
PHP字符编码问题之GB2312 VS UTF-8解决方法
作者:
今天照着书随便写了段代码,代码意图是将字符串使用str_split()函数进行分割成数组,英文好说,但分割中文(两个中文一个数组单元)时就出问题了
看代码:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title> New Document </title>
<meta name="author" content=""/>
<meta name="keywords" content=""/>
<meta name="description" content=""/>
<link rel="stylesheet" type="text/css" href="" />
</head>
<body>
<?php
$string1 = "i am a phper";
$string2 = "这网站是脚本之家";
print_r(str_split($string1));
echo "<br />";
print_r(str_split($string2,4));
?>
</body>
</html>
测试结果打出我所料——中文乱码
复制代码 代码如下:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title> New Document </title>
<meta name="author" content=""/>
<meta name="keywords" content=""/>
<meta name="description" content=""/>
<link rel="stylesheet" type="text/css" href="" />
</head>
<body>
<?php
$string1 = "i am a phper";
$string2 = "这网站是脚本之家";
print_r(str_split($string1));
echo "<br />";
print_r(str_split($string2,4));
?>
</body>
</html>
测试结果打出我所料——中文乱码
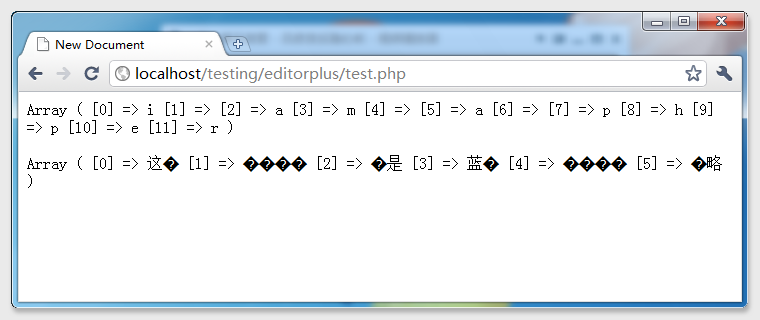
Why?Why?Why?Why?乱码是什么?什么事乱码?给我解释解释,什么,是%&的乱码!
因为英文无乱码,只有中文乱码,首先想到了编码的问题,于是突然想起来UTF-8的编码是UTF-8需要3个字节,死马当活马医吧!
于是 print_r(str_split($string2,4));这句中的4 ,就被换成了6,于是乎——看结果
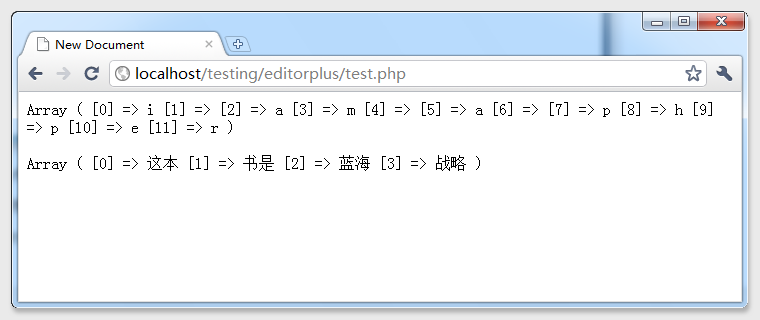
同样,你也可以试试将编码的charset的UTF-8改成GB2312,因为Unicode的编码是需要2字节的,所以说Gb2312的编码比UTF-8能够节约1/3的空间,但是如果你要兼容繁体中文、韩文、日文的其他的语言就需要使用UTF-8了。
您可能感兴趣的文章:
- 将字符串转换成gb2312或者utf-8编码的参数(js版)
- php实现utf-8和GB2312编码相互转换函数代码
- UTF-8 GBK UTF8 GB2312 之间的区别和关系介绍
- VBS实现GB2312,UTF-8,Unicode,BIG5编码转换工具
- PHP 解决utf-8和gb2312编码转换问题
- unicode utf-8 gb18030 gb2312 gbk各种编码对比
- ASP中Utf-8与Gb2312编码转换乱码问题的解决方法 页面编码声明
- MSSQL转MYSQL,gb2312转utf-8无乱码解决方法
- PHP iconv 解决utf-8和gb2312编码转换问题
- ASP UTF-8页面乱码+GB2312转UTF-8 +生成UTF-8格式的文件(编码)
- 用VBS实现的批量gb2312转utf-8,支持拖动
- 用javascript实现gb2312转utf-8的脚本
- [转]ASP实现关键词获取(各搜索引擎,GB2312及UTF-8)
- UTF-8转GB2312函数
- utf-8编码转换成gb2312
- 将编码从GB2312转成UTF-8的方法汇总(从前台、程序、数据库)