
MySQL数据同步Elasticsearch的4种方案
作者:Java_LingFeng
今天给大家介绍一个电商中常见的场景 —— MySQL 数据同步 Elasticsearch。
商品检索
大家应该都在各种电商网站检索过商品,检索商品一般都是通过什么实现呢?搜索引擎Elasticsearch。
那么问题来了,商品上架,数据一般写入到MySQL的数据库中,那么用于检索的数据又是怎么同步到Elasticsearch的呢?
MySQL同步ES
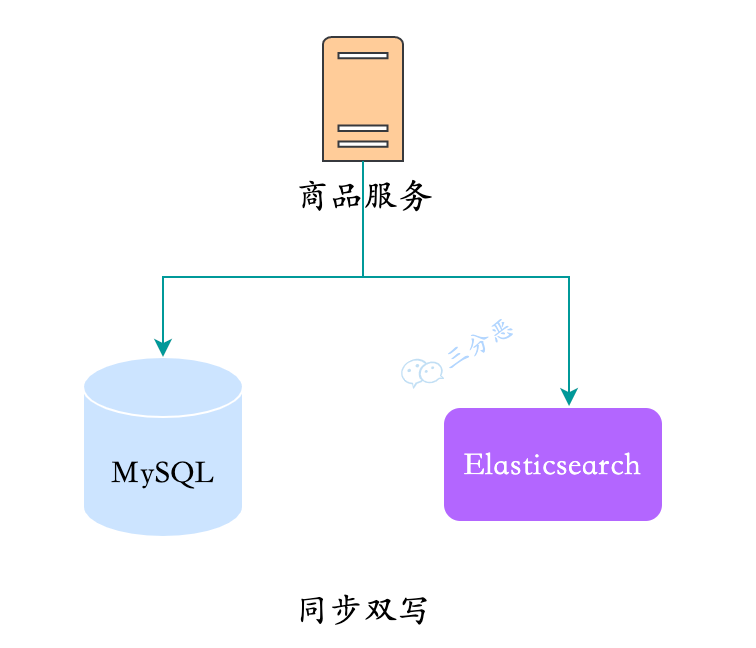
1.同步双写
这是能想到的最直接的方式,在写入MySQL,直接也同步往ES里写一份数据。
同步双写
对于这种方式:
优点:实现简单
缺点:
- 业务耦合,商品的管理中耦合大量数据同步代码
- 影响性能,写入两个存储,响应时间变长
- 不便扩展:搜索可能有一些个性化需求,需要对数据进行聚合,这种方式不便实现
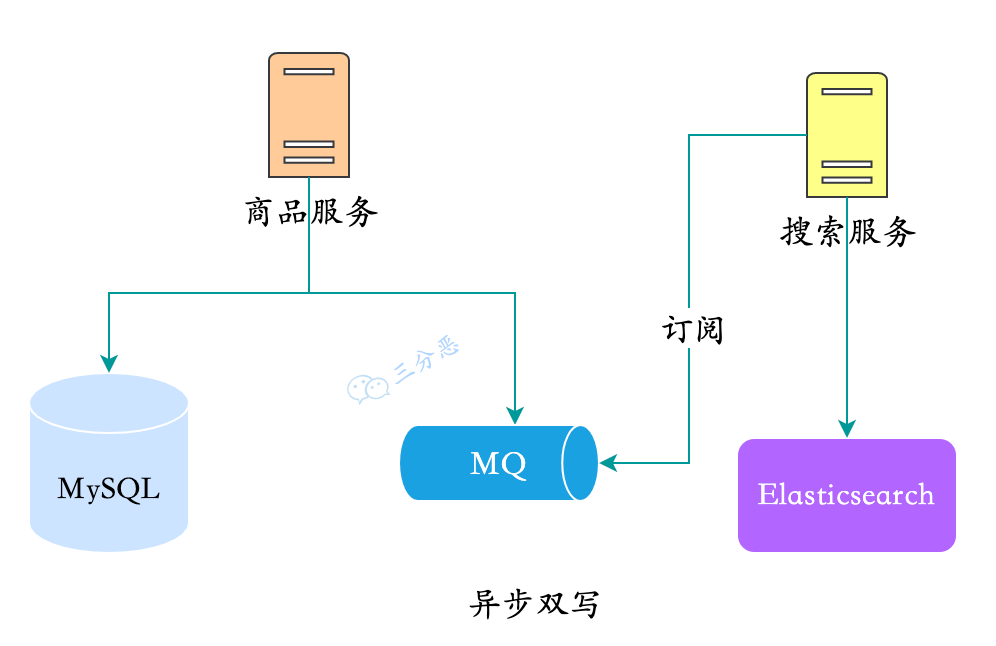
