
零基础写Java知乎爬虫之抓取知乎答案
投稿:hebedich
前期我们抓取标题是在该链接下:
http://www.zhihu.com/explore/recommendations
但是显然这个页面是无法获取答案的。
一个完整问题的页面应该是这样的链接:
http://www.zhihu.com/question/22355264
仔细一看,啊哈我们的封装类还需要进一步包装下,至少需要个questionDescription来存储问题描述:
import java.util.ArrayList;
public class Zhihu {
public String question;// 问题
public String questionDescription;// 问题描述
public String zhihuUrl;// 网页链接
public ArrayList<String> answers;// 存储所有回答的数组
// 构造方法初始化数据
public Zhihu() {
question = "";
questionDescription = "";
zhihuUrl = "";
answers = new ArrayList<String>();
}
@Override
public String toString() {
return "问题:" + question + "\n" + "描述:" + questionDescription + "\n"
+ "链接:" + zhihuUrl + "\n回答:" + answers + "\n";
}
}
我们给知乎的构造函数加上一个参数,用来设定url值,因为url确定了,这个问题的描述和答案也就都能抓到了。
我们将Spider的获取知乎对象的方法改一下,只获取url即可:
static ArrayList<Zhihu> GetZhihu(String content) {
// 预定义一个ArrayList来存储结果
ArrayList<Zhihu> results = new ArrayList<Zhihu>();
// 用来匹配url,也就是问题的链接
Pattern urlPattern = Pattern.compile("<h2>.+?question_link.+?href=\"(.+?)\".+?</h2>");
Matcher urlMatcher = urlPattern.matcher(content);
// 是否存在匹配成功的对象
boolean isFind = urlMatcher.find();
while (isFind) {
// 定义一个知乎对象来存储抓取到的信息
Zhihu zhihuTemp = new Zhihu(urlMatcher.group(1));
// 添加成功匹配的结果
results.add(zhihuTemp);
// 继续查找下一个匹配对象
isFind = urlMatcher.find();
}
return results;
}
接下来,就是在Zhihu的构造方法里面,通过url获取所有的详细数据。
我们先要对url进行一个处理,因为有的针对回答的,它的url是:
http://www.zhihu.com/question/22355264/answer/21102139
有的针对问题的,它的url是:
http://www.zhihu.com/question/22355264
那么我们显然需要的是第二种,所以需要用正则把第一种链接裁切成第二种,这个在Zhihu中写个函数即可。
// 处理url
boolean getRealUrl(String url) {
// 将http://www.zhihu.com/question/22355264/answer/21102139
// 转化成http://www.zhihu.com/question/22355264
// 否则不变
Pattern pattern = Pattern.compile("question/(.*?)/");
Matcher matcher = pattern.matcher(url);
if (matcher.find()) {
zhihuUrl = "http://www.zhihu.com/question/" + matcher.group(1);
} else {
return false;
}
return true;
}
接下来就是各个部分的获取工作了。
先看下标题:

正则把握住那个class即可,正则语句可以写成:zm-editable-content\">(.+?)<
运行下看看结果:

哎哟不错哦。
接下来抓取问题描述:
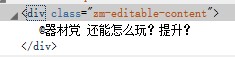
啊哈一样的原理,抓住class,因为它应该是这个的唯一标识。
验证方法:右击查看页面源代码,ctrl+F看看页面中有没有其他的这个字符串。
后来经过验证,还真出了问题:

