
yolov5中train.py代码注释详解与使用教程
作者:Charms@
train.py里面加了很多额外的功能,使得整体看起来比较复杂,其实核心部分主要就是 读取数据集,加载模型,训练中损失的计算,下面这篇文章主要给大家介绍了关于yolov5中train.py代码注释详解与使用的相关资料,需要的朋友可以参考下
前言
最近在用yolov5参加比赛,yolov5的技巧很多,仅仅用来参加比赛,着实有点浪费,所以有必要好好学习一番,在认真学习之前,首先向yolov5的作者致敬,对了我是用的版本是v6。每每看到这些大神的作品,实在是有点惭愧,要学的太多了
1. parse_opt函数
def parse_opt(known=False):
"""
argparse 使用方法:
parse = argparse.ArgumentParser()
parse.add_argument('--s', type=int, default=2, help='flag_int')
"""
parser = argparse.ArgumentParser()
# weights 权重的路径./weights/yolov5s.pt....
# yolov5提供4个不同深度不同宽度的预训练权重 用户可以根据自己的需求选择下载
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
# cfg 配置文件(网络结构) anchor/backbone/numclasses/head,训练自己的数据集需要自己生成
# 生成方式——例如我的yolov5s_mchar.yaml 根据自己的需求选择复制./models/下面.yaml文件,5个文件的区别在于模型的深度和宽度依次递增
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
# data 数据集配置文件(路径) train/val/label/, 该文件需要自己生成
# 生成方式——例如我的/data/mchar.yaml 训练集和验证集的路径 + 类别数 + 类别名称
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
# hpy超参数设置文件(lr/sgd/mixup)./data/hyps/下面有5个超参数设置文件,每个文件的超参数初始值有细微区别,用户可以根据自己的需求选择其中一个
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
# epochs 训练轮次, 默认轮次为300次
parser.add_argument('--epochs', type=int, default=300)
# batchsize 训练批次, 默认bs=16
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
# imagesize 设置图片大小, 默认640*640
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
# rect 是否采用矩形训练,默认为False
parser.add_argument('--rect', action='store_true', help='rectangular training')
# resume 是否接着上次的训练结果,继续训练
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
# nosave 不保存模型 默认False(保存) 在./runs/exp*/train/weights/保存两个模型 一个是最后一次的模型 一个是最好的模型
# best.pt/ last.pt 不建议运行代码添加 --nosave
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
# noval 最后进行测试, 设置了之后就是训练结束都测试一下, 不设置每轮都计算mAP, 建议不设置
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
# noautoanchor 不自动调整anchor, 默认False, 自动调整anchor
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
# evolve参数进化, 遗传算法调参
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
# bucket谷歌优盘 / 一般用不到
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
# cache 是否提前缓存图片到内存,以加快训练速度,默认False
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
# mage-weights 使用图片采样策略,默认不使用
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
# device 设备选择
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
# multi-scale 多测度训练
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
# single-cls 数据集是否多类/默认True
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
# optimizer 优化器选择 / 提供了三种优化器
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
# sync-bn:是否使用跨卡同步BN,在DDP模式使用
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
# workers/dataloader的最大worker数量
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
# 保存路径 / 默认保存路径 ./runs/ train
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
# 实验名称
parser.add_argument('--name', default='exp', help='save to project/name')
# 项目位置是否存在 / 默认是都不存在
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
# cos-lr 余弦学习率
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
# 标签平滑 / 默认不增强, 用户可以根据自己标签的实际情况设置这个参数,建议设置小一点 0.1 / 0.05
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
# 早停止忍耐次数 / 100次不更新就停止训练
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
# --freeze冻结训练 可以设置 default = [0] 数据量大的情况下,建议不设置这个参数
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
# --save-period 多少个epoch保存一下checkpoint
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
# --local_rank 进程编号 / 多卡使用
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
# Weights & Biases arguments
# 在线可视化工具,类似于tensorboard工具,想了解这款工具可以查看https://zhuanlan.zhihu.com/p/266337608
parser.add_argument('--entity', default=None, help='W&B: Entity')
# upload_dataset: 是否上传dataset到wandb tabel(将数据集作为交互式 dsviz表 在浏览器中查看、查询、筛选和分析数据集) 默认False
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
# bbox_interval: 设置界框图像记录间隔 Set bounding-box image logging interval for W&B 默认-1 opt.epochs // 10
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
# 使用数据的版本
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
# 传入的基本配置中没有的参数也不会报错# parse_args()和parse_known_args()
# parse = argparse.ArgumentParser()
# parse.add_argument('--s', type=int, default=2, help='flag_int')
# parser.parse_args() / parse_args()
opt = parser.parse_known_args()[0] if known else parser.parse_args()
return opt2. main函数
2.1 main函数——打印关键词/安装环境
def main(opt, callbacks=Callbacks()):
############################################### 1. Checks ##################################################
if RANK in [-1, 0]:
# 输出所有训练参数 / 参数以彩色的方式表现
print_args(FILE.stem, opt)
# 检查代码版本是否更新
check_git_status()
