
Python通过pytesseract库实现识别图片中的文字
作者:空空star
前言
大家好,我是空空star,本篇给大家分享一下通过Python的pytesseract库识别图片中的文字。
本篇所用软件相关版本:
macOS 11.6.5
Python 3.8.9
pytesseract 0.3.10
Pillow 9.4.0
一、pytesseract
1.pytesseract是什么
Pytesseract是一个Python的OCR库,它可以识别图片中的文本并将其转换成文本形式。Pytesseract基于Google的Tesseract OCR引擎,具有较高的准确性和可靠性。它可以读取多种格式的图片,包括PNG、JPEG、GIF等。Pytesseract可以应用于自然语言处理、数据挖掘、OCR识别等领域。
2.安装pytesseract
pip install pytesseract
3.查看pytesseract版本
pip show pytesseract
Name: pytesseract
Version: 0.3.10
Summary: Python-tesseract is a python wrapper for Google’s Tesseract-OCR
Home-page: https://github.com/madmaze/pytesseract
Author: Samuel Hoffstaetter
Author-email: samuel@hoffstaetter.com
License: Apache License 2.0
Requires: packaging, Pillow
Required-by:
4.安装PIL
Pillow库是Python图像处理库,pytesseract使用它来处理图像。
pip install pillow
5.查看PIL版本
pip show pillow
Name: Pillow
Version: 9.4.0
Summary: Python Imaging Library (Fork)
Home-page: https://python-pillow.org
Author: Alex Clark (PIL Fork Author)
Author-email: aclark@python-pillow.org
License: HPND
Requires:
Required-by: image, imageio, matplotlib, pytesseract, wordcloud
二、Tesseract OCR
1.Tesseract OCR是什么
Tesseract OCR是一种开源的OCR(Optical Character Recognition,光学字符识别)引擎,它能够将图像中的文本内容识别并转换为可编辑的文本格式。它最初由惠普实验室开发,现在由谷歌维护和更新。Tesseract OCR支持超过100种语言,包括中文、英文、法文、德文等。它可以在多种操作系统上运行,包括Windows、Linux、macOS等。Tesseract OCR被广泛应用于数字化文档、自动化数据输入、智能搜索等方面。
2.安装Tesseract OCR
macOS下:
brew install tesseract
3.安装 Tesseract OCR 语言包
macOS下:
brew install tesseract-lang
三、使用方法
1.引入库
import pytesseract from PIL import Image
2.打开图片文件
img = Image.open("demo.png")3.使用Tesseract进行文字识别
text = pytesseract.image_to_string(img, lang='chi_sim')
4.输出识别结果
print(text)
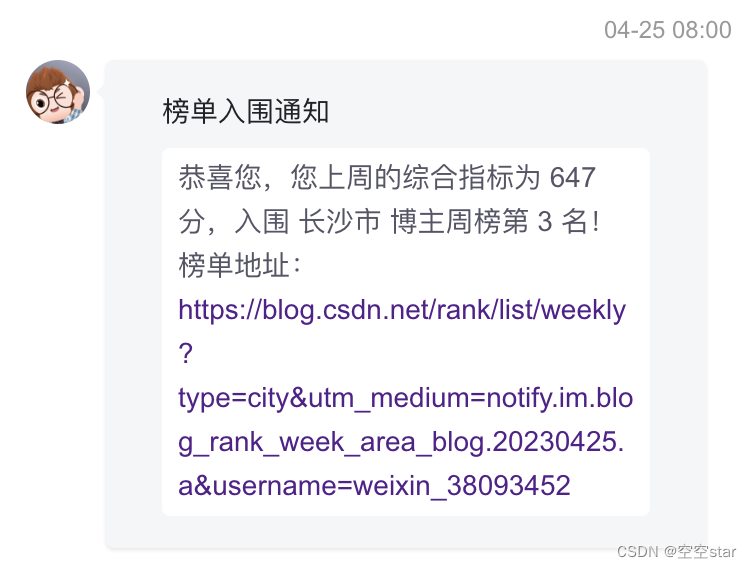
原图
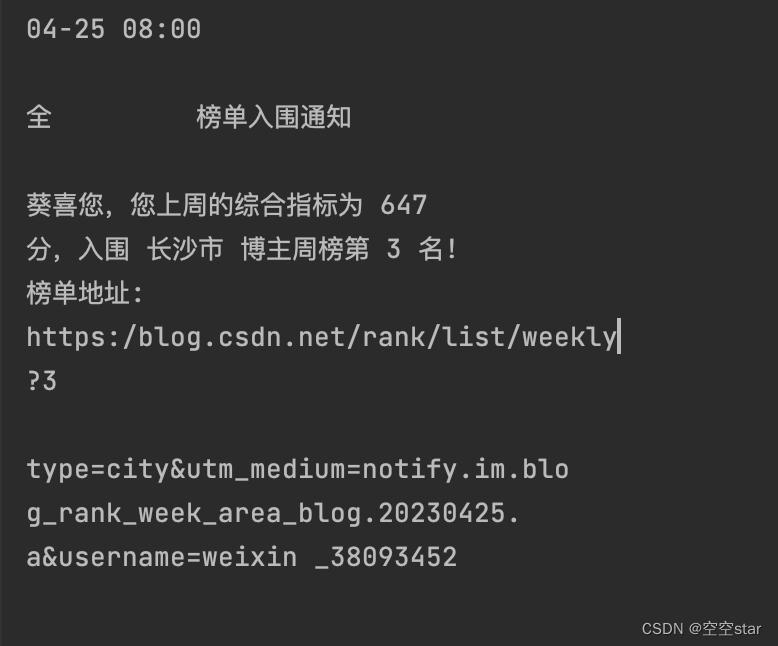
识别出的文字截图
总结
image_to_string是一个Python函数,它是由tesseract OCR引擎提供的。这个函数的作用是将一个图像中的文本转换成字符串,也就是把图像中的文字识别出来,并把它们转换成计算机可以处理的字符串格式。这个函数可以接受多种格式的图像,例如JPEG、PNG、BMP等。在使用这个函数前,需要确保已经安装了tesseract OCR引擎。
以上就是Python通过pytesseract库实现识别图片中的文字的详细内容,更多关于Python pytesseract识别图片中文字的资料请关注脚本之家其它相关文章!