标题和描述内容前面的class是一样的。
那只能通过修改正则的方式来重新抓取:
// 匹配标题
pattern = Pattern.compile("zh-question-title.+?<h2.+?>(.+?)</h2>");
matcher = pattern.matcher(content);
if (matcher.find()) {
question = matcher.group(1);
}
// 匹配描述
pattern = Pattern
.compile("zh-question-detail.+?<div.+?>(.*?)</div>");
matcher = pattern.matcher(content);
if (matcher.find()) {
questionDescription = matcher.group(1);
}
最后就是循环抓取答案了:
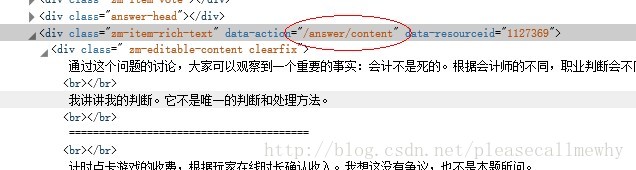
初步暂定正则语句:/answer/content.+?<div.+?>(.*?)</div>
改下代码之后我们会发现软件运行的速度明显变慢了,因为他需要访问每个网页并且把上面的内容抓下来。
比如说编辑推荐有20个问题,那么就需要访问网页20次,速度也就慢下来了。
试验一下,看上去效果不错:
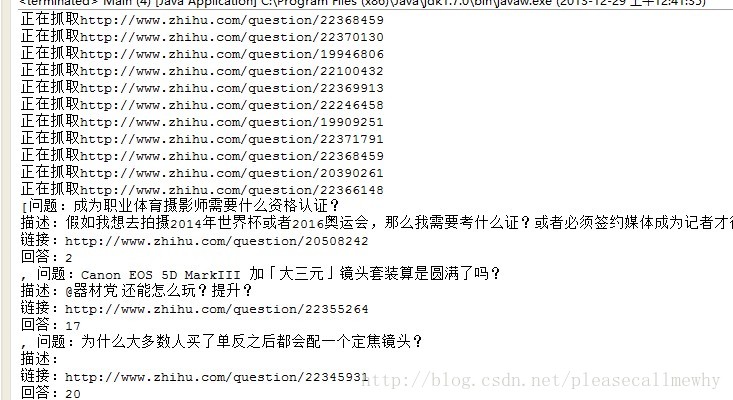
OK,那就先这样好了~下次继续进行一些细节的调整,比如多线程,IO流写入本地等等。
附项目源码:
Zhihu.java
import java.util.ArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Zhihu {
public String question;// 问题
public String questionDescription;// 问题描述
public String zhihuUrl;// 网页链接
public ArrayList<String> answers;// 存储所有回答的数组
// 构造方法初始化数据
public Zhihu(String url) {
// 初始化属性
question = "";
questionDescription = "";
zhihuUrl = "";
answers = new ArrayList<String>();
// 判断url是否合法
if (getRealUrl(url)) {
System.out.println("正在抓取" + zhihuUrl);
// 根据url获取该问答的细节
String content = Spider.SendGet(zhihuUrl);
Pattern pattern;
Matcher matcher;
// 匹配标题
pattern = Pattern.compile("zh-question-title.+?<h2.+?>(.+?)</h2>");
matcher = pattern.matcher(content);
if (matcher.find()) {
question = matcher.group(1);
}
// 匹配描述
pattern = Pattern
.compile("zh-question-detail.+?<div.+?>(.*?)</div>");
matcher = pattern.matcher(content);
if (matcher.find()) {
questionDescription = matcher.group(1);
}
// 匹配答案
pattern = Pattern.compile("/answer/content.+?<div.+?>(.*?)</div>");
matcher = pattern.matcher(content);
boolean isFind = matcher.find();
while (isFind) {
answers.add(matcher.group(1));
isFind = matcher.find();
}
}
}
// 根据自己的url抓取自己的问题和描述和答案
public boolean getAll() {
return true;
}
// 处理url
boolean getRealUrl(String url) {
// 将http://www.zhihu.com/question/22355264/answer/21102139
// 转化成http://www.zhihu.com/question/22355264
// 否则不变
Pattern pattern = Pattern.compile("question/(.*?)/");
Matcher matcher = pattern.matcher(url);
if (matcher.find()) {
zhihuUrl = "http://www.zhihu.com/question/" + matcher.group(1);
} else {
return false;
}
return true;
}
@Override
public String toString() {
return "问题:" + question + "\n" + "描述:" + questionDescription + "\n"
+ "链接:" + zhihuUrl + "\n回答:" + answers.size() + "\n";
}
}
Spider.java
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Spider {
static String SendGet(String url) {
// 定义一个字符串用来存储网页内容
String result = "";
// 定义一个缓冲字符输入流
BufferedReader in = null;
try {
// 将string转成url对象
URL realUrl = new URL(url);
// 初始化一个链接到那个url的连接
URLConnection connection = realUrl.openConnection();
// 开始实际的连接
connection.connect();
// 初始化 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream(), "UTF-8"));
// 用来临时存储抓取到的每一行的数据
String line;
while ((line = in.readLine()) != null) {
// 遍历抓取到的每一行并将其存储到result里面
result += line;
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
// 获取所有的编辑推荐的知乎内容
static ArrayList<Zhihu> GetRecommendations(String content) {
// 预定义一个ArrayList来存储结果
ArrayList<Zhihu> results = new ArrayList<Zhihu>();
// 用来匹配url,也就是问题的链接
Pattern pattern = Pattern
.compile("<h2>.+?question_link.+?href=\"(.+?)\".+?</h2>");
Matcher matcher = pattern.matcher(content);
// 是否存在匹配成功的对象
Boolean isFind = matcher.find();
while (isFind) {
// 定义一个知乎对象来存储抓取到的信息
Zhihu zhihuTemp = new Zhihu(matcher.group(1));
// 添加成功匹配的结果
results.add(zhihuTemp);
// 继续查找下一个匹配对象
isFind = matcher.find();
}
return results;
}
}
Main.java
import java.util.ArrayList;
public class Main {
public static void main(String[] args) {
// 定义即将访问的链接
String url = "http://www.zhihu.com/explore/recommendations";
// 访问链接并获取页面内容
String content = Spider.SendGet(url);
// 获取编辑推荐
ArrayList<Zhihu> myZhihu = Spider.GetRecommendations(content);
// 打印结果
System.out.println(myZhihu);
}
}
以上就是抓取知乎答案的全部记录,非常的详尽,有需要的朋友可以参考下