
Pandas数据分析之groupby函数用法实例详解
作者:Mr_Darcy8
正文
今天本人在赶学校课程作业的时候突然发现groupby这个分组函数还是蛮有用的,有了这个分组之后你可以实现很多统计目标。
当然,最主要的是,他的使用非常简单
本期我们以上期作业为例,单走一篇文章来看看这个函数可以实现哪些功能:
(本期需要准备的行囊):
- jupyter notebook环境(anaconda自带)
- pandas第三方库
- numpy第三方库(也许会用吧)
- 能运行以上依赖的电脑和舒服的外设
- 一定的python基础
- 需要是吃饱喝足的你,带上能运作的小脑瓜来继续
一、了解groupby
这是一个函数,一般作用于dataframe上,有返回值,不改变原变量。输出的是原dataframe按照传入参数分组后的结果。

我们一通引入获得了一个dataframe,按照“user”进行了分组,发现得到的是一个dataframegroupby对象。这个对象内部是什么呢?我们用遍历循环来看看:
for i in f.groupby("user"):
print(i)

发现这个对象内部是一个个元组,每个元组的第一个元素是我们设定的分组依据的值
(例如这里我们设定的分组依据是user,这里第一个元组包含的是user为19500时的所有记录,元组第一个元素就是19500)
而当我们输出元组里的第二个元素的时候,发现得到的是类似dataframe的结果
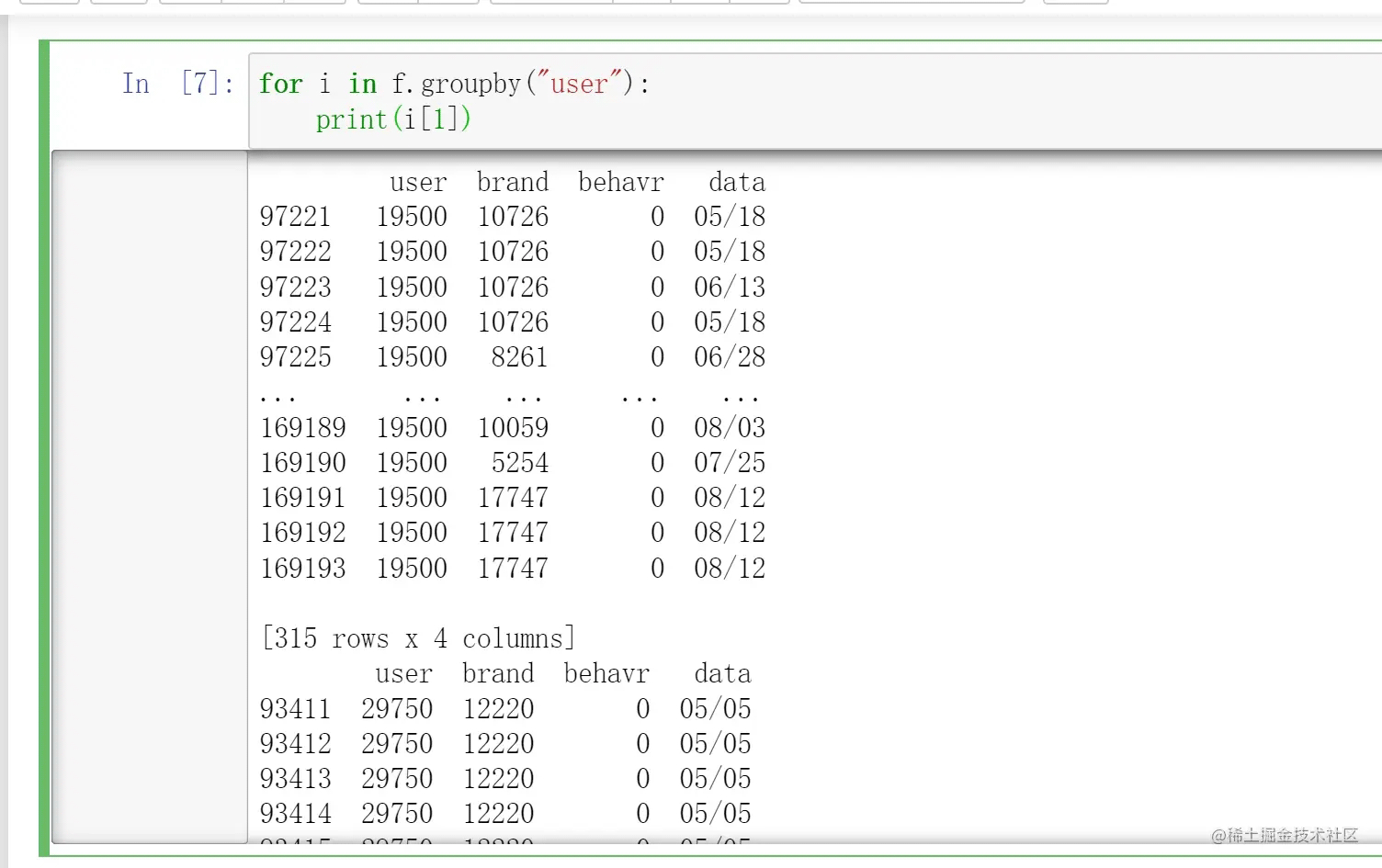
看前面user下面的数据,整齐划一,是不是?o(〃^▽^〃)o
二、数据文件简介
文章中所用数据为某时段内消费者的行为数据。user为消费者编号,brand为品牌编号,behavr为消费者行为(0代表浏览,1代表购买,2代表收藏,3代表加入购物车。且允许存在不浏览直接购买的行为)
接下来我们要针对这些数据进行处理,输出一些有用的结果
三、求各个商品购买量
因为要求统计的“购买”行为属于behavr列中的某特殊值。很容易想到先用条件筛选选出所有购买的记录,再用groupby按各个商品分类,再用size()方法统计分组后每组的数量,以此输出各个商品的购买量。

那么会了这个之后来举一反三一下:求各个商品浏览量
自行思考一下再往下翻哦