# 检查安装是否都安装了 requirements.txt, 缺少安装包安装。
# 缺少安装包:建议使用 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
check_requirements(exclude=['thop'])2.2 main函数——是否进行断点训练
############################################### 2. Resume ##################################################
# 初始化可视化工具wandb,wandb使用教程看https://zhuanlan.zhihu.com/p/266337608
# 断点训练使用教程可以查看:https://blog.csdn.net/CharmsLUO/article/details/123410081
if opt.resume and not check_wandb_resume(opt) and not opt.evolve: # resume an interrupted run
# isinstance()是否是已经知道的类型
# 如果resume是True,则通过get_lastest_run()函数找到runs为文件夹中最近的权重文件last.pt
ckpt = opt.resume if isinstance(opt.resume, str) else get_latest_run() # specified or most recent path
# 判断是否是文件
assert os.path.isfile(ckpt), 'ERROR: --resume checkpoint does not exist'
# # 相关的opt参数也要替换成last.pt中的opt参数 safe_load()yaml文件加载数据
with open(Path(ckpt).parent.parent / 'opt.yaml', errors='ignore') as f:
# argparse.Namespace 可以理解为字典
opt = argparse.Namespace(**yaml.safe_load(f)) # replace
opt.cfg, opt.weights, opt.resume = '', ckpt, True # reinstate
# 打印断点训练信息
LOGGER.info(f'Resuming training from {ckpt}')
else:
# 不使用断点训练就在加载输入的参数
opt.data, opt.cfg, opt.hyp, opt.weights, opt.project = \
check_file(opt.data), check_yaml(opt.cfg), check_yaml(opt.hyp), str(opt.weights), str(opt.project) # checks
assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
# opt.evolve=False,opt.name='exp' opt.evolve=True,opt.name='evolve'
if opt.evolve:
if opt.project == str(ROOT / 'runs/train'): # if default project name, rename to runs/evolve
opt.project = str(ROOT / 'runs/evolve')
opt.exist_ok, opt.resume = opt.resume, False # pass resume to exist_ok and disable resume
# 保存相关信息
opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))
2.3 main函数——是否分布式训练
# ############################################## 3.DDP mode ###############################################
# 选择设备cpu/cuda
device = select_device(opt.device, batch_size=opt.batch_size)
# 多卡训练GPU
if LOCAL_RANK != -1:
msg = 'is not compatible with YOLOv5 Multi-GPU DDP training'
assert not opt.image_weights, f'--image-weights {msg}'
assert not opt.evolve, f'--evolve {msg}'
assert opt.batch_size != -1, f'AutoBatch with --batch-size -1 {msg}, please pass a valid --batch-size'
assert opt.batch_size % WORLD_SIZE == 0, f'--batch-size {opt.batch_size} must be multiple of WORLD_SIZE'
assert torch.cuda.device_count() > LOCAL_RANK, 'insufficient CUDA devices for DDP command'
# 根据编号选择设备
#使用torch.cuda.set_device()可以更方便地将模型和数据加载到对应GPU上, 直接定义模型之前加入一行代码即可
# torch.cuda.set_device(gpu_id) #单卡
# torch.cuda.set_device('cuda:'+str(gpu_ids)) #可指定多卡
torch.cuda.set_device(LOCAL_RANK)
device = torch.device('cuda', LOCAL_RANK)
# 初始化多进程
dist.init_process_group(backend="nccl" if dist.is_nccl_available() else "gloo")2.4 main函数——是否进化训练/遗传算法调参
################################################ 4. Train #################################################
# 不设置evolve直接调用train训练
if not opt.evolve:
train(opt.hyp, opt, device, callbacks)
# 分布式训练 WORLD_SIZE=主机的数量
# 如果是使用多卡训练, 那么销毁进程组
if WORLD_SIZE > 1 and RANK == 0:
LOGGER.info('Destroying process group... ')
# 使用多卡训练, 那么销毁进程组
dist.destroy_process_group()
# Evolve hyperparameters (optional)
# 遗传净化算法/一边训练一遍进化
# 了解遗传算法可以查看我的博客:
else:
# Hyperparameter evolution metadata (mutation scale 0-1, lower_limit, upper_limit)
# 超参数列表(突变范围 - 最小值 - 最大值)
meta = {'lr0': (1, 1e-5, 1e-1), # initial learning rate (SGD=1E-2, Adam=1E-3)
'lrf': (1, 0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)
'momentum': (0.3, 0.6, 0.98), # SGD momentum/Adam beta1
'weight_decay': (1, 0.0, 0.001), # optimizer weight decay
'warmup_epochs': (1, 0.0, 5.0), # warmup epochs (fractions ok)
'warmup_momentum': (1, 0.0, 0.95), # warmup initial momentum
'warmup_bias_lr': (1, 0.0, 0.2), # warmup initial bias lr
'box': (1, 0.02, 0.2), # box loss gain
'cls': (1, 0.2, 4.0), # cls loss gain
'cls_pw': (1, 0.5, 2.0), # cls BCELoss positive_weight
'obj': (1, 0.2, 4.0), # obj loss gain (scale with pixels)
'obj_pw': (1, 0.5, 2.0), # obj BCELoss positive_weight
'iou_t': (0, 0.1, 0.7), # IoU training threshold
'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold
'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)
'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)
'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
'hsv_s': (1, 0.0, 0.9), # image HSV-Saturation augmentation (fraction)
'hsv_v': (1, 0.0, 0.9), # image HSV-Value augmentation (fraction)
'degrees': (1, 0.0, 45.0), # image rotation (+/- deg)
'translate': (1, 0.0, 0.9), # image translation (+/- fraction)
'scale': (1, 0.0, 0.9), # image scale (+/- gain)
'shear': (1, 0.0, 10.0), # image shear (+/- deg)
'perspective': (0, 0.0, 0.001), # image perspective (+/- fraction), range 0-0.001