2.异步双写
我们也很容易想到异步双写的办法,上架商品的时候,先把商品数据丢进MQ,为了解耦合,我们一般会拆分一个搜索服务,由搜索服务去订阅商品变动的消息,来完成同步。
异步双写
前面说的,一些数据需要聚合处理成类似宽表的结构怎么办呢?例如商品库的商品品类、spu、sku表是分开的,但是查询是跨维度的,在ES里再聚合一次效率就低一些,最好就是把商品的数据给聚合起来,在ES里以类似大宽表的形式存储,这样一来查询效率就高一些。
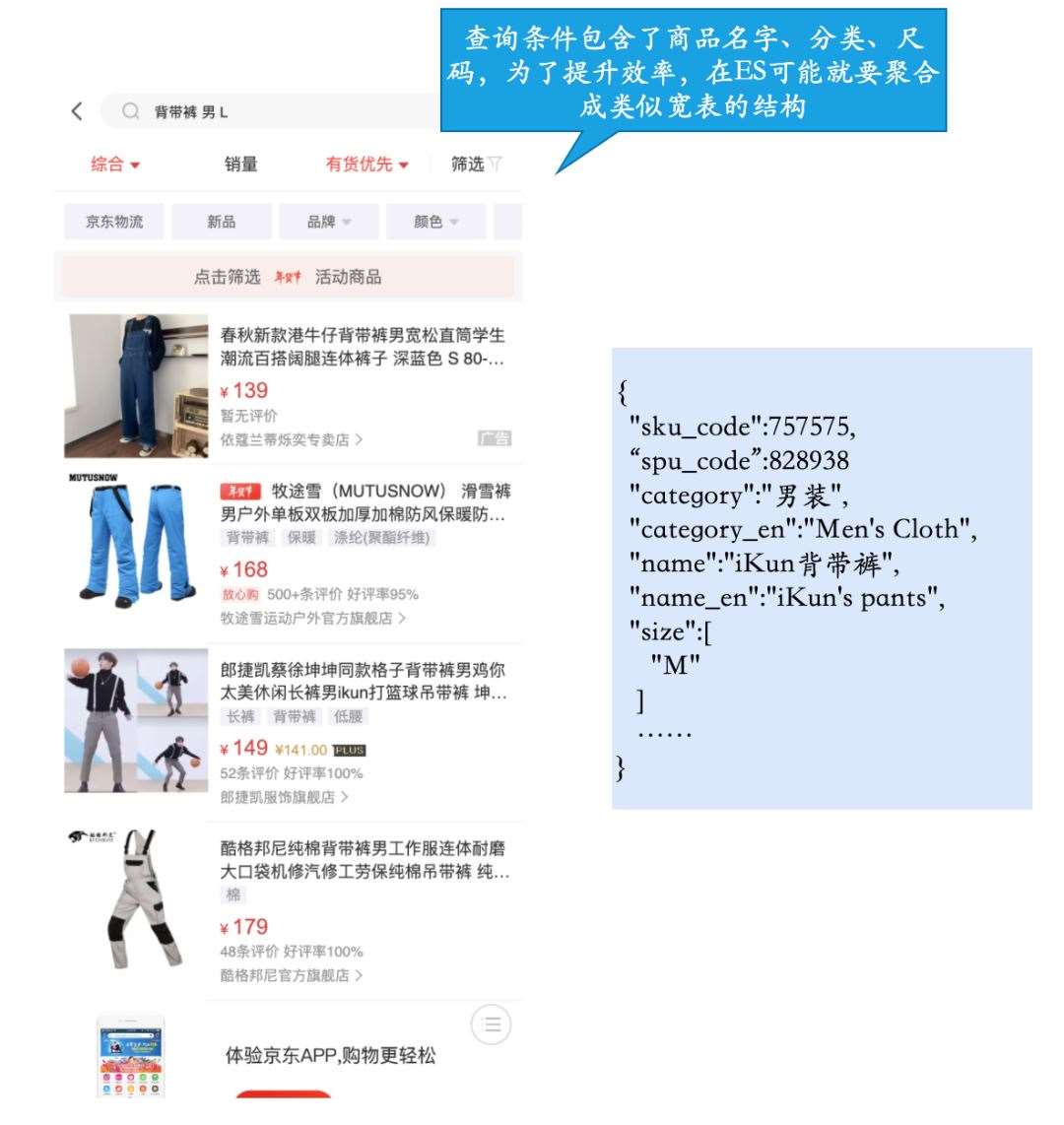
多维度多条件查询
这种其实没什么好办法,基本上还是得搜索服务直接查库,或者远程调用,再查询一遍商品的数据库,就是所谓的回查。

回查完成聚合
这种方式:
优点:
- 解耦合,商品服务无需关注数据同步
- 实时性较好,使用MQ,正常情况下,同步完成在秒级
缺点:
- 引入了新的组件和服务,增加了复杂度
3.定时任务
假如我们要快速搞搞,数据量有没那么大,怎么办呢?定时任务也可以。

