
MySQL调优之索引在什么情况下会失效详解
作者:流烟默
前言
MySQL中提高性能的一个最有效的方式是对数据表设计合理的索引。索引提供了高效访问数据的方法,并且加快查询的速度,因此索引对查询的速度有着至关重要的影响。
- 使用索引可以快速地定位表中的某条记录,从而提高数据库查询的速度,提高数据库的性能。
- 如果查询时没有使用索引,查询语句就会扫描表中的所有记录。在数据量大的情况下,这样查询的速度回很慢。
大多数情况下都(默认)采用B+树来构建索引。只是空间列类型的索引使用R-树,并且MEMORY表还支持hash索引。
其实,用不用索引,最终都是优化器说了算。优化器是基于什么的考虑?基于cost开销(CostBaseOptimizer),它不是基于规则(Rule-BasedOptimizer),也不是基于语义,只是依据数值大小。另外,SQL语句是否使用索引,跟数据库版本、数据量、数据选择度都有关系。
本文我们尝试总结索引失效的一些场景。我们会准备class和student两个表,class插入一万条数据,student插入50万条数据。环境是MySQL8.0,InnoDB。
【1】全值匹配我最爱
系统中经常出现的SQL语句如下:
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30; EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4; EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4 AND NAME = 'abcd';
建立索引前执行:
[SQL]SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4 AND NAME = 'abcd'; 受影响的行: 0 时间: 0.308s
建立索引(age):
CREATE INDEX idx_age ON student(age);
建立索引后执行:
[SQL]SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4 AND NAME = 'abcd'; 受影响的行: 0 时间: 0.113s

继续创建索引(age,classId):
CREATE INDEX idx_age_classid ON student(age,classId);
建立索引后执行:
[SQL]SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4 AND NAME = 'abcd'; 受影响的行: 0 时间: 0.007s

继续创建索引(age,classId,NAME):
CREATE INDEX idx_age_classid_name ON student(age,classId,NAME);
建立索引后执行:
[SQL]SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4 AND NAME = 'abcd'; 受影响的行: 0 时间: 0.000s # 其实必然不是0,只是更小了

从执行计划可以看到,MySQL会帮我们选择最多包含查询列的联合索引。
【2】最佳左前缀法则
在MySQL建立联合索引时会遵守最佳左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。
举例:age、name可以用到索引。
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name = 'abcd' ;

虽然可以正常使用,但是只有部分被使用到了。而且MySQL优化器考虑的索引是idx_age,而非idx_age_classid_name。
举例2:
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.classid=1 AND student.name = 'abcd';

可以看到,没有age开头 ,完全没有用到索引。
举例3:索引idx_age_classid_name还能否正常使用?
# MySQL会进行优化,形成age,classid,name以符合联合索引idx_age_classid_name EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE classid=4 AND student.age=30 AND student.name = 'abcd';

如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。
我们删掉索引idx_age 、idx_age_classid 再次执行查询age and name,没有中间的classid。
DROP INDEX idx_age ON student; DROP INDEX idx_age_classid ON student; EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name = 'abcd';

