
C#词法分析器之转换DFA详解
作者:
在上一篇文章中,已经得到了与正则表达式等价的 NFA,本篇文章会说明如何从 NFA 转换为 DFA,以及对 DFA 和字符类进行化简。
一、DFA 的表示
DFA 的表示与 NFA 比较类似,不过要简单的多,只需要一个添加新状态的方法即可。Dfa 类的代码如下所示:
namespace Cyjb.Compiler.Lexer {
class Dfa {
// 在当前 DFA 中创建一个新状态。
DfaState NewState() {}
}
}
DFA 的状态也比较简单,必要的属性只有两个:符号索引和状态转移。
符号索引表示当前的接受状态对应的是哪个正则表达式。不过 DFA 的一个状态可能对应于 NFA 的多个状态(详见下面的子集构造法),所以 DFA 状态的符号索引是一个数组。对于普通状态,符号索引是空数组。
状态转移表示如何从当前状态转移到下一状态,由于在构造 NFA 时已经划分好了字符类,所以在 DFA 中直接使用数组记录下不同字符类对应的转移(DFA 中是不存在 ϵ 转移的,而且对每个字符类有且只有一条转移)。
在 NFA 的状态定义中,还有一个状态类型属性,但是在 DFA 状态中却没有这个属性,是因为 Trailing 类型的状态会在 DFA 匹配字符串的时候处理(会在下篇文章中说明),TrailingHead 类型的状态会在构造 DFA 的时候与 Normal 类型的状态合并(详见 2.4 节)。
下面是 DfaState 类的定义:
namespace Cyjb.Compiler.Lexer {
class DfaState {
// 获取包含当前状态的 DFA。
Dfa Dfa { get; private set; }
// 获取或设置当前状态的索引。
int Index { get; set; }
// 获取或设置当前状态的符号索引。
int[] SymbolIndex { get; set; }
// 获取或设置特定字符类转移到的状态。
DfaState this[int charClass] { get; set; }
}
}
DFA 的状态中额外定义的两个属性 Dfa 和 Index 同样是为了方便状态的使用。
二、NFA 转换为 DFA
2.1 子集构造法
将 NFA 转换为 DFA,采用的是子集构造(subset construction)算法。该算法的过程与《C# 词法分析器(三)正则表达式》的 3.1 节中提到的 NFA 匹配过程比较相似。在 NFA 的匹配过程中,使用的都是 NFA 的一个状态集合,那么子集构造法就是用 DFA 的一个状态来对应 NFA 的一个状态集合,即 DFA 读入输入字符串 a1a2⋯an 之后到达的状态,就对应于 NFA 读入同样的字符串 a1a2⋯an 之后到达的状态的集合。
子集构造算法需要用到的操作有:
| 操作 | 描述 |
| 能够从 NFA 的状态 | |
| 能够从 | |
| 能够从 |
我们需要找到的是当一个 NFA
首先,在读入第一个字符之前,
假设
据此,可以得到以下的算法(算法中的
输入:一个 NFAN
输出:与 NFA 等价的 DFAD
一开始,ϵ-closure(s0) 是D 中的唯一状态,且未被标记
while (在D 中存在未被标记的状态T ) {
为T 加上标记
foreach (每个字符类a ) {
U=ϵ-closure(move(T,a))
if (U 不在D 中) {
将U 加入D 中,且未被标记
}
T[a]=U
}
}
如果某个 NFA 是终结状态,那么所有包含它的 DFA 状态也是终结状态,而且 DFA 状态的符号索引就包含 NFA 状态对应的符号索引。一个 DFA 状态可能对应于多个 NFA 状态,所以上面定义 DfaState 时,符号索引是一个数组。
计算
输入:NFA 的状态集合 T
输出:\epsilon \text{-} closure(T)
将 T 的所有状态压入堆栈
\epsilon \text{-} closure(T) = T
while (堆栈非空) {
弹出栈顶元素 t
foreach (u : t 可以通过 \epsilon 转移到达 u) {
if (u \notin \epsilon \text{-} closure(T)) {
\epsilon \text{-} closure(T) = \epsilon \text{-} closure(T) \cup \left\{ u \right\}
将 u 压入堆栈
}
}
}
计算 move(T,a) 的算法更加简单,只有一个循环:
输入:NFA 的状态集合 T
输出:move(T,a)
move(T,a) = \emptyset
foreach (u \in T) {
if (u 存在字符类 a 上的转移,目标为 t) {
move(T,a) = move(T,a) \cup \left\{ t \right\}
}
}2.2 子集构造法的示例
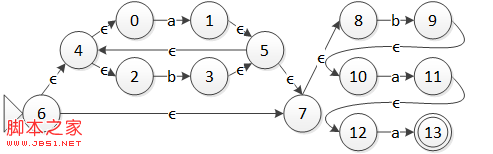
