
一文秒懂pandas中iloc()函数
作者:sci_more
iloc[]函数属于pandas库全称为index location,即对数据进行位置索引,从而在数据表中提取出相应的数据,本文通过实例代码介绍pandas中iloc()函数,感兴趣的朋友一起看看吧
pandas中iloc()函数
DataFrame.iloc
纯基于整数位置的索引。
import pandas as pd
mydict = [{'a': 1, 'b': 2, 'c': 3, 'd': 4},
{'a': 100, 'b': 200, 'c': 300, 'd': 400},
{'a': 1000, 'b': 2000, 'c': 3000, 'd': 4000 }]
'''mydict
[{'a': 1, 'b': 2, 'c': 3, 'd': 4},
{'a': 100, 'b': 200, 'c': 300, 'd': 400},
{'a': 1000, 'b': 2000, 'c': 3000, 'd': 4000}]'''
df = pd.DataFrame(mydict)
'''
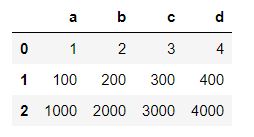
df
a b c d
0 1 2 3 4
1 100 200 300 400
2 1000 2000 3000 4000
'''
df.iloc[0]#取第0行
a 1
b 2
c 3
d 4
Name: 0, dtype: int64
df.iloc[0].shape
(4,)
type(df.iloc[0].shape)
tuple
df.iloc[[0]]
a b c d
0 1 2 3 4
type(df.iloc[[0]])
pandas.core.frame.DataFrame
df.iloc[[0,2]]#取第0、2行
a b c d
0 1 2 3 4
2 1000 2000 3000 4000
df.iloc[0:2,0:3]#取0到1行和0到2列
a b c
0 1 2 3
1 100 200 300
df.iloc[[True, False, True]]#不常用
a b c d
0 1 2 3 4
2 1000 2000 3000 4000
df.iloc[lambda x: x.index % 2 == 0]#函数生成索引列表,x即df
a b c d
0 1 2 3 4
2 1000 2000 3000 4000Pandas库中iloc[ ]函数使用详解
1 iloc[]函数作用
iloc[]函数,属于pandas库,全称为index location,即对数据进行位置索引,从而在数据表中提取出相应的数据。
2 iloc函数使用
df.iloc[a,b],其中df是DataFrame数据结构的数据(表1就是df),a是行索引(见表1),b是列索引(见表1)。
| 姓名(列索引10) | 班级(列索引1) | 分数(列索引2) | |
| 0(行索引0) | 小明 | 302 | 87 |
| 1(行索引1) | 小王 | 303 | 95 |
| 2(行索引2) | 小方 | 303 | 100 |
1.iloc[a,b]:取行索引为a列索引为b的数据。
import pandas
df = pandas.read_csv('a.csv')
print(df.iloc[1,2])
#Out:952.iloc[a:b,c]:取行索引从a到b-1,列索引为c的数据。注意:在iloc中a:b是左到右不到的,即lioc[1:3,:]是从行索引从1到2,所有列索引的数据。
import pandas
df = pandas.read_csv('a.csv')
print(df.iloc[0:2,2]) #数据结构是Series
print(df.iloc[0:2,2].values) #数据结构是ndarray
#Out1:0 87
# 1 95
# Name: 分数, dtype: int64
#Out2:[87 95]iloc[].values,用values属性取值,返回ndarray,但是单个数值无法用values函数读取。
3.iloc[a:b,c:d]:取行索引从a到b-1,列索引从c到d-1的数据。
import pandas
df = pandas.read_csv('a.csv')
print(df.iloc[0:2,0:2])
print(df.iloc[0:2,0:2].values)
#Out1: 姓名 班级
# 0 小明 302
# 1 小王 303
#Out2:[['小明' 302]
# ['小王' 303]]4.iloc[a]:取取行索引为a,所有列索引的数据。
import pandas
df = pandas.read_csv('a.csv')
print(df.iloc[2])
print(df.iloc[2].values)
#Out1:姓名 小方
# 班级 303
# 分数 100
# Name: 2, dtype: object
#Out2:['小方' 303 100]补充:pandas的iloc函数
pandas的iloc函数:
iloc 是 Pandas 中用于基于整数位置进行索引和切片的方法。它允许你通过整数位置来访问 DataFrame 中的特定行和列。
语法格式如下:
DataFrame.iloc[row_indexer, column_indexer]
row_indexer: 行的整数位置或切片。column_indexer: 列的整数位置或切片。
下面是一些使用 iloc 的示例:
import pandas as pd
# 创建一个示例 DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [25, 30, 35, 40],
'City': ['New York', 'San Francisco', 'Los Angeles', 'Chicago']}
df = pd.DataFrame(data)
# 使用 iloc 获取特定行和列的数据
# 获取第二行(索引为1)的所有列数据
row_1 = df.iloc[1, :]
# 获取第一列(索引为0)的所有行数据
column_0 = df.iloc[:, 0]
# 获取第二行到第四行(索引为1到3)的第一列和第二列的数据
subset = df.iloc[1:4, 0:2]
print("Row 1:")
print(row_1)
print("\nColumn 0:")
print(column_0)
print("\nSubset:")
print(subset)在这个例子中,iloc 被用于获取指定的行和列。要注意,iloc 使用的是整数位置,而不是标签。索引从0开始。这使得 iloc 适用于对 DataFrame 进行基于位置的切片和索引。
Row 1:
Name Bob
Age 30
City San Francisco
Name: 1, dtype: object
Column 0:
0 Alice
1 Bob
2 Charlie
3 David
Name: Name, dtype: object
Subset:
Name Age
1 Bob 30
2 Charlie 35
3 David 40到此这篇关于Pandas库中iloc[ ]函数使用详解的文章就介绍到这了,更多相关Pandas iloc[ ]函数内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:
- Python Pandas数据分析之iloc和loc的用法详解
- 详谈Pandas中iloc和loc以及ix的区别
- 聊聊Python pandas 中loc函数的使用,及跟iloc的区别说明
- python选取特定列 pandas iloc,loc,icol的使用详解(列切片及行切片)
- 利用Pandas读取某列某行数据之loc和iloc用法总结
- Pandas中的loc与iloc区别与用法小结
- 对pandas中iloc,loc取数据差别及按条件取值的方法详解
- Python Pandas中loc和iloc函数的基本用法示例
- python中pandas库的iloc函数用法解析
- Pandas索引器 loc 和 iloc 比较及代码示例