这里key_len=5,说明只用到了联合索引的一部分–age用到了索引。因为其中间环节 classid不存在, 故而不能完全使用联合索引。
结论 : MySQL可以为多个字段创建索引,一个索引可以包括16个字段。对于多列索引,过滤条件要使用索引必须按照索引建立时的顺序,依次满足,一旦跳过某个字段,索引后面的字段都无法被使用。如果查询条件中没有使用这些字段中第一个字段时,多列(或联合)索引不会被使用。
对于=值查询,如果where中条件查询没有按照联合索引字段顺序编写,MySQL优化器会进行调优以使其满足联合索引字段顺序。
【3】主键插入顺序
对于一个使用InnoDB存储引擎的表来说,在我们没有显示的创建索引时,表中的数据实际上都是存储在聚簇索引的叶子节点的。而记录又是存储在数据页中的,数据页和记录又是按照记录主键值从小到大的顺序进行排序。所以如果我们插入的记录的主键值是依次增大的话,那我们每插满一个数据页就换到下一个数据页继续插。
而如果我们插入的主键值忽大忽小的话,就比较麻烦了。假设某个数据页存储的记录已经满了,它存储的主键值在1~100之间:
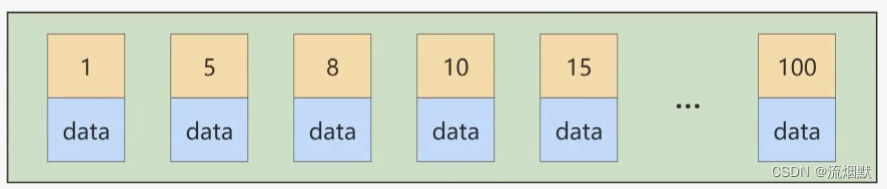
如果此时再插入一条主键值为9的记录,那它插入的位置就如下图:
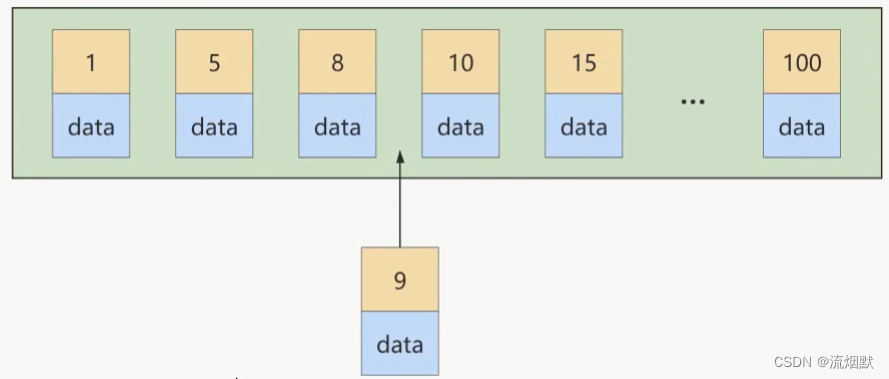
可这个数据页已经满了,再插进来咋办呢?我们需要把当前页面分裂成两个页面,把本页中的一些记录移动到新创建的这个页中。页面分裂和记录移位意味着什么?意味着性能损耗! 所以如果我们想进来避免这样无谓的性能损耗,最好让插入的记录的主键值依次递增,这样就不会发生这样的性能损耗了。
所以我们建议:让主键具有AUTO_INCREMENT,让存储引擎自己为表生成主键,而不是我们手动插入,比如person_info表:
create table person_info( id int unsigned not null auto_increment, name varchar(100) not null, birthday date not null, phone_numnber char(11) not null, country varchar(100) not null, primary key (id), key idx_name_bd_ph_num(name(10),birthday,phone_number) )
我们自定义的主键列id拥有AUTO_INCREMENT属性,在插入记录时存储引擎会自动为我们填入自增的主键值。这样的主键占用空间小,顺序写入,减少页分裂。
【4】计算、函数、类型转换(自动或手动)导致索引失效
如下两条SQL,哪个更好呢?其实是第一条,能够使用到索引,第二条有了函数计算。
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE 'abc%'; EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc';
我们创建索引(NAME):
CREATE INDEX idx_name ON student(NAME);
查看第一条SQL的执行计划:

查看第二条SQL的执行计划:

对比执行计划可以看到,第一条SQL使用到了索引,第二条SQL的type=all表示全表扫描。说明函数计算或导致索引失效。
我们再看一下数学计算:
CREATE INDEX idx_sno ON student(stuno); EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno+1 = 900001;

如上图所示,SQL中有数学计算,执行计划中 type=all表示没有使用索引进行了全表扫描。我们再看下面这个SQL,很显然其会使用到索引。这就说明数学计算会导致索引失效。
EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno = 900000;

最后我们再看一下类型转换
字符串类型一定不要忘记单引号,否则索引失效。
# 会进行隐式类型转换 ,索引失效 EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME = 123;

EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME = '123';

对比二者的执行计划可知,类型转换会导致索引失效。
【5】范围条件右边的列索引失效
首先删除表student的索引:
alter table student drop index idx_name; alter table student drop index idx_age; alter table student drop index idx_age_classid;
查看当前索引:show index from student;

