
Dubbo 系列JDK SPI 原理解析
作者:噗噗C
正文
上一篇文章讲到了如何去找到 Dubbo 源码的调试入口,如果你跟随文章思路,那你将要阅读的第一条主线将是 Dubbo 的服务发布流程。在阅读的过程中你会发现,有很多代码很相似,并且重复出现,比如这里:
private static final ProxyFactory PROXY_FACTORY = ExtensionLoader.getExtensionLoader(ProxyFactory.class).getAdaptiveExtension(); private static final Protocol PROTOCOL = ExtensionLoader.getExtensionLoader(Protocol.class).getAdaptiveExtension(); …… Invoker<?> invoker = PROXY_FACTORY.getInvoker(ref, (Class) interfaceClass, url); DelegateProviderMetaDataInvoker wrapperInvoker = new DelegateProviderMetaDataInvoker(invoker, this); Exporter<?> exporter = PROTOCOL.export(wrapperInvoker); exporters.add(exporter); ……
这段代码是 Dubbo 服务发布的关键流程,其中用到了两个类都是通过ExtensionLoader.getExtensionLoader()去获得的,这其实体现的就是Dubbo 的SPI机制,SPI 机制在 Dubbo 中被大量运用,也是 Dubbo 设计的亮点所在。
为什么要使用SPI?
这就要谈到Dubbo的架构设计了,之前提到 Dubbo 采用的是分层架构的方式,Dubbo 的设计体现了程序设计中的开闭原则,每一层都可以被另一种实现技术替换掉,而不影响上下层之间的依赖和整体逻辑的运转,这其实就是微内核架构(微内核+插件)。
微内核架构也被称为插件化架构(Plug-in Architecture),这是一种面向功能进行拆分的可扩展性架构。内核功能是比较稳定的,只负责管理插件的生命周期,不会因为系统功能的扩展而不断进行修改。功能上的扩展全部封装到插件之中,插件模块是独立存在的模块,包含特定的功能,全部可被替换,并且可以拓展内核系统的功能,而 Dubbo 最终决定采用 SPI 机制来加载插件。
开闭原则 OCP (Open-Closed Principle ):程序的设计应该是不约束扩展,即扩展开放,但又不能修改已有功能,即修改关闭。
什么是 SPI
SPI ,全称为 Service Provider Interface,直接翻译过来是服务提供者接口,是一种服务发现机制,而我们通常指的是JDK的SPI。
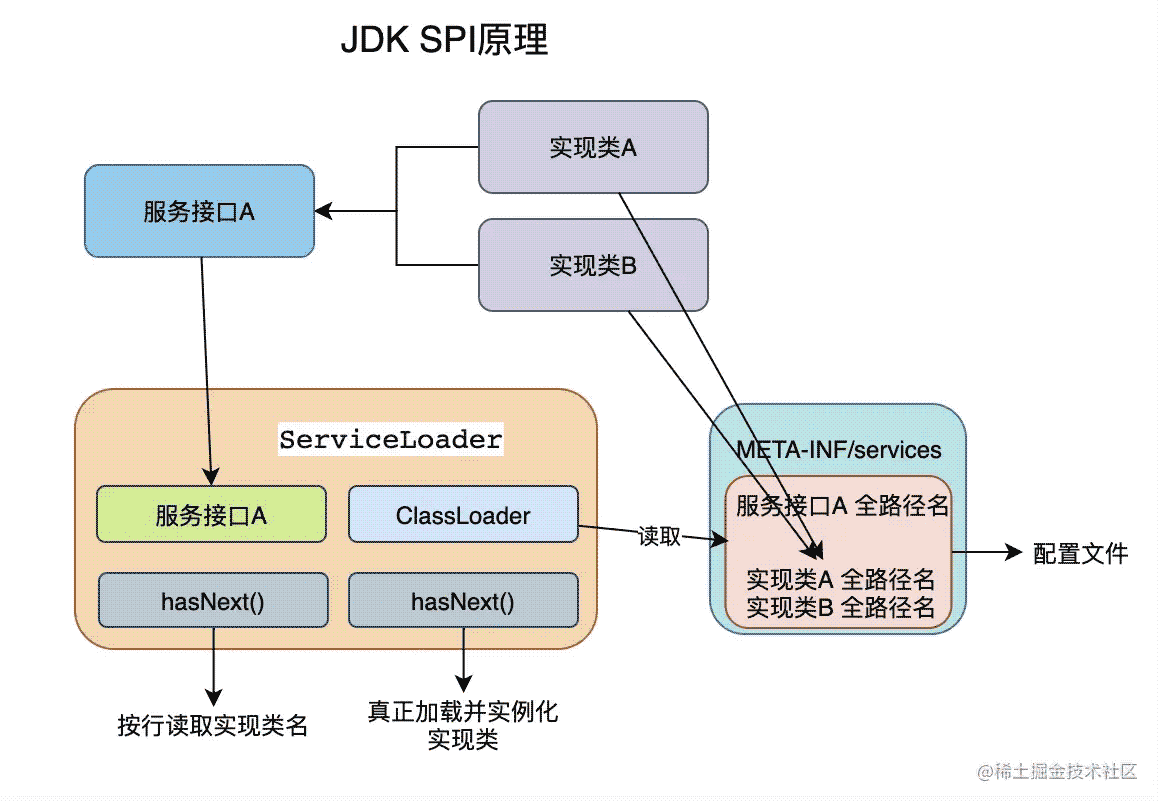
JDK SPI,它是JDK内置的一种服务发现机制,可以动态的发现服务,即服务提供商,它通过在ClassPath路径下的META-INF/services文件夹查找文件,自动加载文件里所定义的类。
根据他的定义就知道他主要是被框架开发人员使用的,通过 SPI 可以加载服务本身以外的扩展。最常用的比如JDBC驱动连接时候选择不同的驱动,对java.sql.Driver的实现就利用了SPI机制;Spring框架中也使用了很多,比如在 Spring 中为了支持Servlet3.0规范不使用web.xml,对javax.servlet.ServletContainerInitializer的实现也利用了SPI;在Dubbo中更是大量运用了SPI机制,不但有JDK SPI的运用,更重要的是 Dubbo 自己还实现了一套SPI机制。
JDK SPI 机制
当服务提供者想利用SPI机制去扩展,需要遵循以下步骤。
- 首先需要实现实现对应接口。
- 然后需要在 Classpath 下的 META-INF/services/ 目录中创建一个以服务接口全路径命命名的文件。
- 在该文件中记录服务接口的所有具体实现类,通常是在外部引入的扩展包中,比如引入JDBC的jar包。
- 做好以上配置,就可以利用JDK SPI的查找机制在META-INF/services/文件夹下根据配置来对具体的实现类加载和实例化。
如果看完上述流程还不是很清楚,请看如下示例。比如这里有接口 MySPI 需要按照上述流程按照SPI机制加载。

