ,还有worker,schedulers 这些都是什么? 这个有必要先说一下,因为这篇博客前我也是乱乱的。
scheduler
对于每个逻辑CPU,SQLSERVER会有一个scheduler与之对应,在SQL层面上代表CPU对象,只有拿到scheduler所有权的任务worker才能在这个逻辑CPU上运行
所谓逻辑CPU,就是SQLSERVER从Windows层面上看到的CPU数目,如果是一个双核的CPU,那么一个物理CPU在SQL看来就是两个逻辑CPU。如果系统还使用了
超线程hyper-threaded ,那对SQLSERVER来讲就是4个逻辑CPU
规则: 每个scheduler上的最大worker数目等于SQLSERVER的最大线程数除以scheduler的数目 ,在同一个时间点,只能有一个拥有scheduler的worker处于运行状态,其他worker都必须处于等待状态。这样能降低每个逻辑CPU上的处于正在运行状态的线程数目,降低context switch,提供可扩展性scheduler是SQLSERVER的一个逻辑概念,他不与物理CPU相绑定。也就是说,一个scheduler可以被Windows安排一会儿在这个CPU上,一会儿在那个CPU上。
但是,如果在sp_configure里设置了CPU affinity mask,那么scheduler就会固定在某个特定的CPU上
worker
每个worker跟一个线程(或纤程fiber)相对应,是SQLSERVER任务的执行单位。SQLSERVER不直接调度线程/纤程,而是调度worker,使得SQLSERVER能够控制
任务调度
规则: 每个worker会固定代表一个线程(或纤程),并且和一个scheduler相绑定。如果scheduler是固定在某个CPU上的(通过设置CPU affinity mask),那么worker也会固定在某个CPU上每个scheduler有worker的上限值,并且可以根据SQLSERVER工作负荷创建或释放worker,每次worker都会去运行一个完整的任务(task)。在任务做完之前不会退出,除非这个任务主动进入等待状态。
scheduler只在有新任务要运行,而当前没有空闲的worker的情况下,才会创建新的worker。
某个worker空闲超过15分钟,scheduler可能会删除这个worker,以及其对应的线程。当SQLSERVER遇到内存压力的时,也会大量删除处于空闲状态的worker,以节省multi-page的内存开销各种CPU和SQLSERVER版本组合自动配置的最大工作线程数CPU数 32位计算机 64位计算机
<=4 256 512
8 288 576
16 352 704
32 480 960
task
在worker上运行的最小任务单元。最简单的task就是一个简单batch。例如,客户发过来下面的请求:
SELECT @@SERVERNAME
GO
SELECT GETDATE()
GO
那么这两个batch就分别是两个task。SQLSERVER会先分配给第一个batch(select @@servername)一个worker,将结果返回给客户端,再分配第二个batch
(select getdate())一个worker。这两个worker可能是不同的worker,甚至在不同的scheduler上只要一个task开始运行,他就不会从这个worker上被移出。例如,如果一个select语句被其他连接阻塞住,worker就不能继续运行,只能进入等待状态。但是这个select task 不会将这个worker释放,让他做其他任务。所以结果是这个worker所对应的线程会进入等待状态
yielding
SQLOS的任务调度算法的核心,就是所有在逻辑scheduler上运行的worker都是非抢占式的 (non-preemptive)。worker始终在scheduler上运行,直到他运行结束,或者主动将scheduler让出给其他worker为止。这个“让出”scheduler的动作,我们叫yieding每个scheduler都会有一个runnable列表,所有等待CPU运行的worker都会在这个列表里排队,以先进先出的算法,等待SQL分配给他scheduler运行SQLSERVER定义了很多yieding的规则,约束一个task在scheduler运行的时间。如果task比较复杂,不能很快完成,会保证task在合适的时间点做yieding,不至于占用scheduler太多时间。
常见时间点:
1、当worker每次要去读数据页的时候,SQLSERVER会检查这个worker已经在scheduler上运行了多久,如果已经超过4ms,就做yielding
2、每做64KB的结果集排序,就会做一次yielding
3、在做语句编译compile的过程中(这个过程比较占CPU资源),经常会有yieding
4、如果客户端不能及时把结果集取走,worker就会做yieding
5、一个batch里的每一句话做完,都会做一次yieding
正常来讲,哪怕一个task要做很久,他使用的worker是会经常做yieding的,不会长时间占用CPU不放。如果在一个scheduler上同时有很多worker要运行,SQLSERVER通过worker自动yielding的方式调度并发运行。这个比Windows用上下文切换context switch更有效
另附一张手绘图

另外推荐一篇 SQL SERVER SQLOS的任务调度 微软亚太的官方博客
我们大概了解了一下SQL SERVER SQLOS的任务调度 我们回到我们的并行话题看一下这个并行执行的调度情况:

一个并行处理分配给了9个task,同时也启用了9个worker,由4个scheduler调度,每个scheduler分别由一个申请数据,另一个等待。那么申请数据的是可以理解的,等待的是干什么的呢?个人理解和当前的执行计划有关,4个线程取得数据后要做汇总的操作SQL不会等待数据获取以后再开启线程接收,而是接收线程在获取数据的时候等待。


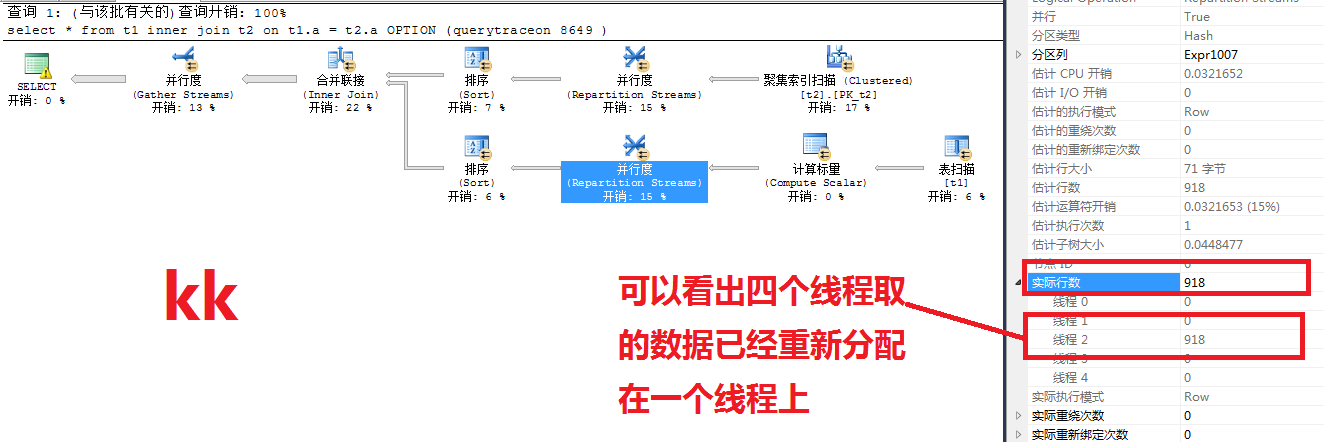
疑问得到解决了么?因为已经标记为中篇,可见还是有疑问呀!!!!我们继续下一篇吧....