'flipud': (1, 0.0, 1.0), # image flip up-down (probability)
'fliplr': (0, 0.0, 1.0), # image flip left-right (probability)
'mosaic': (1, 0.0, 1.0), # image mixup (probability)
'mixup': (1, 0.0, 1.0), # image mixup (probability)
'copy_paste': (1, 0.0, 1.0)} # segment copy-paste (probability)
with open(opt.hyp, errors='ignore') as f:
# 加载yaml超参数
hyp = yaml.safe_load(f) # load hyps dict
if 'anchors' not in hyp: # anchors commented in hyp.yaml
hyp['anchors'] = 3
opt.noval, opt.nosave, save_dir = True, True, Path(opt.save_dir) # only val/save final epoch
# ei = [isinstance(x, (int, float)) for x in hyp.values()] # evolvable indices
# 保存进化的超参数列表
evolve_yaml, evolve_csv = save_dir / 'hyp_evolve.yaml', save_dir / 'evolve.csv'
if opt.bucket:
os.system(f'gsutil cp gs://{opt.bucket}/evolve.csv {evolve_csv}') # download evolve.csv if exists
"""
遗传算法调参:遵循适者生存、优胜劣汰的法则,即寻优过程中保留有用的,去除无用的。
遗传算法需要提前设置4个参数: 群体大小/进化代数/交叉概率/变异概率
"""
# 默认选择进化300代
for _ in range(opt.evolve): # generations to evolve
if evolve_csv.exists(): # if evolve.csv exists: select best hyps and mutate
# Select parent(s)
# 进化方式--single / --weight
parent = 'single' # parent selection method: 'single' or 'weighted'
# 加载evolve.txt文件
x = np.loadtxt(evolve_csv, ndmin=2, delimiter=',', skiprows=1)
# 选取进化结果代数
n = min(5, len(x)) # number of previous results to consider
x = x[np.argsort(-fitness(x))][:n] # top n mutations
# 根据resluts计算hyp权重
w = fitness(x) - fitness(x).min() + 1E-6 # weights (sum > 0)
# 根据不同进化方式获得base hyp
if parent == 'single' or len(x) == 1:
# x = x[random.randint(0, n - 1)] # random selection
x = x[random.choices(range(n), weights=w)[0]] # weighted selection
elif parent == 'weighted':
x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination
# Mutate
# # 获取突变初始值
mp, s = 0.8, 0.2 # mutation probability, sigma
npr = np.random
npr.seed(int(time.time()))
g = np.array([meta[k][0] for k in hyp.keys()]) # gains 0-1
ng = len(meta)
v = np.ones(ng)
# 设置突变
while all(v == 1): # mutate until a change occurs (prevent duplicates)
# 将突变添加到base hyp上
# [i+7]是因为x中前7个数字为results的指标(P,R,mAP,F1,test_loss=(box,obj,cls)),之后才是超参数hyp
v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)
for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)
hyp[k] = float(x[i + 7] * v[i]) # mutate
# Constrain to limits
# 限制超参再规定范围
for k, v in meta.items():
hyp[k] = max(hyp[k], v[1]) # lower limit
hyp[k] = min(hyp[k], v[2]) # upper limit
hyp[k] = round(hyp[k], 5) # significant digits
# Train mutation
# 训练 使用突变后的参超 测试其效果
results = train(hyp.copy(), opt, device, callbacks)
callbacks = Callbacks()
# Write mutation results
# Write mutation results
# 将结果写入results 并将对应的hyp写到evolve.txt evolve.txt中每一行为一次进化的结果
# 每行前七个数字 (P, R, mAP, F1, test_losses(GIOU, obj, cls)) 之后为hyp
# 保存hyp到yaml文件
print_mutation(results, hyp.copy(), save_dir, opt.bucket)
# Plot results
# 将结果可视化 / 输出保存信息
plot_evolve(evolve_csv)
LOGGER.info(f'Hyperparameter evolution finished {opt.evolve} generations\n'
f"Results saved to {colorstr('bold', save_dir)}\n"
f'Usage example: $ python train.py --hyp {evolve_yaml}')
3. train函数
3.1 train函数——基本配置信息
################################################ 1. 传入参数/基本配置 #############################################
# opt传入的参数
save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze = \
Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze
# Directories
w = save_dir / 'weights' # weights dir
# 新建文件夹 weights train evolve
(w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # make dir
# 保存训练结果的目录 如runs/train/exp*/weights/last.pt
last, best = w / 'last.pt', w / 'best.pt'
# Hyperparameters # isinstance()是否是已知类型
if isinstance(hyp, str):
with open(hyp, errors='ignore') as f:
# 加载yaml文件
hyp = yaml.safe_load(f) # load hyps dict
# 打印超参数 彩色字体
LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
# Save run settings
# 如果不使用进化训练
if not evolve:
# safe_dump() python值转化为yaml序列化
with open(save_dir / 'hyp.yaml', 'w') as f:
yaml.safe_dump(hyp, f, sort_keys=False)
with open(save_dir / 'opt.yaml', 'w') as f:
# vars(opt) 的作用是把数据类型是Namespace的数据转换为字典的形式。
yaml.safe_dump(vars(opt), f, sort_keys=False)
# Loggers
data_dict = None
if RANK in [-1, 0]:
loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
if loggers.wandb:
data_dict = loggers.wandb.data_dict
if resume:
weights, epochs, hyp, batch_size = opt.weights, opt.epochs, opt.hyp, opt.batch_size
# Register actions
for k in methods(loggers):
callbacks.register_action(k, callback=getattr(loggers, k))
# Config 画图
plots = not evolve # create plots
# GPU / CPU
cuda = device.type != 'cpu'
# 随机种子
init_seeds(1 + RANK)
# 存在子进程-分布式训练
with torch_distributed_zero_first(LOCAL_RANK):
data_dict = data_dict or check_dataset(data) # check if None