这里以上一节中从正则表达式 (a|b)*baa 构造得到的 NFA 作为示例,将它转化为 DFA。这里的输入字母表 \Sigma = \{a, b\}。
图 1 正则表达式 (a|b)*baa 的 NFA
图 2 构造 DFA 的示例
图 3 最终得到的 DFA
2.3 多个首状态的子集构造法
上一节中构造得到的 NFA 是具有多个开始状态的(为了支持上下文和行首限定符),不过对子集构造法并不会产生影响,因为子集构造法是从开始状态开始,沿着 NFA 的转移不断构造相应的 DFA 状态,只要对多个开始状态分别调用自己构造法就可以正确构造出多个 DFA,而且不必担心 DFA 之间的相互影响。为了方便起见,这多个 DFA 仍然保存在一个 DFA 中,只不过还是使用起始状态来进行区分。
2.4 DFA 状态的符号索引
一个 DFA 状态对应 NFA 的一个状态集合,那么直接将这多个 NFA 状态的符号索引全都拿来就可以了。不过前面说到, TrailingHead 类型的 NFA 状态会在构造 DFA 的时候与 Normal 类型的 NFA 状态合并,这个合并指的就是符号索引的合并。这个合并的方法也很简单,Normal 类型的状态直接将符号索引拿来,TrailingHead 类型的状态,则将 int.MaxValue - SymbolIndex 的值作为 DFA 状态的符号索引,这样两种类型的状态就可以区分出来(由于定义的符号数不会太多,所以不必担心出现重复或者负值)。
最后,再对 DFA 状态的符号索引从小到大进行排序。这样就会使 Normal 类型状态的符号索引总是排在 TrailingHead 类型状态的符号索引的前面,在后面进行词法分析时能够更容易处理,效率也会有略微的提升。
2.5 子集构造法的实现
子集构造法的 C# 实现与上面给出的伪代码基本一致,不过这里有个问题需要解决,就是如何高效的从 NFA 的状态集合得到相应的 DFA 状态。由于 NFA 状态集合是采用 HashSet<NfaState> 来保存的,所以我直接利用 Dictionary<HashSet<NfaState>, DfaState> 来解决这个问题,这里需要采用自定义的弱哈希函数,使得集合对应的哈希值只与集合中的元素相关,而与元素顺序无关。下面就是定义在 Nfa 类中的方法:
复制代码 代码如下:
View Code
/// <summary>
/// 根据当前的 NFA 构造 DFA,采用子集构造法。
/// </summary>
/// <param name="headCnt">头节点的个数。</param>
internal Dfa BuildDfa(int headCnt) {
Dfa dfa = new Dfa(charClass);
// DFA 和 NFA 的状态映射表,DFA 的一个状态对应 NFA 的一个状态集合。
Dictionary<DfaState, HashSet<NfaState>> stateMap =
new Dictionary<DfaState, HashSet<NfaState>>();
// 由 NFA 状态集合到对应的 DFA 状态的映射表(与上表互逆)。
Dictionary<HashSet<NfaState>, DfaState> dfaStateMap =
new Dictionary<HashSet<NfaState>, DfaState>(SetEqualityComparer<NfaState>.Default);
Stack<DfaState> stack = new Stack<DfaState>();
// 添加头节点。
for (int i = 0; i < headCnt; i++) {
DfaState head = dfa.NewState();
head.SymbolIndex = new int[0];
HashSet<NfaState> headStates = EpsilonClosure(Enumerable.Repeat(this[i], 1));
stateMap.Add(head, headStates);
dfaStateMap.Add(headStates, head);
stack.Push(head);
}
int charClassCnt = charClass.Count;
while (stack.Count > 0) {
DfaState state = stack.Pop();
HashSet<NfaState> stateSet = stateMap[state];
// 遍历字符类。
for (int i = 0; i < charClassCnt; i++) {
// 对于 NFA 中的每个转移,寻找 Move 集合。
HashSet<NfaState> set = Move(stateSet, i);
if (set.Count > 0) {
set = EpsilonClosure(set);
DfaState newState;
if (!dfaStateMap.TryGetValue(set, out newState)) {
// 添加新状态.
