
正则表达式匹配解析过程探讨分析(正则表达式匹配原理)
投稿:mdxy-dxy
已经有多篇关于正则表达式介绍的文章,随着我们越来越多使用正则表达式,想对性能做优化、减少我们正则表达式书写匹配Bug。我们不得不进一步深入了解正则表达式执行过程了。下面我们一起学习,分析下正则表达式执行过程。我们会用regexbuddy测试工具分解执行过程,具体工具使用,可以看:正则表达式性能测试工具推荐、优化工具推荐(regexbuddy推荐)。要了解正则表达式解析过程前,我们先来熟悉几个概念。
常见正则表达式引擎
引擎决定了正则表达式匹配方法及内部搜索过程,了解它至关重要的。目前主要流行引擎有:DFA,NFA两种引擎,我们比较区分下。
| 引擎 | 区别点 |
|---|---|
| DFA Deterministic finite automaton 确定型有穷自动机 |
DFA引擎它们不要求回溯(并因此它们永远不测试相同的字符两次),所以匹配速度快!DFA引擎还可以匹配最长的可能的字符串。不过DFA引擎只包含有限的状态,所以它不能匹配具有反向引用的模式,还不可以捕获子表达式。代表性有:awk,egrep,flex,lex,MySQL,Procmail |
| NFA Non-deterministic finite automaton 非确定型有穷自动机,又分为传统NFA,Posix NFA |
传统的NFA引擎运行所谓的“贪婪的”匹配回溯算法(longest-leftmost),以指定顺序测试正则表达式的所有可能的扩展并接受第一个匹配项。传统的NFA回溯可以访问完全相同的状态多次,在最坏情况下,它的执行速度可能非常慢,但它支持子匹配。代表性有:GNU Emacs,Java,ergp,less,more,.NET语言, PCRE library,Perl,PHP,Python,Ruby,sed,vi等,一般高级语言都采用该模式。 |
DFA以字符串字符,逐个在正则表达式匹配查找,而NFA以正则表达式为主,在字符串中逐一查找。尽管速度慢,但是对操作者来说更简单,因此应用更广泛!下面所有以NFA引擎举例说明,解析过程!
解析引擎眼中的字符串组成
对于字符串“DEF”而言,包括D、E、F三个字符和 0、1、2、3 四个数字位置:0D1E2F3,对于正则表达式而言所有源字符串,都有字符和位置。正则表达式会从0号位置,逐个去匹配的。
占有字符和零宽度
正则表达式匹配过程中,如果子表达式匹配到的是字符内容,而非位置,并被保存到最终的匹配结果中,那么就认为这个子表达式是占有字符的;如果子表达式匹配的仅仅是位置,或者匹配的内容并不保存到最终的匹配结果中,那么就认为这个子表达式是零宽度的。占有字符是互斥的,零宽度是非互斥的。也就是一个字符,同一时间只能由一个子表达式匹配,而一个位置,却可以同时由多个零宽度的子表达式匹配。常见零宽字符有:^,(?=)等
正则表达式匹配过程详解实例
我们掌握了上面几个概念,我们接下来分析下几个常见的解析过程。结合使用软件regexBuddy来分析。
Demo1: 源字符DEF,对应标记是:0D1E2F3,匹配正则表达式是:/DEF/