# 训练集和验证集的位路径
train_path, val_path = data_dict['train'], data_dict['val']
# 设置类别 是否单类
nc = 1 if single_cls else int(data_dict['nc']) # number of classes
# 类别对应的名称
names = ['item'] if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
# 判断类别长度和文件是否对应
assert len(names) == nc, f'{len(names)} names found for nc={nc} dataset in {data}' # check
# 当前数据集是否是coco数据集(80个类别)
is_coco = isinstance(val_path, str) and val_path.endswith('coco/val2017.txt') # COCO dataset
3.2 train函数——模型加载/断点训练
################################################### 2. Model ###########################################
# 检查文件后缀是否是.pt
check_suffix(weights, '.pt') # check weights
# 加载预训练权重 yolov5提供了5个不同的预训练权重,大家可以根据自己的模型选择预训练权重
pretrained = weights.endswith('.pt')
if pretrained:
# # torch_distributed_zero_first(RANK): 用于同步不同进程对数据读取的上下文管理器
with torch_distributed_zero_first(LOCAL_RANK):
# 如果本地不存在就从网站上下载
weights = attempt_download(weights) # download if not found locally
# 加载模型以及参数
ckpt = torch.load(weights, map_location='cpu') # load checkpoint to CPU to avoid CUDA memory leak
"""
两种加载模型的方式: opt.cfg / ckpt['model'].yaml
使用resume-断点训练: 选择ckpt['model']yaml创建模型, 且不加载anchor
使用断点训练时,保存的模型会保存anchor,所以不需要加载
"""
model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
# 筛选字典中的键值对 把exclude删除
csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
model.load_state_dict(csd, strict=False) # load
LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
else:
# 不适用预训练权重
model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
3.3 train函数——冻结训练/冻结层设置
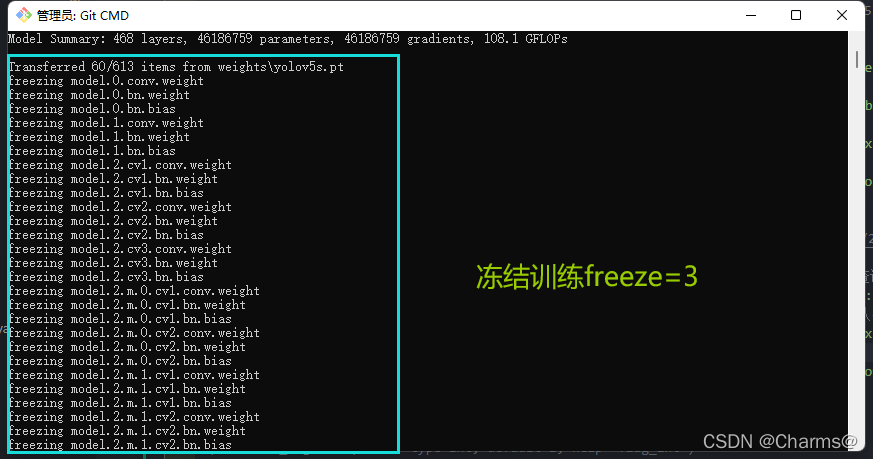
################################################ 3. Freeze/冻结训练 #########################################
# 冻结训练的网络层
freeze = [f'model.{x}.' for x in (freeze if len(freeze) > 1 else range(freeze[0]))] # layers to freeze
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze):
LOGGER.info(f'freezing {k}')
# 冻结训练的层梯度不更新
v.requires_grad = False
3.4 train函数——图片大小/batchsize设置
# Image size
gs = max(int(model.stride.max()), 32) # grid size (max stride)
# 检查图片的大小
imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple
# Batch size
if RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch size
batch_size = check_train_batch_size(model, imgsz)
loggers.on_params_update({"batch_size": batch_size})
3.5 train函数——优化器选择 / 分组优化设置
############################################ 4. Optimizer/优化器 ###########################################
"""
nbs = 64
batchsize = 16
accumulate = 64 / 16 = 4
模型梯度累计accumulate次之后就更新一次模型 相当于使用更大batch_size
"""
nbs = 64 # nominal batch size
accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
# 权重衰减参数
hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
# 打印日志
LOGGER.info(f"Scaled weight_decay = {hyp['weight_decay']}")
# 将模型参数分为三组(weights、biases、bn)来进行分组优化
g0, g1, g2 = [], [], [] # optimizer parameter groups
for v in model.modules():
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias
g2.append(v.bias)
if isinstance(v, nn.BatchNorm2d): # weight (no decay)
g0.append(v.weight)
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
g1.append(v.weight)
# 选择优化器 / 提供了三个优化器——g0
if opt.optimizer == 'Adam':
optimizer = Adam(g0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
elif opt.optimizer == 'AdamW':
optimizer = AdamW(g0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
else:
optimizer = SGD(g0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
# 设置优化的方式——g1 / g2
optimizer.add_param_group({'params': g1, 'weight_decay': hyp['weight_decay']}) # add g1 with weight_decay
optimizer.add_param_group({'params': g2}) # add g2 (biases)
# 打印log日志 优化信息
LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__} with parameter groups "
f"{len(g0)} weight (no decay), {len(g1)} weight, {len(g2)} bias")
# 删除变量
del g0, g1, g2
3.6 train函数——学习率/ema/归一化/单机多卡
############################################ 5. Scheduler ##############################################
# 是否余弦学习率调整方式
if opt.cos_lr:
lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
else:
lf = lambda x: (1 - x / epochs) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # plot_lr_scheduler(optimizer, scheduler, epochs)
# EMA
# 使用EMA(指数移动平均)对模型的参数做平均, 一种给予近期数据更高权重的平均方法, 以求提高测试指标并增加模型鲁棒。
ema = ModelEMA(model) if RANK in [-1, 0] else None
# Resume
start_epoch, best_fitness = 0, 0.0
if pretrained:
# Optimizer
if ckpt['optimizer'] is not None:
optimizer.load_state_dict(ckpt['optimizer'])
best_fitness = ckpt['best_fitness']
# EMA
if ema and ckpt.get('ema'):
ema.ema.load_state_dict(ckpt['ema'].float().state_dict())
ema.updates = ckpt['updates']
# Epochs
start_epoch = ckpt['epoch'] + 1
if resume:
assert start_epoch > 0, f'{weights} training to {epochs} epochs is finished, nothing to resume.'
