
Pandas中Replace函数使用那些事儿
作者:西瓜WiFi
Pandas是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的,下面这篇文章主要给大家介绍了关于Pandas中Replace函数使用那些事儿,文中通过实例代码以及图文介绍的非常详细,需要的朋友可以参考下
一、Series 数据替换s.str.replace()
s.sr.replace(pat,repl,n=-1,case=None,flags=0,regex=None)
函数详解:
| pat | 要查找的字符串 |
| repl | 替换的字符串,可以调用函数 |
| n | 要进行的替换数,默认全部 |
| case | 是否区分大小写 |
| flags | re模块中的标志 |
| regex | 是否设置为正则表达式 |
1. 普通查找替换
将曹操替换为刘备
import pandas as pd
s=pd.Series(['曹操','大乔','小乔'])
s.str.replace('曹操','刘备')
2.正则表达式替换
将字符串中的‘~’和‘/’替换为'-'
import pandas as pd
s=pd.Series(['2022-5-5','2022/5/6','2022~6~9'])
s.str.replace('[~/]','-',regex=True)
3. 预编译好的正则表达式替换
将字符串中的‘~’和‘/’替换为'-'
import pandas as pd
import re
s=pd.Series(['2022-5-5','2022/5/6','2022~6~9'])
pat=re.compile('[~/]')
s.str.replace(pat,'-',regex=True)
4. 函数替换
给Series中的人名添加括号;人名和日期之间添加‘-’
import pandas as pd
import re
s=pd.Series(['Aaron2022-5-5','Bob2022-5-6','judy2022-6-9'])
s.str.replace('[a-zA-Z]+',lambda x: '('+x[0]+')'+'-',regex=True)
5. 分组替换
殊途同归,分组替换可以实现与函数替换一样的目的;
s=pd.Series(['Aaron2022-5-5','Bob2022-5-6','judy2022-6-9'])
s.str.replace('([a-zA-Z]+)',r"【\1】-",regex=True)
二、DataFrame 数据替换 df.replace()
df.replace(to_replace=None,value=None,inplace=False,limit=None,regex=False,method='pad)
函数详解:
| to_replace | 查找要替换的值 |
| value | 替换与查找匹配的值 |
| inplace | 修改原数据 |
| limit | 向前或向后填充的最大尺寸间隙 |
| regex | 是否支持正则表达式 |
| method | 替换方法 |
1. 单值替换
写入实例数据:
df=pd.DataFrame({'英雄属性':['刺客','射手','法师','战士','辅助'],
'红方英雄':['荆轲','卤蛋','甄姬','夏侯惇','项羽'],
'红方伤害':[11.20,15.34,8.57,6.98,3.69],
'红方死亡次数':['1次','10次','8次','5次','6次'],
'蓝方英雄':['赵云','马克','干将','吕布','刘禅'],
'蓝方伤害':[10.82,11.36,10.87,9.69,6.53],
'蓝方死亡次数':['5次','8次','4次','7次','10次']})
df
将荆轲替换为孙悟空;
df.replace('荆轲','孙悟空')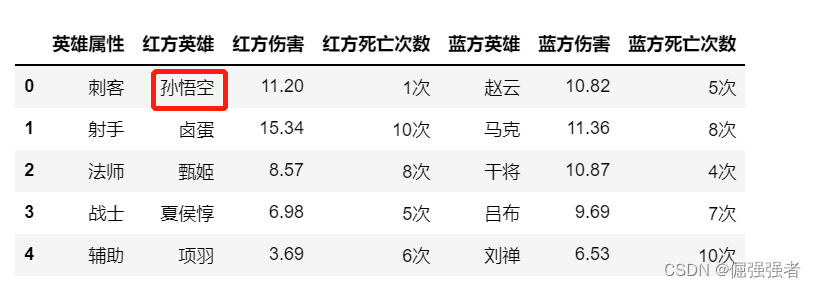
2. 列表替换
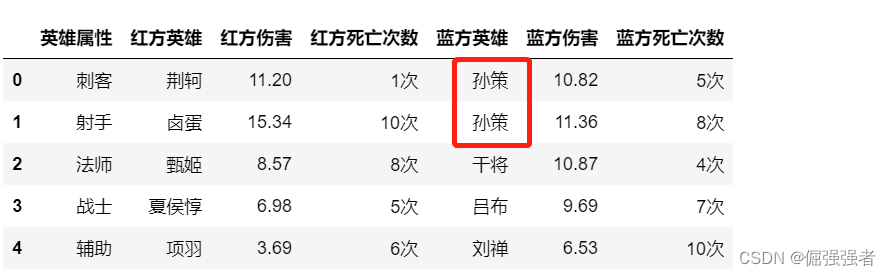
