
使用Pytorch如何完成多分类问题
作者:LiBiGo
Pytorch如何完成多分类
多分类问题在最后的输出层采用的Softmax Layer,其具有两个特点:1.每个输出的值都是在(0,1);2.所有值加起来和为1.
假设![]() 是最后线性层的输出,则对应的Softmax function为:
是最后线性层的输出,则对应的Softmax function为:


输出经过sigmoid运算即可是西安输出的分类概率都大于0且总和为1。




上图的交叉熵损失就包含了softmax计算和右边的标签输入计算(即框起来的部分)
所以在使用交叉熵损失的时候,神经网络的最后一层是不要做激活的,因为把它做成分布的激活是包含在交叉熵损失里面的,最后一层不要做非线性变换,直接交给交叉熵损失。

如上图,做交叉熵损失时要求y是一个长整型的张量,构造时直接用
criterion = torch.nn.CrossEntropyLoss()

3个类别,分别是2,0,1
Y_pred1 ,Y_pred2还是线性输出,没经过softmax,还不是概率分布,比如Y_pred1,0.9最大,表示对应为第3个的概率最大,和2吻合,1.1最大,表示对应为第1个的概率最大,和0吻合,2.1最大,表示对应为第2个的概率最大,和1吻合,那么Y_pred1 的损失会比较小
对于Y_pred2,0.8最大,表示对应为第1个的概率最大,和0不吻合,0.5最大,表示对应为第3个的概率最大,和2不吻合,0.5最大,表示对应为第3个的概率最大,和2不吻合,那么Y_pred2 的损失会比较大
Exercise 9-1: CrossEntropyLoss vs NLLLoss
What are the differences?
• Reading the document:
• https://pytorch.org/docs/stable/nn.html#crossentropyloss
• https://pytorch.org/docs/stable/nn.html#nllloss
• Try to know why:
• CrossEntropyLoss <==> LogSoftmax + NLLLoss


为什么要用transform
transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307, ), (0.3081, )) ])
PyTorch读图像用的是python的imageLibrary,就是PIL,现在用的都是pillow,pillow读进来的图像用神经网络处理的时候,神经网络有一个特点就是希望输入的数值比较小,最好是在-1到+1之间,最好是输入遵从正态分布,这样的输入对神经网络训练是最有帮助的

原始图像是28*28的像素值在0到255之间,我们把它转变成图像张量,像素值是0到1
在视觉里面,灰度图就是一个矩阵,但实际上并不是一个矩阵,我们把它叫做单通道图像,彩色图像是3通道,通道有宽度和高度,一般我们读进来的图像张量是WHC(宽高通道)
在PyTorch里面我们需要转化成CWH,把通道放在前面是为了在PyTorch里面进行更高效的图像处理,卷积运算。所以拿到图像之后,我们就把它先转化成pytorch里面的一个Tensor,把0到255的值变成0到1的浮点数,然后把维度由2828变成128*28的张量,由单通道变成多通道,
这个过程可以用transforms的ToTensor这个函数实现


归一化
transforms.Normalize((0.1307, ), (0.3081, ))

这里的0.1307,0.3081是对Mnist数据集所有的像素求均值方差得到的
也就是说,将来拿到了图像,先变成张量,然后Normalize,切换到0,1分布,然后供神经网络训练
如上图,定义好transform变换之后,直接把它放到数据集里面,为什么要放在数据集里面呢,是为了在读取第i个数据的时候,直接用transform处理

模型
输入是一组图像,激活层改用Relu
全连接神经网络要求输入是一个矩阵
所以需要把输入的张量变成一阶的,这里的N表示有N个图片

view函数可以改变张量的形状,-1表示将来自动去算它的值是多少,比如输入是n128*28
将来会自动把n算出来,输入了张量就知道形状,就知道有多少个数值
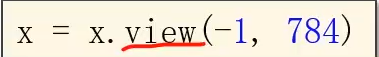

最后输出是(N,10)因为是有0-9这10个标签嘛,10表示该图像属于某一个标签的概率,现在还是线性值,我们再用softmax把它变成概率

#沿着第一个维度找最大值的下标,返回值有两个,因为是10列嘛,返回值一个是每一行的最大值,另一个是最大值的下标(每一个样本就是一行,每一行有10个量)(行是第0个维度,列是第1个维度)
MNIST数据集训练代码
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
# prepare dataset
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(), #先将图像变换成一个张量tensor。
transforms.Normalize((0.1307,), (0.3081,))
#其中的0.1307是MNIST数据集的均值,0.3081是MNIST数据集的标准差。
]) # 归一化,均值和方差
train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True,
download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False,
download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# design model using class
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
# 28 * 28 = 784
# 784 = 28 * 28,即将N *1*28*28转化成 N *1*784
x = x.view(-1, 784) # -1其实就是自动获取mini_batch
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x) # 最后一层不做激活,不进行非线性变换
model = Net()
#CrossEntropyLoss <==> LogSoftmax + NLLLoss。
#也就是说使用CrossEntropyLoss最后一层(线性层)是不需要做其他变化的;
#使用NLLLoss之前,需要对最后一层(线性层)先进行SoftMax处理,再进行log操作。
# construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
#momentum 是带有优化的一个训练过程参数
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
#enumerate()函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,
#同时列出数据和数据下标,一般用在 for 循环当中。
#enumerate(sequence, [start=0])
for batch_idx, data in enumerate(train_loader, 0):
# 获得一个批次的数据和标签
inputs, target = data
optimizer.zero_grad()
#forward + backward + update
# 获得模型预测结果(64, 10)
outputs = model(inputs)
# 交叉熵代价函数outputs(64,10),target(64)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():#不需要计算梯度。
for data in test_loader:
images, labels = data
outputs = model(images)
#orch.max的返回值有两个,第一个是每一行的最大值是多少,第二个是每一行最大值的下标(索引)是多少。
_, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度
total += labels.size(0)
correct += (predicted == labels).sum().item() # 张量之间的比较运算
print('accuracy on test set: %d %% ' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。