if epochs < start_epoch:
LOGGER.info(f"{weights} has been trained for {ckpt['epoch']} epochs. Fine-tuning for {epochs} more epochs.")
epochs += ckpt['epoch'] # finetune additional epochs
del ckpt, csd
# DP mode
# DP: 单机多卡模式
if cuda and RANK == -1 and torch.cuda.device_count() > 1:
LOGGER.warning('WARNING: DP not recommended, use torch.distributed.run for best DDP Multi-GPU results.\n'
'See Multi-GPU Tutorial at https://github.com/ultralytics/yolov5/issues/475 to get started.')
model = torch.nn.DataParallel(model)
# SyncBatchNorm 多卡归一化
if opt.sync_bn and cuda and RANK != -1:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
# 打印信息
LOGGER.info('Using SyncBatchNorm()')3.7 train函数——数据加载 / anchor调整
# ############################################## 6. Trainloader / 数据加载 ######################################
# 训练集数据加载
train_loader, dataset = create_dataloader(train_path, imgsz, batch_size // WORLD_SIZE, gs, single_cls,
hyp=hyp, augment=True, cache=None if opt.cache == 'val' else opt.cache,
rect=opt.rect, rank=LOCAL_RANK, workers=workers,
image_weights=opt.image_weights, quad=opt.quad,
prefix=colorstr('train: '), shuffle=True)
# 标签编号最大值
mlc = int(np.concatenate(dataset.labels, 0)[:, 0].max()) # max label class
# 类别总数
nb = len(train_loader) # number of batches
# 判断编号是否正确
assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
# Process 0
# 验证集数据集加载
if RANK in [-1, 0]:
val_loader = create_dataloader(val_path, imgsz, batch_size // WORLD_SIZE * 2, gs, single_cls,
hyp=hyp, cache=None if noval else opt.cache,
rect=True, rank=-1, workers=workers * 2, pad=0.5,
prefix=colorstr('val: '))[0]
# 没有使用断点训练
if not resume:
labels = np.concatenate(dataset.labels, 0)
# c = torch.tensor(labels[:, 0]) # classes
# cf = torch.bincount(c.long(), minlength=nc) + 1. # frequency
# model._initialize_biases(cf.to(device))
if plots:
# 画出标签信息
plot_labels(labels, names, save_dir)
# Anchors
# 自适应anchor / anchor可以理解为程序预测的box
# 根据k-mean算法聚类生成新的锚框
if not opt.noautoanchor:
# 参数dataset代表的是训练集,hyp['anchor_t']是从配置文件hpy.scratch.yaml读取的超参数 anchor_t:4.0
# 当配置文件中的anchor计算bpr(best possible recall)小于0.98时才会重新计算anchor。
# best possible recall最大值1,如果bpr小于0.98,程序会根据数据集的label自动学习anchor的尺寸
check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)
# 半进度
model.half().float() # pre-reduce anchor precision
callbacks.run('on_pretrain_routine_end')
3.8 train函数——训练配置/多尺度训练/热身训练
# #################################################### 7. 训练 ###############################################
# DDP mode
# DDP:多机多卡
if cuda and RANK != -1:
model = DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
# Model attributes
nl = de_parallel(model).model[-1].nl # number of detection layers (to scale hyps)
hyp['box'] *= 3 / nl # scale to layers
hyp['cls'] *= nc / 80 * 3 / nl # scale to classes and layers
hyp['obj'] *= (imgsz / 640) ** 2 * 3 / nl # scale to image size and layers
# 标签平滑
hyp['label_smoothing'] = opt.label_smoothing
model.nc = nc # attach number of classes to model
model.hyp = hyp # attach hyperparameters to model
# 从训练样本标签得到类别权重(和类别中的目标数即类别频率成反比)
model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights
model.names = names
# Start training
t0 = time.time()
# # 获取热身迭代的次数iterations: 3
nw = max(round(hyp['warmup_epochs'] * nb), 100) # number of warmup iterations, max(3 epochs, 100 iterations)
# nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of training
last_opt_step = -1
# # 初始化maps(每个类别的map)和results
maps = np.zeros(nc) # mAP per class
results = (0, 0, 0, 0, 0, 0, 0) # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)
# 设置学习率衰减所进行到的轮次,即使打断训练,使用resume接着训练也能正常衔接之前的训练进行学习率衰减
scheduler.last_epoch = start_epoch - 1 # do not move
# 设置amp混合精度训练
scaler = amp.GradScaler(enabled=cuda)
# 早停止,不更新结束训练
stopper = EarlyStopping(patience=opt.patience)
# 初始化损失函数
compute_loss = ComputeLoss(model) # init loss class
# 打印信息
LOGGER.info(f'Image sizes {imgsz} train, {imgsz} val\n'
f'Using {train_loader.num_workers * WORLD_SIZE} dataloader workers\n'
f"Logging results to {colorstr('bold', save_dir)}\n"
f'Starting training for {epochs} epochs...')