对于如下SQL,索引idx_age_classid_name还能够正常使用吗?
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.classId > 20 AND student.name = 'abc' ;
执行计划如下所示,key_len=10,说明只有age和classid用到了索引。

这时候即使交换次序,也是没有意义的,如下所示:
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name = 'abc' AND student.classId>20;
那么如何使其能够使用到索引呢?如下所示创建索引(age,NAME,classId)。
CREATE INDEX idx_age_name_cid ON student(age,NAME,classId);
这时再执行上面SQL,可以看到充分用到了联合索引。

对于 下面这个SQL,执行计划是一样的。查询优化器对于and条件会进行顺序的调整,以满足联合索引的顺序。
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.classId > 20 AND student.name = 'abc' ;

总结
- 范围右边的列不能使用索引。比如 < 、<=、 >、 >=、 between。
- 这个右边指的是联合索引字段的右边,至于SQL where中的and条件,查询优化器是可以进行调整的。
- 创建的联合索引中,务必把范围涉及到的字段写在最后。
【6】不等于(!=或者 <>) 索引失效
为name字段创建索引:
CREATE INDEX idx_name ON student(NAME);
进行等值判断,正常使用索引:
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name = 'abc' ;

对于不等判断,查看索引是否失效:
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name <> 'abc' ;

EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name != 'abc' ;

可以看到,两条SQL均为使用到索引。
【7】is null可以使用索引,is not null无法使用索引
is null可以触发索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NULL;

EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME IS NULL;

is not null无法使用索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NOT NULL;

EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME IS NOT NULL;

结论: 最好在设计数据表的时候就将字段设置为not null约束,比如你可以将int类型的字段,默认值设置为0.将字符类型的默认值设置为空字符('') 。同理,在查询中使用 not like 也无法使用索引,导致全表扫描。
【8】like以通配符%开头索引失效
在使用like关键字进行查询的查询语句中,如果匹配字符串的第一个字符为“%”,索引就不会起作用。只有"%"不在第一个位置,索引才会起作用。
使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME LIKE 'ab%';

没有用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME LIKE '%ab%';

【9】OR前后存在非索引的列,索引失效
在where子句中,如果在or前的条件列进行了索引,而在or后的条件列没有进行索引,那么索引会失效。也就是说,OR 前后的两个条件中的列都是索引列时,查询中才会使用到索引。
因为OR的含义就是两个只要满足一个即可,因此只有一个条件列进行了索引是没有意义的。只要有条件列没有进行索引,就会进行全表扫描,因此索引的条件列也会失效。
SHOW INDEX FROM student; # 删除索引 alter table student drop index idx_age_classid_name; alter table student drop index idx_age_name_cid; alter table student drop index idx_sno; alter table student drop index idx_name; #创建索引 CREATE INDEX idx_age ON student(age);
这时我们查询语句使用OR关键字的情况(age有索引,classid没有索引)
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR classid = 100;

可以看到,是没有使用到索引的。如果我们为classid创建索引呢?
CREATE INDEX idx_cid ON student(classid); EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age = 10 OR classid = 100;

可以看到,其使用到了索引,type=index_merge。简单来说,index_merge就是对age和classid分别进行了扫描,然后将这两个结果集进行了合并。这样做的好处就是避免了全表扫描。
【10】数据库和表的字符集统一使用utf8mb4
统一使用utf8mb4(5.5.3版本以上支持)兼容性更好,统一字符集可以避免由于字符集转换产生的乱码。
不同的字符集进行比较前需要进行转换会造成索引失效。
一般性建议:
- 对于单列索引,尽量选择针对当前query过滤性更好的索引;
- 在选择组合索引的时候,当前query中过滤性最好的字段在索引字段顺序中,位置越靠前越好;
- 在选择组合索引的时候,尽量选择能够包含当前query中的where子句中更多字段的索引;
- 在选择组合索引的时候,如果某个字段可能出现范围查询时,尽量把这个字段放在索引次序的最后面。
总结
到此这篇关于MySQL调优之索引在什么情况下会失效的文章就介绍到这了,更多相关MySQL索引失效内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!