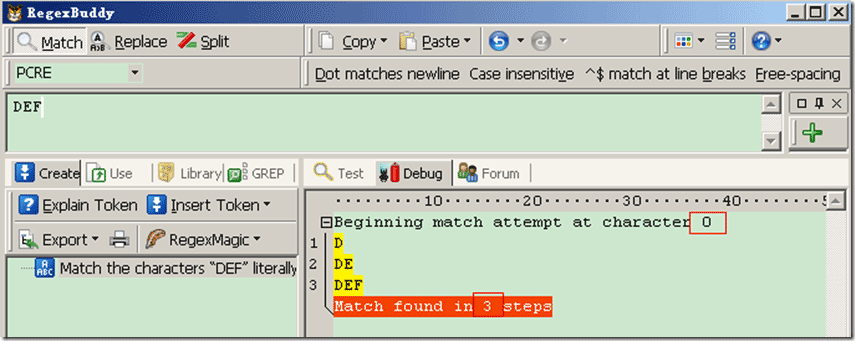
过程可以理解为:首先由正则表达式字符 /D/ 取得控制权,从位置0开始匹配,由 /D/ 来匹配“D”,匹配成功,控制权交给字符 /E/ ;由于“D”已被 /D/ 匹配,所以 /E/ 从位置1开始尝试匹配,由 /E/ 来匹配“E”,匹配成功,控制权交给 /F/ ;由 /F/ 来匹配“F”,匹配成功。
Demo2:源字符DEF,对应标记是:0D1E2F3,匹配正则表达式是:/D\w+F/
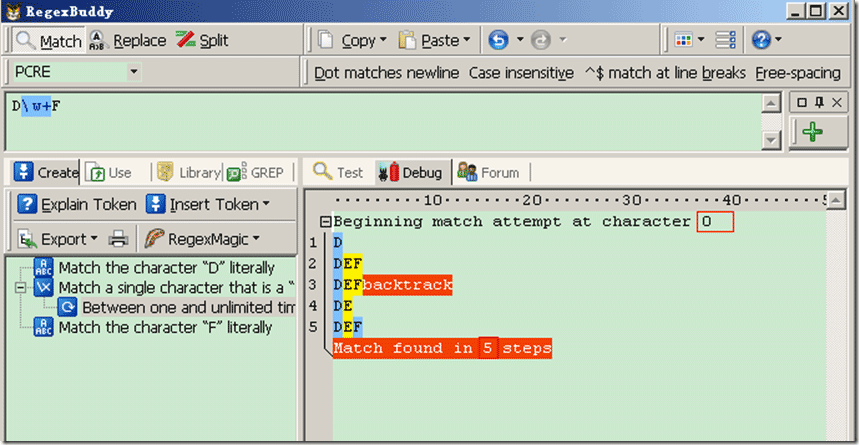
过程可以理解为:首先由正则表达式字符 /D/ 取得控制权,从位置0开始匹配,由 /D/ 来匹配“D”,匹配成功,控制权交给字符 /\w+/ ;由于“D”已被 /D/ 匹配,所以 /\w+/ 从位置1开始尝试匹配,\w+贪婪模式,会记录一个备选状态,默认会匹配最长字符,直接匹配到EF,并且匹配成功,当前位置3了。并且把控制权交给 /F/ ;由 /F/ 匹配失败,\w+匹配会回溯一位,当前位置变成2。并把控制权交个/F/,由/F/匹配字符F成功。因此\w+这里匹配E字符,匹配完成!
Demo3:源字符DEF,对应标记是:0D1E2F3,匹配正则表达式是:/^(?=D)[D-F]+$/
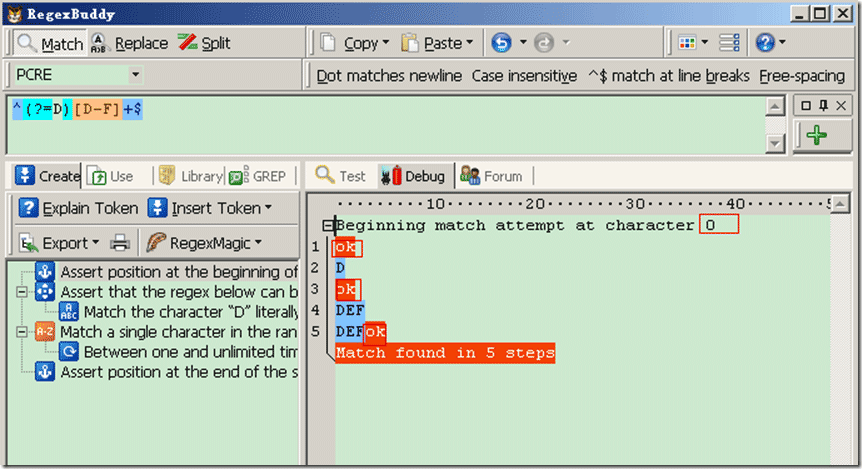
过程可以理解为:元字符 /^/ 和 /$/ 匹配的只是位置,顺序环视 /(?=D)/ (匹配当前位置,右边是否有字符“D”字符出现)只进行匹配,并不占有字符,也不将匹配的内容保存到最终的匹配结果,所以都是零宽度的。 首先由元字符 /^/ 取得控制权,从位置0开始匹配, /^/ 匹配的就是开始位置“位置0”,匹配成功,控制权交给顺序环视 /(?=D)/;/(?=D])/ 要求它所在位置右侧必须是字母”D”才能匹配成功,零宽度的子表达式之间是不互斥的,即同一个位置可以同时由多个零宽度子表达式匹配,所以它也是从位置0尝试进行匹配,位置0的右侧是字符“D”,符合要求,匹配成功,控制权交给 /[D-F]+/ ;因为 /(?=D)/ 只进行匹配,并不将匹配到的内容保存到最后结果,并且 /(?=D)/ 匹配成功的位置是位置0,所以 /[D-F]+/ 也是从位置0开始尝试匹配的, /[D-F]+/ 首先尝试匹配“D”,匹配成功,继续尝试匹配,直到匹配完”EF”,这时已经匹配到位置3,位置3的右侧已没有字符,这时会把控制权交给 /$/,元字符 /$/ 从位置3开始尝试匹配,它匹配的是结束位置,也就是“位置3”,匹配成功。此时正则表达式匹配完成,报告匹配成功。匹配结果为“DEF”,开始位置为0,结束位置为3。其中 /^/ 匹配位置0, /(?=D)/ 匹配位置0, /[D-F]+/ 匹配字符串“DEF”, /$/ 匹配位置3。
后记:上面这几个例子,我们分析了正则表达式普通匹配,还有回溯过程,然后零宽度字符,匹配过程。当然,给出的例子比较简单,实际过程中会遇到更长,更复杂的正则表达式。但是,思想是类似的。只要我们把我解析原理,都可以逐一分解的。好了,就到这里,欢迎交流!