# 开始走起训练
for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
model.train()
# Update image weights (optional, single-GPU only)
# opt.image_weights
if opt.image_weights:
"""
如果设置进行图片采样策略,
则根据前面初始化的图片采样权重model.class_weights以及maps配合每张图片包含的类别数
通过random.choices生成图片索引indices从而进行采样
"""
cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weights
iw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weights
dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx
# Update mosaic border (optional)
# b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
# dataset.mosaic_border = [b - imgsz, -b] # height, width borders
mloss = torch.zeros(3, device=device) # mean losses
if RANK != -1:
train_loader.sampler.set_epoch(epoch)
pbar = enumerate(train_loader)
LOGGER.info(('\n' + '%10s' * 7) % ('Epoch', 'gpu_mem', 'box', 'obj', 'cls', 'labels', 'img_size'))
if RANK in [-1, 0]:
# 进度条显示
pbar = tqdm(pbar, total=nb, bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
# 梯度清零
optimizer.zero_grad()
for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
ni = i + nb * epoch # number integrated batches (since train start)
imgs = imgs.to(device, non_blocking=True).float() / 255 # uint8 to float32, 0-255 to 0.0-1.0
"""
热身训练(前nw次迭代)
在前nw次迭代中, 根据以下方式选取accumulate和学习率
"""
# Warmup
if ni <= nw:
xi = [0, nw] # x interp
# compute_loss.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
for j, x in enumerate(optimizer.param_groups):
"""
bias的学习率从0.1下降到基准学习率lr*lf(epoch),
其他的参数学习率从0增加到lr*lf(epoch).
lf为上面设置的余弦退火的衰减函数
动量momentum也从0.9慢慢变到hyp['momentum'](default=0.937)
"""
# bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 2 else 0.0, x['initial_lr'] * lf(epoch)])
if 'momentum' in x:
x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
# Multi-scale
if opt.multi_scale:
"""
Multi-scale 设置多尺度训练,从imgsz * 0.5, imgsz * 1.5 + gs随机选取尺寸
"""
sz = random.randrange(imgsz * 0.5, imgsz * 1.5 + gs) // gs * gs # size
sf = sz / max(imgs.shape[2:]) # scale factor
if sf != 1:
ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
imgs = nn.functional.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
# Forward / 前向传播
with amp.autocast(enabled=cuda):
pred = model(imgs) # forward
# # 计算损失,包括分类损失,objectness损失,框的回归损失
# loss为总损失值,loss_items为一个元组,包含分类损失,objectness损失,框的回归损失和总损失
loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size
if RANK != -1:
# 平均不同gpu之间的梯度
loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
if opt.quad:
loss *= 4.
# Backward
scaler.scale(loss).backward()
# Optimize # 模型反向传播accumulate次之后再根据累积的梯度更新一次参数
if ni - last_opt_step >= accumulate:
scaler.step(optimizer) # optimizer.step
scaler.update()
optimizer.zero_grad()
if ema:
ema.update(model)
last_opt_step = ni
# Log
if RANK in [-1, 0]:
mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G' # (GB)
pbar.set_description(('%10s' * 2 + '%10.4g' * 5) % (
f'{epoch}/{epochs - 1}', mem, *mloss, targets.shape[0], imgs.shape[-1]))
callbacks.run('on_train_batch_end', ni, model, imgs, targets, paths, plots, opt.sync_bn)
if callbacks.stop_training:
return
# end batch ------------------------------------------------------------------------------------------------
# Scheduler 进行学习率衰减
lr = [x['lr'] for x in optimizer.param_groups] # for loggers
scheduler.step()
if RANK in [-1, 0]:
# mAP
callbacks.run('on_train_epoch_end', epoch=epoch)
# 将model中的属性赋值给ema
ema.update_attr(model, include=['yaml', 'nc', 'hyp', 'names', 'stride', 'class_weights'])
# 判断当前的epoch是否是最后一轮
final_epoch = (epoch + 1 == epochs) or stopper.possible_stop
# notest: 是否只测试最后一轮 True: 只测试最后一轮 False: 每轮训练完都测试mAP
if not noval or final_epoch: # Calculate mAP