newState = dfa.NewState();
stateMap.Add(newState, set);
dfaStateMap.Add(set, newState);
stack.Push(newState);
// 合并符号索引。
newState.SymbolIndex = set.Where(s => s.SymbolIndex != Symbol.None)
.Select(s => {
if (s.StateType == NfaStateType.TrailingHead) {
return int.MaxValue - s.SymbolIndex;
} else {
return s.SymbolIndex;
}
}).OrderBy(idx => idx).ToArray();
}
// 添加 DFA 的转移。
state[i] = newState;
}
}
}
return dfa;
}
/// <summary>
/// 返回指定 NFA 状态集合的 ϵ 闭包。
/// </summary>
/// <param name="states">要获取 ϵ 闭包的 NFA 状态集合。</param>
/// <returns>得到的 ϵ 闭包。</returns>
private static HashSet<NfaState> EpsilonClosure(IEnumerable<NfaState> states) {
HashSet<NfaState> set = new HashSet<NfaState>();
Stack<NfaState> stack = new Stack<NfaState>(states);
while (stack.Count > 0) {
NfaState state = stack.Pop();
set.Add(state);
// 这里只需遍历 ϵ 转移。
int cnt = state.EpsilonTransitions.Count;
for (int i = 0; i < cnt; i++) {
NfaState target = state.EpsilonTransitions[i];
if (set.Add(target)) {
stack.Push(target);
}
}
}
return set;
}
/// <summary>
/// 返回指定 NFA 状态集合的字符类转移集合。
/// </summary>
/// <param name="states">要获取字符类转移集合的 NFA 状态集合。</param>
/// <param name="charClass">转移使用的字符类。</param>
/// <returns>得到的字符类转移集合。</returns>
private static HashSet<NfaState> Move(IEnumerable<NfaState> states, int charClass) {
HashSet<NfaState> set = new HashSet<NfaState>();
foreach (NfaState state in states) {
if (state.CharClassTransition != null && state.CharClassTransition.Contains(charClass)) {
set.Add(state.CharClassTarget);
}
}
return set;
}在这个实现中,将 DFA 的起始状态的符号索引设为了空数组,这样会使得空字符串 $\epsilon$ 不会被匹配(其它匹配不会受到影响),即 DFA 至少会匹配一个字符。这样的做法在词法分析中是有意义的,因为词素不能是空字符串。
2.6 DFA 中的死状态严格说来,由以上的算法得到的 DFA 可能并不是一个 DFA,因为 DFA 要求每个状态在每个字符类上有且只有一个转移。而上面的算法生成的 DFA,在某些字符类上可能并没有的转移,因为在算法中,如果这个转移对应的 NFA 状态集合是空集,则无视这个转移。如果是严格的 DFA 的话,这时应该添加一个到死状态 $\emptyset$ 的转移(死状态在所有字符类上的转移都到达其自身)。
但是在词法分析中,需要知道什么时候已经不存在被这个 DFA 接受的可能性了,这样才能够知道是否已经匹配到了正确的词素。因此,在词法分析中,到达死状态的转移将被消除,如果没有找到某个输入符号上的转换,就认为这时候已经匹配到了正确的词素(最后一个终结状态对应的词素)。
三、DFA 的化简3.1 DFA 最小化
上面虽然构造出了一个可用的 DFA,但它可能并不是最优的,例如下面的两个等价的 DFA,识别的都是正则表达式 (a|b)*baa,但具有不同的状态数。
图 4 两个等价的 DFA
显然,状态数越少的 DFA,匹配时的效率越高,所以需要使用一些算法,来将 DFA 的状态数最小化,即 DFA 的化简。
化简 DFA 的思想是寻找等价状态——它们都(不)是接受状态,而且对于任意的输入,总是转移到等价的状态。找到所有等价的状态后,就可以将它们合并为一个状态,实现 DFA 状态数的最小化。
寻找等价状态一般有两种方法:分割法和合并法。