多个值替换单个值,将赵云和马克替换为孙策
df.replace(['赵云','马克'],'孙策')
多个值替换多个值,将赵云和马克替换为橘右京和虞姬;
查找值放在一个列表里,替换值放在一个列表里,需要一一对应;
df.replace(['赵云','马克'],['橘右京','虞姬'])

3.字典替换
(1)字典替换,将赵云和马克替换为橘右京和虞姬
传入字典的键为要查找的值,值为要替换的值;
df.replace({
'赵云':'橘右京',
'马克':'虞姬'
})(2)指定列替换
将红方英雄甄姬替换为貂蝉,项羽替换为钟馗;蓝方英雄吕布替换为孙策,干将替换为杨玉环;
df.replace({
'红方英雄':{
'甄姬':'貂蝉',
'项羽':'钟馗'
},
'蓝方英雄':{
'吕布':'孙策',
'干将':'杨玉环'
}
})
(3)多列替换
将红方伤害11.2,蓝方伤害11.36,9.69替换为9.999
df.replace({'红方伤害':11.2,'蓝方伤害':[11.36,9.69]},9.999)
三、DataFrame 正则替换
1. 正则表达式‘零宽断言’介绍
| 名称 | 表达式 | 解释 |
| 零宽正向先行断言 | (?=exp) | 匹配后面是exp表达式的字符串 |
| 零宽负向先行断言 | (?!exp) | 匹配后面不是exp表达式的字符串 |
| 零宽正向后行断言 | (?<=exp) | 匹配前面是exp表达式的字符串 |
| 零宽负向后行断言 | (?<!exp) | 匹配前面不是exp表达式的字符串 |
2. 单值正则替换
在红方死亡次数和蓝方死亡次数数字和‘次’之间添加‘-’
df.replace(
to_replace='(^\d+)(?=\D)',
value=r'\1-',
regex=True
)3. 列表正则替换
列表替换,给红方英雄添加‘【】’
df['红方英雄']=df['红方英雄'].replace(
regex=['^','$'],
value=['【','】'],
)
df
4. 字典正则替换
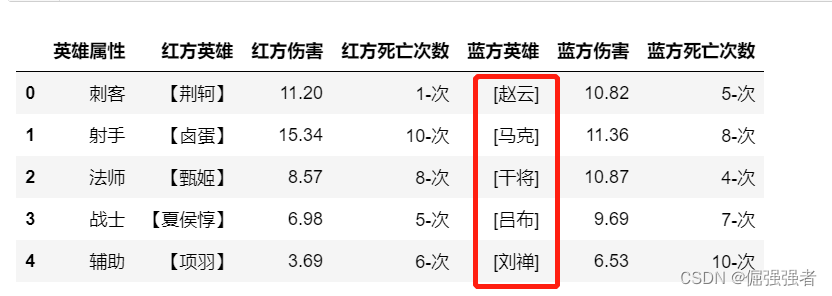
字典正则替换,给蓝方英雄添加‘[]’
df.replace(
regex={
'蓝方英雄':{'^':'[','$':']'}
})
四、DataFrame替换实例应用
原数据如下:英雄信息列后面数字为编号;
df=pd.DataFrame({'英雄属性':['刺客','射手','法师','战士','辅助'],
'英雄信息':['荆轲36','卤蛋1','甄姬6','夏侯惇10','项羽66'],
'红方英雄':['荆轲','卤蛋','甄姬','夏侯惇','项羽'],
'红方伤害':[11.20,15.34,8.57,6.98,3.69],
'红方死亡次数':['1次','10次','8次','5次','6次'],
'蓝方英雄':['赵云','马克','干将','吕布','刘禅'],
'蓝方伤害':[10.82,11.36,10.87,9.69,6.53],
'蓝方死亡次数':['5次','8次','4次','7次','10次']})
df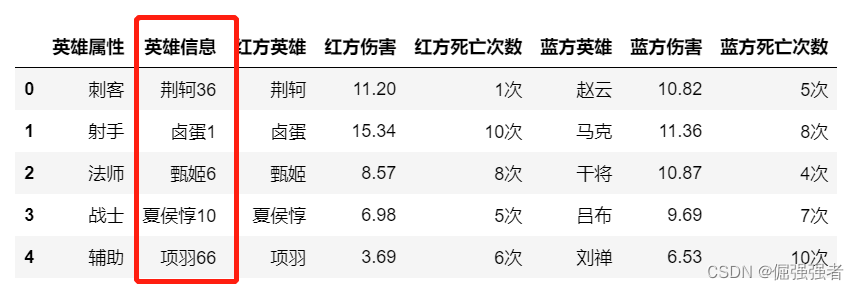
1.将编号统一为四位数字,不足四位的使用0补齐;
df['英雄信息'].str.replace(
pat='(\d+)',
repl=lambda x: '0'*(4-len(x[0]))+x[0],
regex=True
)
2. 给编号前面加上Timi,并使用‘-’分隔
df['英雄信息']=df['英雄信息'].str.replace(
pat='(\d+)',
repl=lambda x: '-Timi'+'0'*(4-len(x[0]))+x[0],
regex=True
)
df
总结
到此这篇关于Pandas中Replace函数使用的文章就介绍到这了,更多相关Pandas Replace函数使用内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!