"""
测试使用的是ema(指数移动平均 对模型的参数做平均)的模型
results: [1] Precision 所有类别的平均precision(最大f1时)
[1] Recall 所有类别的平均recall
[1] map@0.5 所有类别的平均mAP@0.5
[1] map@0.5:0.95 所有类别的平均mAP@0.5:0.95
[1] box_loss 验证集回归损失, obj_loss 验证集置信度损失, cls_loss 验证集分类损失
maps: [80] 所有类别的mAP@0.5:0.95
"""
results, maps, _ = val.run(data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
model=ema.ema,
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
plots=False,
callbacks=callbacks,
compute_loss=compute_loss)
# Update best mAP
# Update best mAP 这里的best mAP其实是[P, R, mAP@.5, mAP@.5-.95]的一个加权值
# fi: [P, R, mAP@.5, mAP@.5-.95]的一个加权值 = 0.1*mAP@.5 + 0.9*mAP@.5-.95
fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
if fi > best_fitness:
best_fitness = fi
log_vals = list(mloss) + list(results) + lr
callbacks.run('on_fit_epoch_end', log_vals, epoch, best_fitness, fi)
# Save model
"""
保存带checkpoint的模型用于inference或resuming training
保存模型, 还保存了epoch, results, optimizer等信息
optimizer将不会在最后一轮完成后保存
model保存的是EMA的模型
"""
if (not nosave) or (final_epoch and not evolve): # if save
ckpt = {'epoch': epoch,
'best_fitness': best_fitness,
'model': deepcopy(de_parallel(model)).half(),
'ema': deepcopy(ema.ema).half(),
'updates': ema.updates,
'optimizer': optimizer.state_dict(),
'wandb_id': loggers.wandb.wandb_run.id if loggers.wandb else None,
'date': datetime.now().isoformat()}
# Save last, best and delete
torch.save(ckpt, last)
if best_fitness == fi:
torch.save(ckpt, best)
if (epoch > 0) and (opt.save_period > 0) and (epoch % opt.save_period == 0):
torch.save(ckpt, w / f'epoch{epoch}.pt')
del ckpt
callbacks.run('on_model_save', last, epoch, final_epoch, best_fitness, fi)
# Stop Single-GPU
if RANK == -1 and stopper(epoch=epoch, fitness=fi):
break
# Stop DDP TODO: known issues shttps://github.com/ultralytics/yolov5/pull/4576
# stop = stopper(epoch=epoch, fitness=fi)
# if RANK == 0:
# dist.broadcast_object_list([stop], 0) # broadcast 'stop' to all ranks
# Stop DPP
# with torch_distributed_zero_first(RANK):
# if stop:
# break # must break all DDP ranks
3.9 train函数——训练结束/打印信息/保存结果
############################################### 8. 打印训练信息 ##########################################
if RANK in [-1, 0]:
LOGGER.info(f'\n{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.')
for f in last, best:
if f.exists():
# 模型训练完后, strip_optimizer函数将optimizer从ckpt中删除
# 并对模型进行model.half() 将Float32->Float16 这样可以减少模型大小, 提高inference速度
strip_optimizer(f) # strip optimizers
if f is best:
LOGGER.info(f'\nValidating {f}...')
results, _, _ = val.run(data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
model=attempt_load(f, device).half(),
iou_thres=0.65 if is_coco else 0.60, # best pycocotools results at 0.65
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
save_json=is_coco,
verbose=True,
plots=True,
callbacks=callbacks,
compute_loss=compute_loss) # val best model with plots
if is_coco:
callbacks.run('on_fit_epoch_end', list(mloss) + list(results) + lr, epoch, best_fitness, fi)
# 回调函数
callbacks.run('on_train_end', last, best, plots, epoch, results)
LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}")
# 释放显存
torch.cuda.empty_cache()
return results4. run函数
def run(**kwargs):
# 执行这个脚本/ 调用train函数 / 开启训练
# Usage: import train; train.run(data='coco128.yaml', imgsz=320, weights='yolov5m.pt')
opt = parse_opt(True)
for k, v in kwargs.items():
# setattr() 赋值属性,属性不存在则创建一个赋值
setattr(opt, k, v)
main(opt)
return opt
5.全部代码注释
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
"""
Train a YOLOv5 model on a custom dataset.
Models and datasets download automatically from the latest YOLOv5 release.
