
Flink JobGraph生成源码解析
作者:xiangel
这篇文章主要为大家介绍了Flink JobGraph生成源码解析,有需要的朋友可以借鉴参考下,希望能够有所帮助,祝大家多多进步,早日升职加薪
引言
在DataStream基础中,由于其中的内容较多,只是介绍了JobGraph的结果,而没有涉及到StreamGraph到JobGraph的转换过程。本篇我们来介绍下JobGraph的生成的详情,重点是Operator可以串联成Chain的条件
概念
首先我们来回顾下JobGraph中的相关概念
- JobVertex:job的顶点,即对应的计算逻辑(这里用的是Vertex, 而前面用的是Node,有点差异),通过inputs记录了所有来源的Edge,而输出是ArrayList来记录
- JobEdge: job的边,记录了源Vertex和目标表Vertex.
- IntermediateDataSet: 定义了一个中间数据集,但并没有存储,只是记录了一个Producer(JobVertex)和一个Consumer(JobEdge)
JobGraph生成
前面我们在介绍部署的时候,有介绍具体是通过PipelineExecutor的execute()方法来提交对应的任务,StreamGraph到JobGraph的转换逻辑就是在该方法中处理的,具体是通过如下方法来进行处理
public static JobGraph getJobGraph(
@Nonnull final Pipeline pipeline, @Nonnull final Configuration configuration)
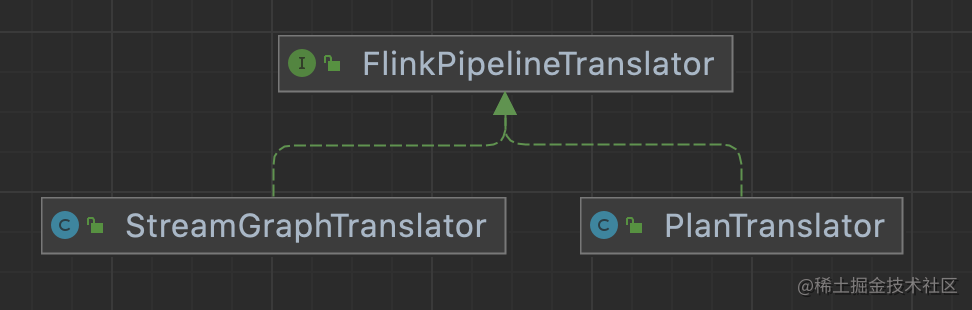
最后执行转换的类为FlinkPipelineTranslator,调用的是其中的translateToJobGraph方法。
JobGraph translateToJobGraph(
Pipeline pipeline, Configuration optimizerConfiguration, int defaultParallelism);

这里有2个不同的实现类
- StreamGraphTranslator:对StreamGraph的Pipeline进行转换处理
- PlanTranslator:对Plan类型的Pipeline进行转换处理,用于SQL场景。 而这2个分别对应到2个不同的类来生成JobGraph,分别如下:
- StreamingJobGraphGenerator
- JobGraphGenerator 本篇我们重点介绍StreamGraph到JobGraph的转换StreamingJobGraphGenerator, JogGraphGenerator这块等到介绍FlinkSQL的时候来介绍。StreamingJobGraphGenerator类中具体转换处理的逻辑如下:
private JobGraph createJobGraph() {
preValidate();
jobGraph.setJobType(streamGraph.getJobType());
jobGraph.enableApproximateLocalRecovery(
streamGraph.getCheckpointConfig().isApproximateLocalRecoveryEnabled());
// Generate deterministic hashes for the nodes in order to identify them across
// submission iff they didn't change.