首先提供了两个实现类 GoodbyeMySPI 和 HelloMySPI,然后在 META-INF/services 文件夹下保存了文件org.daley.spi.demo.MySPI,文件的内容是两个实现类的全路径名。就绪之后就可以在main方法中启动demo,用ServiceLoader.load()加载 MySPI 的两个实现类,然后分别调用接口方法执行。代码如下:
/**
* @author 后端开发技术
*/
public interface MySPI {
void say();
}
public class HelloMySPI implements MySPI{
@Override
public void say() {
System.out.println("HelloMySPI say:hello");
}
}
public class GoodbyeMySPI implements MySPI {
@Override
public void say() {
System.out.println("GoodbyeMySPI say:Goodbye");
}
}
public static void main(String[] args) {
ServiceLoader<MySPI> serviceLoader = ServiceLoader.load(MySPI.class);
Iterator<MySPI> iterator = serviceLoader.iterator();
// 开始迭代执行
while (iterator.hasNext()) {
MySPI spi = iterator.next();
spi.say();
}
}
//配置文件 org.daley.spi.demo.MySPI
org.daley.spi.demo.GoodbyeMySPI
org.daley.spi.demo.HelloMySPI
//输出如下:
//GoodbyeMySPI say:Goodbye
//HelloMySPI say:hello
JDK SPI原理
看完上述 demo,你有没有好奇 JDK SPI 的原理是什么?相信你已经猜的八九不离十了。我们从demo的main方法开始追踪起。
很明显关键的代码就一行ServiceLoader.load(MySPI.class),他是整个类加载的入口。
- 调用
ServiceLoader.load(MySPI.class)开始加载,并且会拿到当前线程的类加载器。 - 开始创建一个
ServiceLoader,最终可以追踪到调用reload()方法
public static <S> ServiceLoader<S> load(Class<S> service) {
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
public static <S> ServiceLoader<S> load(Class<S> service,
ClassLoader loader)
{
return new ServiceLoader<>(service, loader);
}
private ServiceLoader(Class<S> svc, ClassLoader cl) {
// 绑定接口和类加载器
service = Objects.requireNonNull(svc, "Service interface cannot be null");
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
// 加载
reload();
}
在reload()方法中首先清空了providers,它里面存贮了所有服务接口的实现,key为实现类名,value为对象。然后便会new一个LazyIterator,LazyIterator是ServiceLoader内部实现的一个迭代器,此时还没有真正开始加载,只是保存了接口和类加载器在迭代器中。
private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
public void reload() {
providers.clear();
lookupIterator = new LazyIterator(service, loader);
}
private class LazyIterator implements Iterator<S>{
private LazyIterator(Class<S> service, ClassLoader loader) {