定时任务
定时任务,最麻烦的一点是频率不好选,频率高的话,会非自然地形成业务的波峰,导致存储的CPU、内存占用波峰式上升,频率低的话实时性比较差,而且也有波峰的情况。
这种方式:
优点:实现比较简单
缺点:
- 实时性难以保证
- 对存储压力较大
4.数据订阅
还有一种方式,就是最时兴的数据订阅。
MySQL通过binlog订阅实现主从同步,各路数据订阅框架比如canal就依据这个原理,将client组件伪装成从库,来实现数据订阅。
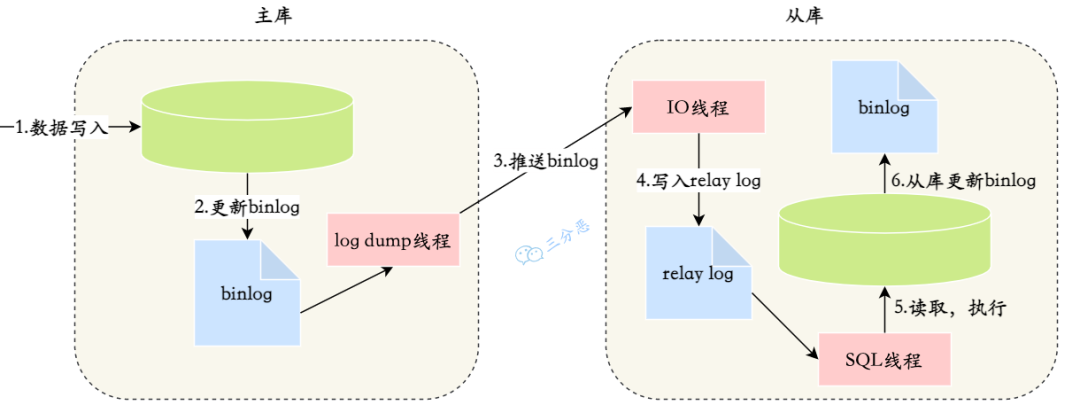
MySQL主从同步
我们以应用最广泛的canal为例,canal通过canal-adapter,支持多种适配器,其中就有ES适配器,通过一些配置,启动之后,就可以直接把MySQL数据同步到ES,这个过程是零代码的。

canal同步数据
但是,和老板了解过,使用canal看起来很美好,帮我们把同步的事情都干了,但其实,还是要写代码。为什么呢?