分割法是先将所有接受状态和所有非接受状态看作两个等价状态集合,然后从里面分割出不等价的状态子集,直到剩下的所有等价状态集合都不可再分。合并法是先将所有状态看作不等价的,然后从里面找到两个(或多个)等价的状态,并合并为一个状态。
两种方法都可以实现 DFA 的化简,但是合并法比较复杂,因此这里我使用分割法来对 DFA 进行化简。
DFA 最小化的算法如下:
输入:一个 DFA $D$
输出:与 $D$ 等价的最简 DFA $D'$
构造 $D$ 的初始划分 $\Pi$,初始划分包含两个组:接受状态组和非接受状态组
while (true) {
foreach (组 $G \in \Pi$) {
将 $G$ 划分为更小的组,使得两个状态 $s$ 和 $t$ 在同一组中当且仅当对于所有输入符号,$s$ 和 $t$ 的转移都到达 $\Pi$ 中的同一组
}
将新划分的组保存到 $\Pi _{new}$ 中
if ($\Pi_{new} \ne \Pi$) {
$\Pi = \Pi_{new}$
} else {
$\Pi _{final} = \Pi$
break;
}
}
在 $\Pi _{final}$ 中的每个组中都选取一个状态作为该组的代表,这些代表就构成了 $D'$ 的状态。
$D'$ 的开始状态是包含了 $D$ 的开始状态的组的代表。
$D'$ 的接受状态是包含了 $D$ 的接受状态的组的代表。
令 $s$ 是 $\Pi_{final}$ 中某个组 $G$ 中的状态(不是代表),那么将 $D'$ 中到 $s$ 的转移,都更改为到 $G$ 的代表的转移。因为接受状态和非接受状态在最开始就被划分开了,所以不会存在某个组即包含接受状态,又包含非接受状态。
在实际的实现中,需要注意的是由于一个 DFA 状态可能对应多个不同的终结符,因此在划分初始状态时,对应的终结符不同的终结状态也要被划分到不同的组中。
3.2 DFA 最小化的示例下面以图 4(a) 为例,给出 DFA 最小化的示例。
初始的划分包括两个组 \{A, B, C, D\} 和 \{E\},分别是非接受状态组和接受状态组。
第一次分割,在 \{A, B, C, D\} 组中,对于字符 a,状态 A, B, C 都转移到组内的状态,而状态 D 转移到组 \{E\} 中,所以状态 D 需要被划分出来。对于字符 b,所有状态都转移到该组内的状态,不能区分;\{E\} 组中,只含有一个状态,无需进一步划分。这一轮 \Pi _{new} = \left\{ \{A, B, C\}, \{D\}, \{E\} \right\}。
第二次分割,在 \{A, B, C\} 组中,对于字符 a,状态 A, B 都转移到组内的状态,而状态 C 转移到组 \{D\} 中,对于字符 b 则不能区分;组 \{D\} 和组 \{E\} 同样不做划分。这一轮 \Pi_{new} = \left\{\{A, B\}, \{C\}, \{D\}, \{E\} \right\}。
第三次分割,唯一可能被分割的组 \{A, B\},对于字符 a 和字符 b,都会转移到相同的组内,所以不会被分割。因此就得到 \Pi_{final} = \left\{ \{A, B\}, \{C\}, \{D\}, \{E\} \right\}。
最后,构造出最小化的 DFA,它有四个状态,对应于 \Pi_{final} 的四个分组。分别挑选 A, C, D, E 作为每个分组的代表,其中,A 是开始状态,E 是接受状态。将所有状态到 B 的转移都修改为到 A 的转移,最后得到的 DFA 转换表为:



| DFA 状态 | a 上的转移 | b 上的转移 |
| A | A | C |
| C | D | C |
| D | E | C |
| E | A | C |
最后再将状态重新排序,得到的就是如图 4(b) 所示的 DFA 了。
3.3 字符类最小化
在 DFA 最小化之后,还要将字符类也最小化,因为 DFA 的最小化过程会合并等价状态,这时可能会使得某些字符类变得等价,如图 5 所示。

图 5 等价的字符类
等价字符类的寻找比等价状态更简单些,先将化简后的 DFA 用表格的形式写出来,以图 5 中的 DFA 为例:
| DFA 状态 | a 上的转移 | b 上的转移 | c 上的转移 |
| A | B | B | \emptyset |
| B | B | B | C |
| C | \emptyset | \emptyset | \emptyset |
表格中的第一列是 DFA 的状态,后面的三列分别代表不同字符类上的转移。表格的第二行到第四行分别对应着 A、B、C 三个状态的转移。那么,如果在这个表格中某两列完全相同,那么对应的字符类就是等价的。
化简 DFA 和字符类的实现代码比较多,这里就不贴了,请参见 Dfa 类。
最后化简得到的 DFA,一般是用转移表的形式保存(即上面的表格形式),使用下面三个数组就可以完整表示出 DFA 了。
int[] CharClass;
int[,] Transitions;
int[][] SymbolIndex;
其中,CharClass 是字符类的映射表,它是长为 65536 的数组,用于将字符映射为相应的字符类;Transitions 是 DFA 的转移表,行数等于 DFA 中的状态数,列数为字符类的个数;SymbolIndex 则是每个状态对应的符号索引。
当然也可以对 DFA 的转移表和符号索引进行压缩以节约内存,不过这个留在以后再说。