this.service = service;
this.loader = loader;
}
}
正如其名懒加载迭代器,在调用iterator.hasNext()时才真正发生加载。在hasNextService()方法中,第一次调用此方法会先拼接出配置SPI的文件名,在本demo中也就是META-INF/services/org.daley.spi.demo.MySPI,然后会使用类加载器加载配置文件并且将每行的内容设置到迭代器pending中,每次遍历都可以按行依次拿到实现类的名字。
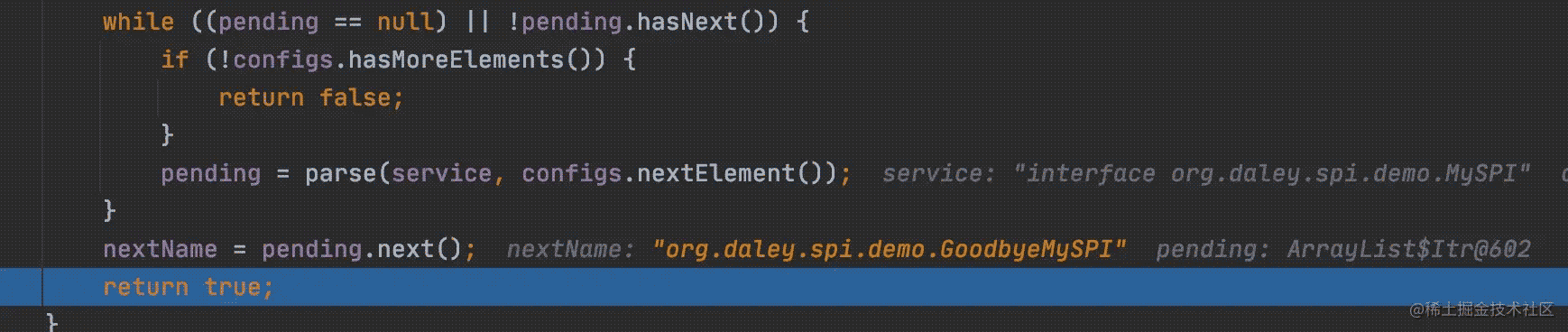
比如第一次迭代,返回第一行配置的实现类名org.daley.spi.demo.GoodbyeMySPI。到这里只是加载配置文件拿到类名,还未加载类。
public boolean hasNext() {
if (acc == null) {
return hasNextService();
} else {
……
}
}
// pengding中保存了配置文件中的实现类名,按行迭代
Iterator<String> pending = null;
private boolean hasNextService() {
……
if (configs == null) {
try {
// 设置配置文件路径 META-INF/services/org.daley.spi.demo.MySPI
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
// 第一次遍历 pendind=null
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
pending = parse(service, configs.nextElement());
}
// 按行拿到实现类名
nextName = pending.next();
return true;
}
当执行到iterator.next()的时候才会真正去加载class类。追踪此方法最终进入nextService()方法,在这里你会看到熟悉的Class.forName()以及newInstance()方法,读取类和实例化类的逻辑一目了然。到这里JDK SPI的核心逻辑就结束了。
public S next() {
if (acc == null) {
return nextService();
} else {
……
}
}
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
//当前正在迭代的实现类名
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
// 根据类路径加载class
c = Class.forName(cn, false, loader);
……
// 实例化实现类,并且保存在providers中
S p = service.cast(c.newInstance());
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service,
"Provider " + cn + " could not be instantiated",
x);
}
throw new Error(); // This cannot happen
}
简言之,通过将实现类名保存在以服务接口命名的配置文件中,放置在META-INF/services,ServiceLoader会在先读取配置文件中实现类的名字,然后根据调用newInstance()方法对其进行实例化。简化的原理图如下:
为什么不直接使用 JDK SPI
既然已经有了 JDP SPI 为什么还需要 Dubbo SPI呢?
技术的出现通常都是为了解决现有问题,通过之前的 demo,不难发现 JDK SPI 机制就存在以下一些问题:
- 实现类会被全部遍历并且实例化,假如我们只需要使用其中的一个实现,这在实现类很多的情况下无疑是对机器资源巨大的浪费,
- 无法按需获取实现类,不够灵活,我们需要遍历一遍所有实现类才能找到指定实现。
所以 Dubbo SPI 以 JDK SPI 为参考做出了改进设计,进行了性能优化以及功能增强,Dubbo SPI 机制的出现解决了上述问题。 由于 Dubbo SPI的知识点太多并且很重要,将专门安排在下一篇文章讲解,更多关于Dubbo JDK SPI原理的资料请关注脚本之家其它相关文章!