没错,就是改一下一开始条件过滤的数值即可。把购买(1)改成浏览(0)
四、求各个商品转化率
商业数据分析经常会遇到一个数据量——转化率,其实就是购买的数量比上浏览的数量。以此来看这个商品是否足够吸引人。
我们这里在上面已经计算出了各个商品的浏览量和购买量,事实上只需要比一比就可以了。
正好,pandas的series计算是我们想要的,他会根据键值对去分别计算
这个series里user名字是键,数量是值,非常完美符合series计算设定,我们直接除一下就行。
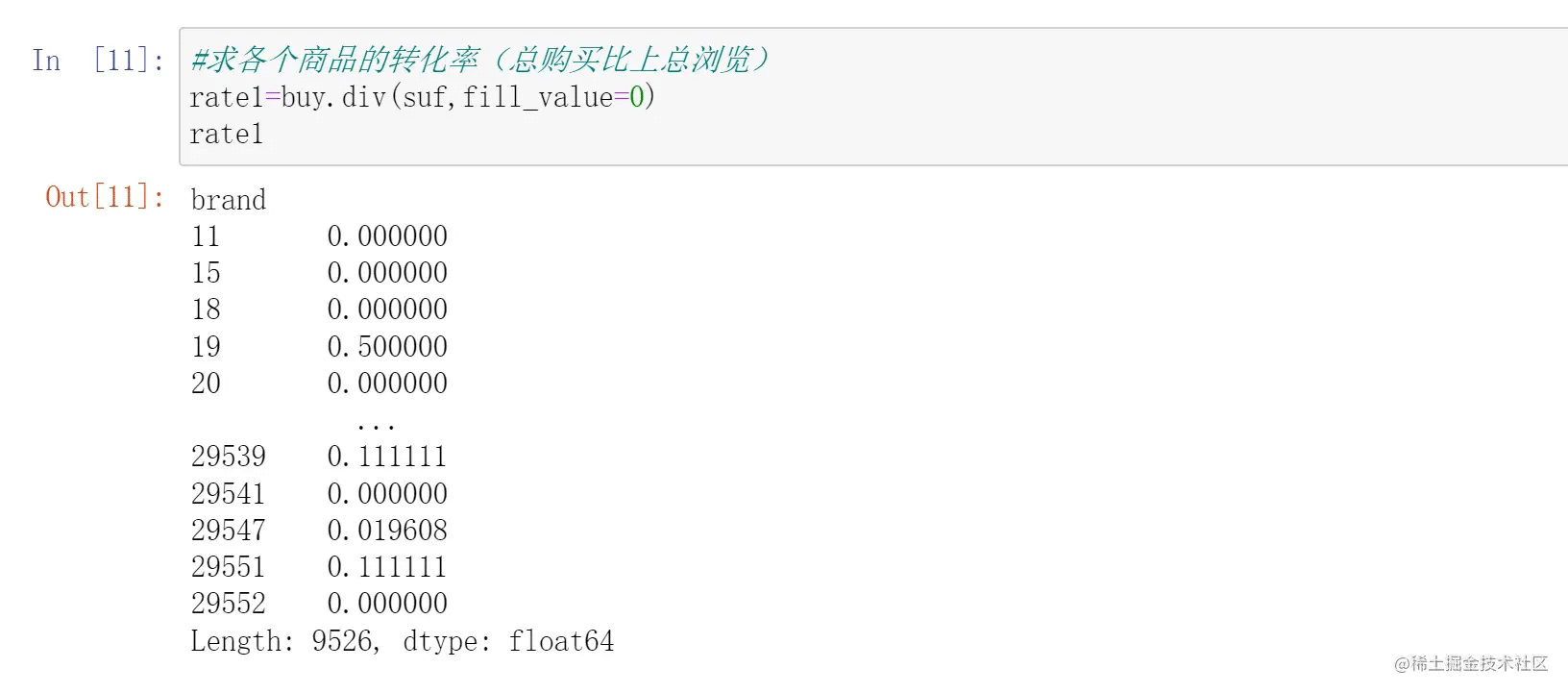
pandas用.div()来实现比值功能(前面的比后面的)。
要注意的是,series计算可能会带来缺失值,因为两个series计算的时候并不能保证两个series的键完全一样
即有可能出现前一个series有的键而后一个没有。比如这里可以看出brand 11就只有浏览没有购买,因此统计购买量的时候没有11这个键,但是浏览量中有11这个键。
在计算的时候不共有的键会以缺失值的形式出现,即NaN:

如果我们不想看到这个缺失值NaN,在div内添加fill_value参数可以把缺失值补充上