前面提到的多张表数据聚合,canal的支持没那么好,所以还是得回查。这时候用canal-adapter就不合适了,需要自己实现canal-client,监听和聚合数据,写入ES:
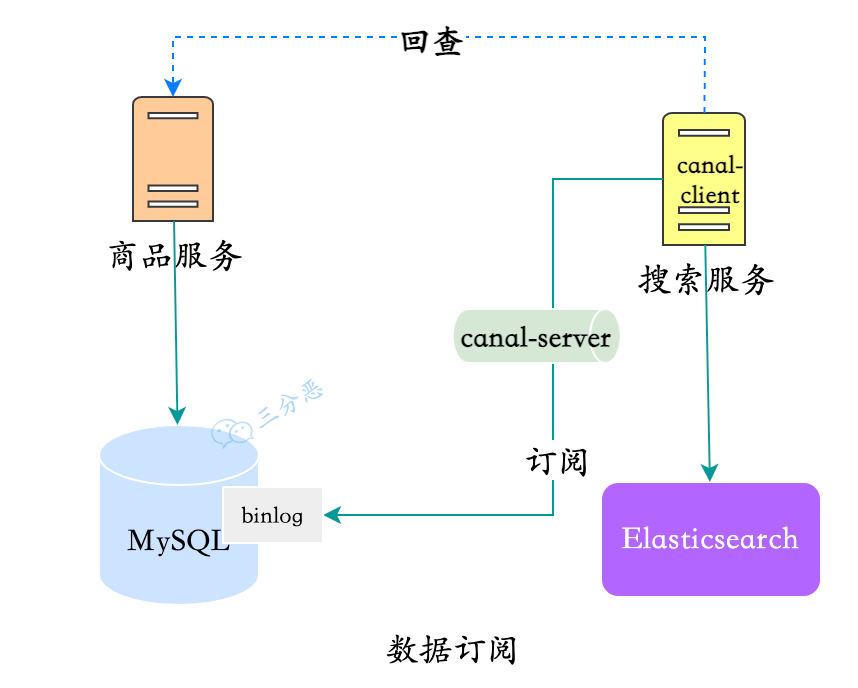
数据订阅+回查
这种看起来和异步双写比较像,但是第一降低了商品服务的耦合,第二数据的实时性更好。
所以使用数据订阅:
优点:
- 业务入侵较少
- 实时性较好
至于数据订阅框架的选型,主流的大体上是这些:
| Cancal | Maxwell | Python-Mysql-Rplication | |
|---|---|---|---|
| 开源方 | 阿里巴巴 | Zendesk | 社区 |
| 开发语言 | Java | Java | Python |
| 活跃度 | 活跃 | 活跃 | 活跃 |
| 高可用 | 支持 | 支持 | 不支持 |
| 客户端 | Java/Go/PHP/Python/Rust | 无 | Python |
| 消息落地 | Kafka/RocketMQ 等 | Kafka/RabbitNQ/Redis 等 | 自定义 |
| 消息格式 | 自定义 | JSON | 自定义 |
| 文档详略 | 详细 | 详细 | 详细 |
| Boostrap | 不支持 | 支持 | 不支持 |
除了MySQL同步ES,MySQL同步到其它的数据存储,例如HBase,其实大体上都是类似的几种方法。
到此这篇关于MySQL数据同步Elasticsearch的4种方案的文章就介绍到这了,更多相关MySQL数据同步Elasticsearch内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!