
Python Pandas读写txt和csv文件的方法详解
作者:无 羡ღ
这篇文章主要为大家详细介绍了Python Pandas实现读写txt和csv文件查找的方法,文中的示例代码积极性,感兴趣的小伙伴可以跟随小编一起了解一下
一、文本文件
文本文件,主要包括csv和txt两种等,相应接口为read_csv()和to_csv(),分别用于读写数据
1. read_csv()
格式代码:
pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression='infer', thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, escapechar=None, comment=None, encoding=None, dialect=None, tupleize_cols=None, error_bad_lines=True, warn_bad_lines=True, skipfooter=0, doublequote=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None)
常用参数:
- filepath_or_buffer:文件路径
- sep=',':默认以,为数据分隔符
- skiprows:跳过前几行
- nrows :只读前几行
- parse_dates = [‘col_name’]:指定某行读取为日期格式
- index_col = [‘col_1’,‘col_2’]:读取指定的几列
- error_bad_lines = False :当某行数据有问题时,不报错,直接跳过,处理脏数据时使用
- na_values = ‘NULL’:将NULL识别为空值
- header = 0:表示以数据的第一行为列索引
- encoding = “utf-8”:表明以utf-8为编码规则。
- names = range(0,50)):表示以[0…49]为列索引的名字
(1)读取csv文件:
>>> import pandas as pd >>> >>> df = pd.read_csv(r"E:\Python学习\test.csv") >>> print(df) name age 0 小红 10 1 小明 20 2 小白 30 >>> print(type(df)) <class 'pandas.core.frame.DataFrame'> >>> # 行和列 >>> print(df.shape) (3, 2) >>> print(list(df.columns)) ['name', 'age']
(2)读取txt文件:
>>> df = pd.read_csv(r"E:\Python学习\test.txt") >>> print(df) 北京 0 上海 1 成都 2 深圳 3 广州 4 广东
skiprows
跳过前n行
>>> df = pd.read_csv(r"E:\Python学习\test.csv", skiprows=2) >>> print(df) 小明 20 0 小白 30
nrows
只读前几行
>>> df = pd.read_csv(r"E:\Python学习\test.csv", nrows =2) >>> print(df) name age 0 小红 10 1 小明 20
index_col
index_col = [‘col_1’,‘col_2’]:读取指定的几列。整数或者字符串或者整数/字符串列表。指定用作的行标签的列。
感觉有问题,和我想象中不同:
>>> df = pd.read_csv(r"E:\Python学习\test.csv", index_col =['name'])
>>> print(df)
age
name
小红 10
小明 20
小白 30
>>> df = pd.read_csv(r"E:\Python学习\test.csv", index_col=1)
>>> print(df)
name
age
10 小红
20 小明
30 小白
names
names = range(0,50):表示以[0…49]为列索引的名字
不与header=0共同使用:
>>> df = pd.read_csv(r"E:\Python学习\test.csv", names=['姓名', '年龄'])
>>> print(df)
姓名 年龄
0 name age
1 小红 10
2 小明 20
3 小白 30
与header=0共同使用:
>>> df = pd.read_csv(r"E:\Python学习\test.csv", header=0, names=['姓名', '年龄']) >>> print(df) 姓名 年龄 0 小红 10 1 小明 20 2 小白 30
2. to_csv()
格式代码:
pd.to_csv(path_or_buf,sep,na_rep,columns,header,index)
常用参数:
path_or_buf:str:放文件名、相对路径、文件流等。
sep:分隔符。与read_csv()中sep参数意思一样。
na_rep:将NaN转换为特定值。
columns:指定哪些列写进去。
header;默认header=0,如果没有表头,设置header=None。
index:关于索引的,默认True,写入索引。
(1)写入csv文件:
>>> import pandas as pd
>>>
>>> data = [{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}]
>>> df = pd.DataFrame(data)
>>> print(df)
A B C
0 1 2 NaN
1 3 4 5.0
>>> print(type(df))
<class 'pandas.core.frame.DataFrame'>
>>> df.to_csv('test1.csv')
>>>
可以看到生成了新文件:
我们读取看看:
>>> df1 = pd.read_csv(r"test1.csv", header=0, encoding="utf-8") >>> print(df1) A B C 0 1 2 NaN 1 3 4 5.0
(2)写入txt文件:
>>> data = [{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}]
>>> df = pd.DataFrame(data)
>>> df.to_csv('test1.txt')
生成新文件:

sep
设置分隔符
>>> data = [{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}]
>>> df = pd.DataFrame(data)
>>> df.to_csv('test2.csv', sep=';') # 设置;号为分割符
可以看到分隔符为分号:
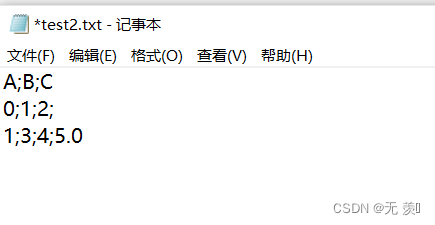
na_rep
na_rep:将NaN转换为特定值。
>>> data = [{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}]
>>> df = pd.DataFrame(data)
>>> df.to_csv('test3.csv', na_rep='100') # 空值替换为100
>>>
>>> df1 = pd.read_csv('test3.csv')
>>> print(df1)
Unnamed: 0 A B C
0 0 1 2 100.0
1 1 3 4 5.0
columns
columns:指定哪些列写进去。
>>> data = [{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}]
>>> df = pd.DataFrame(data)
>>> df.to_csv('test4.csv', columns=['A','B']) # 只写入A、B列
>>>
>>> df1 = pd.read_csv('test4.csv')
>>> print(df1)
Unnamed: 0 A B
0 0 1 2
1 1 3 4
header
header;默认header=0,如果没有表头,设置header=None。
>>> data = [{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}]
>>> df = pd.DataFrame(data)
>>> df.to_csv('test5.csv', header=None)
>>>
>>> df1 = pd.read_csv('test5.csv')
>>> print(df1)
0 1 2 Unnamed: 3
0 1 3 4 5.0
index
index:关于索引的,默认True,写入索引
不保留索引:
>>> data = [{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}]
>>> df = pd.DataFrame(data)
>>> df.to_csv('test6.csv', index=False)
>>>
>>> df1 = pd.read_csv('test6.csv')
>>> print(df1)
A B C
0 1 2 NaN
1 3 4 5.0
以上就是Python Pandas读写txt和csv文件的方法详解的详细内容,更多关于Python Pandas读写txt csv的资料请关注脚本之家其它相关文章!