五、转化率最高的30个商品及其转化率
这就需要用到排序了。其实也很简单。我们把前面计算好的转化率用sort_values()函数排序之后输出前30个即可:
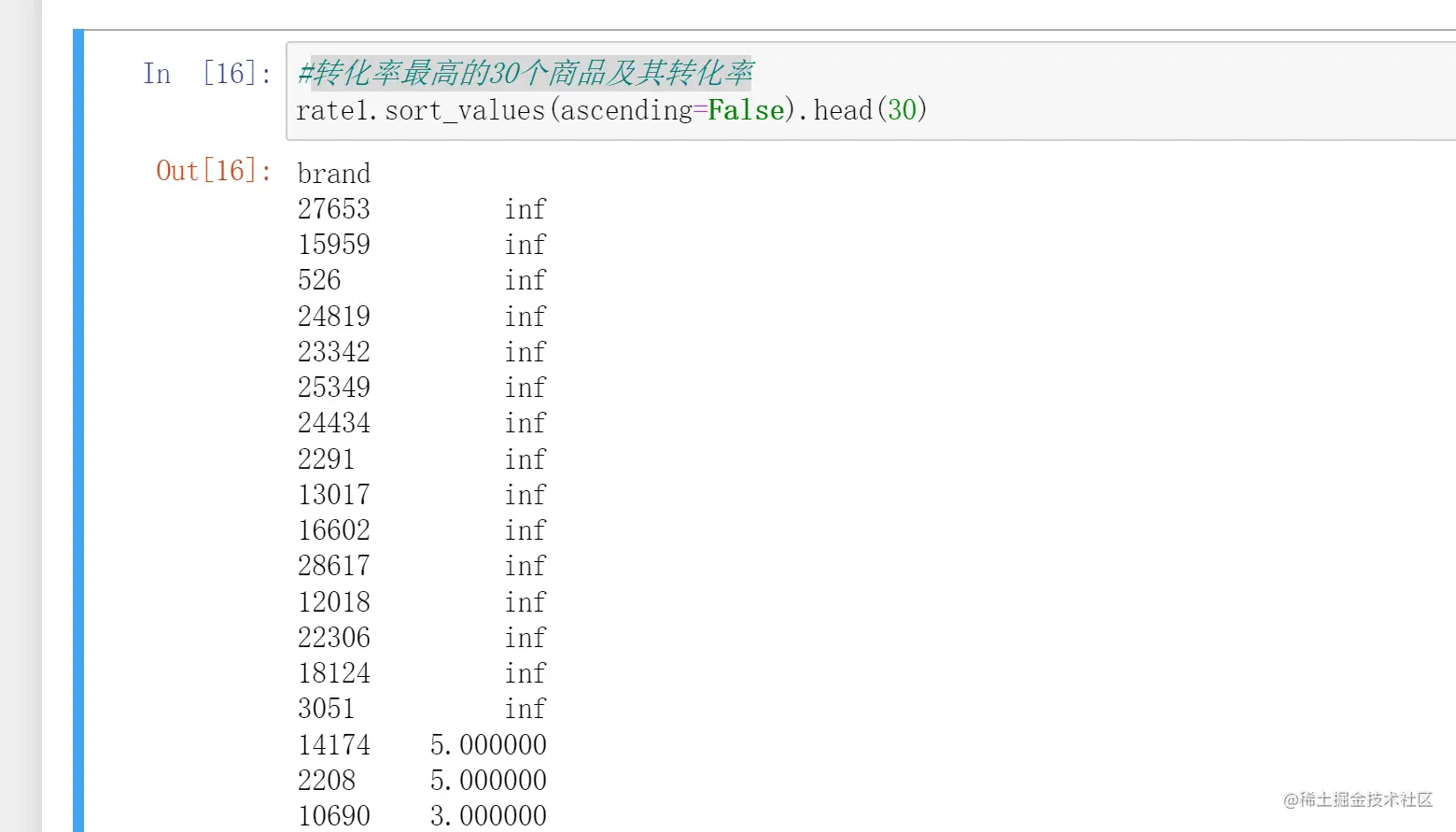
- sort_value()函数中设置ascending参数为False即为降序,默认为True升序
- head(n)用来输出前n个,同理tail(n)用来输出最后n个
小小の总结
其实我们不难发现,python语言其实本身过于“高级”。他不需要你思考用什么算法来完成这些操作(特别是你本身还在用第三方库的时候)。
她总有相关的函数或者方法可以替你完成。并且这个函数内部可能是C语言等基础语言实现的,代码效率会比你自己在python上手码要快很多
作为使用者,想要快速入门的话,你所需要的——
只是把这些都记住就行了
大概这就是一个像文科一样的编程语言吧……
以上就是Pandas数据分析之groupby函数用法实例详解的详细内容,更多关于Pandas数据分析groupby函数的资料请关注脚本之家其它相关文章!