Map<Integer, byte[]> hashes =
defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
// Generate legacy version hashes for backwards compatibility
List<Map<Integer, byte[]>> legacyHashes = new ArrayList<>(legacyStreamGraphHashers.size());
for (StreamGraphHasher hasher : legacyStreamGraphHashers) {
legacyHashes.add(hasher.traverseStreamGraphAndGenerateHashes(streamGraph));
}
setChaining(hashes, legacyHashes);
setPhysicalEdges();
setSlotSharingAndCoLocation();
setManagedMemoryFraction(
Collections.unmodifiableMap(jobVertices),
Collections.unmodifiableMap(vertexConfigs),
Collections.unmodifiableMap(chainedConfigs),
id -> streamGraph.getStreamNode(id).getManagedMemoryOperatorScopeUseCaseWeights(),
id -> streamGraph.getStreamNode(id).getManagedMemorySlotScopeUseCases());
configureCheckpointing();
jobGraph.setSavepointRestoreSettings(streamGraph.getSavepointRestoreSettings());
final Map<String, DistributedCache.DistributedCacheEntry> distributedCacheEntries =
JobGraphUtils.prepareUserArtifactEntries(
streamGraph.getUserArtifacts().stream()
.collect(Collectors.toMap(e -> e.f0, e -> e.f1)),
jobGraph.getJobID());
for (Map.Entry<String, DistributedCache.DistributedCacheEntry> entry :
distributedCacheEntries.entrySet()) {
jobGraph.addUserArtifact(entry.getKey(), entry.getValue());
}
// set the ExecutionConfig last when it has been finalized
try {
jobGraph.setExecutionConfig(streamGraph.getExecutionConfig());
} catch (IOException e) {
throw new IllegalConfigurationException(
"Could not serialize the ExecutionConfig."
+ "This indicates that non-serializable types (like custom serializers) were registered");
}
addVertexIndexPrefixInVertexName();
setVertexDescription();
return jobGraph;
}
重点我们介绍以下几点
生成hash值
对每个streamNode生成一个hash值,用于来标识节点,用于重新提交任务后涉及恢复作业的场景。具体生成hash值的逻辑如下:
- 如果指定了id信息,如Transformation.getUid(), 就用该值来生成hash值
- 否则使用链上的输出node和节点的输入nodes的hash值来生成一个hash值 对具体的算法细节感兴趣的同学可以深入研究StreamGraphHasherV2的具体内容。
生成chain
如果连接的2个节点满足一定的条件,就会把这2个节点放到一个chain里面,这样可以避免上下游算子间发送数据的网络开销和序列化反序列化的性能开销。判断算子是否可以组成一个chain的判断逻辑如下:
public static boolean isChainable(StreamEdge edge, StreamGraph streamGraph) {
StreamNode downStreamVertex = streamGraph.getTargetVertex(edge);
return downStreamVertex.getInEdges().size() == 1 && isChainableInput(edge, streamGraph);
}
private static boolean isChainableInput(StreamEdge edge, StreamGraph streamGraph) {
StreamNode upStreamVertex = streamGraph.getSourceVertex(edge);
StreamNode downStreamVertex = streamGraph.getTargetVertex(edge);
if (!(upStreamVertex.isSameSlotSharingGroup(downStreamVertex)
&& areOperatorsChainable(upStreamVertex, downStreamVertex, streamGraph)
&& arePartitionerAndExchangeModeChainable(
edge.getPartitioner(),
edge.getExchangeMode(),
streamGraph.getExecutionConfig().isDynamicGraph())
&& upStreamVertex.getParallelism() == downStreamVertex.getParallelism()
&& streamGraph.isChainingEnabled())) {
return false;
}
// check that we do not have a union operation, because unions currently only work
// through the network/byte-channel stack.
// we check that by testing that each "type" (which means input position) is used only once
for (StreamEdge inEdge : downStreamVertex.getInEdges()) {
if (inEdge != edge && inEdge.getTypeNumber() == edge.getTypeNumber()) {
return false;
}
}
return true;
}
具体解读如下:
- 下游节点只有1个输入边
- 上游节点和下游节点是在同一个SlotSharingGroup,slotSharingGroup在没有设置的情况下,默认为default;
- 上下游节点的算子的chaining策略是支持chain的,上游算子的chaining策略为ALWAYS\HEAD\HEAD_WITH_SOURCES,下游算子的chaining策略为ALWAYS或者(HEAD_WITH_SOURCES且上游算子为source算子,具体这些策略的说明见ChainingStrategy.java
- 边的分区策略是ForwardForConsecutiveHashPartitioner或者分区策略是ForwardPartitioner且数据交换方式(StreamExchangeMode)不是批模式
- 上下游节点的并行度一致
- StreamGraph是允许Chaining的
总结
本篇介绍了StreamGraph到JobGraph的生成流程,重点是在上下游节点是需要满足什么条件才能chain到一起的具体逻辑。
以上就是Flink JobGraph生成源码解析的详细内容,更多关于Flink JobGraph生成的资料请关注脚本之家其它相关文章!