Models: https://github.com/ultralytics/yolov5/tree/master/models
Datasets: https://github.com/ultralytics/yolov5/tree/master/data
Tutorial: https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
Usage:
$ python path/to/train.py --data coco128.yaml --weights yolov5s.pt --img 640 # from pretrained (RECOMMENDED)
$ python path/to/train.py --data coco128.yaml --weights '' --cfg yolov5s.yaml --img 640 # from scratch
"""
import argparse
import math
import os
import random
import sys
import time
from copy import deepcopy
from datetime import datetime
from pathlib import Path
import numpy as np
import torch
import torch.distributed as dist
import torch.nn as nn
import yaml
from torch.cuda import amp
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.optim import SGD, Adam, AdamW, lr_scheduler
from tqdm import tqdm
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
import val # for end-of-epoch mAP
from models.experimental import attempt_load
from models.yolo import Model
from utils.autoanchor import check_anchors
from utils.autobatch import check_train_batch_size
from utils.callbacks import Callbacks
from utils.datasets import create_dataloader
from utils.downloads import attempt_download
from utils.general import (LOGGER, check_dataset, check_file, check_git_status, check_img_size, check_requirements,
check_suffix, check_yaml, colorstr, get_latest_run, increment_path, init_seeds,
intersect_dicts, labels_to_class_weights, labels_to_image_weights, methods, one_cycle,
print_args, print_mutation, strip_optimizer)
from utils.loggers import Loggers
from utils.loggers.wandb.wandb_utils import check_wandb_resume
from utils.loss import ComputeLoss
from utils.metrics import fitness
from utils.plots import plot_evolve, plot_labels
from utils.torch_utils import EarlyStopping, ModelEMA, de_parallel, select_device, torch_distributed_zero_first
LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
RANK = int(os.getenv('RANK', -1))
WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
def train(hyp, # path/to/hyp.yaml or hyp dictionary
opt,
device,
callbacks
):
################################################ 1. 传入参数/基本配置 #############################################
# opt传入的参数
save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze = \
Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze
# Directories
w = save_dir / 'weights' # weights dir
# 新建文件夹 weights train evolve
(w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # make dir
# 保存训练结果的目录 如runs/train/exp*/weights/last.pt
last, best = w / 'last.pt', w / 'best.pt'
# Hyperparameters # isinstance()是否是已知类型
if isinstance(hyp, str):
with open(hyp, errors='ignore') as f:
# 加载yaml文件
hyp = yaml.safe_load(f) # load hyps dict
# 打印超参数 彩色字体
LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
# Save run settings
# 如果不使用进化训练
if not evolve:
# safe_dump() python值转化为yaml序列化
with open(save_dir / 'hyp.yaml', 'w') as f:
yaml.safe_dump(hyp, f, sort_keys=False)
with open(save_dir / 'opt.yaml', 'w') as f:
# vars(opt) 的作用是把数据类型是Namespace的数据转换为字典的形式。
yaml.safe_dump(vars(opt), f, sort_keys=False)
# Loggers
data_dict = None
if RANK in [-1, 0]:
loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
if loggers.wandb:
data_dict = loggers.wandb.data_dict
if resume:
weights, epochs, hyp, batch_size = opt.weights, opt.epochs, opt.hyp, opt.batch_size
# Register actions
for k in methods(loggers):
callbacks.register_action(k, callback=getattr(loggers, k))
# Config 画图
plots = not evolve # create plots
# GPU / CPU
cuda = device.type != 'cpu'
# 随机种子
init_seeds(1 + RANK)
# 存在子进程-分布式训练
with torch_distributed_zero_first(LOCAL_RANK):
data_dict = data_dict or check_dataset(data) # check if None
# 训练集和验证集的位路径
train_path, val_path = data_dict['train'], data_dict['val']
# 设置类别 是否单类
nc = 1 if single_cls else int(data_dict['nc']) # number of classes
# 类别对应的名称
names = ['item'] if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
# 判断类别长度和文件是否对应
assert len(names) == nc, f'{len(names)} names found for nc={nc} dataset in {data}' # check
# 当前数据集是否是coco数据集(80个类别)
is_coco = isinstance(val_path, str) and val_path.endswith('coco/val2017.txt') # COCO dataset
################################################### 2. Model ###########################################
# 检查文件后缀是否是.pt
check_suffix(weights, '.pt') # check weights
# 加载预训练权重 yolov5提供了5个不同的预训练权重,大家可以根据自己的模型选择预训练权重
pretrained = weights.endswith('.pt')
if pretrained:
# # torch_distributed_zero_first(RANK): 用于同步不同进程对数据读取的上下文管理器
with torch_distributed_zero_first(LOCAL_RANK):
# 如果本地不存在就从网站上下载
weights = attempt_download(weights) # download if not found locally
# 加载模型以及参数
ckpt = torch.load(weights, map_location='cpu') # load checkpoint to CPU to avoid CUDA memory leak
"""
两种加载模型的方式: opt.cfg / ckpt['model'].yaml
使用resume-断点训练: 选择ckpt['model']yaml创建模型, 且不加载anchor
使用断点训练时,保存的模型会保存anchor,所以不需要加载
"""
model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
# 筛选字典中的键值对 把exclude删除
csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
model.load_state_dict(csd, strict=False) # load
LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
else:
# 不适用预训练权重
model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
################################################ 3. Freeze/冻结训练 #########################################
# 冻结训练的网络层
freeze = [f'model.{x}.' for x in (freeze if len(freeze) > 1 else range(freeze[0]))] # layers to freeze
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze):
LOGGER.info(f'freezing {k}')
# 冻结训练的层梯度不更新
v.requires_grad = False
# Image size
gs = max(int(model.stride.max()), 32) # grid size (max stride)
# 检查图片的大小
imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple
# Batch size
if RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch size
batch_size = check_train_batch_size(model, imgsz)
loggers.on_params_update({"batch_size": batch_size})
############################################ 4. Optimizer/优化器 ###########################################
"""
nbs = 64
batchsize = 16
accumulate = 64 / 16 = 4
模型梯度累计accumulate次之后就更新一次模型 相当于使用更大batch_size
"""
nbs = 64 # nominal batch size
accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
# 权重衰减参数
hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
# 打印日志
LOGGER.info(f"Scaled weight_decay = {hyp['weight_decay']}")
# 将模型参数分为三组(weights、biases、bn)来进行分组优化
g0, g1, g2 = [], [], [] # optimizer parameter groups
for v in model.modules():
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias
g2.append(v.bias)
if isinstance(v, nn.BatchNorm2d): # weight (no decay)
g0.append(v.weight)
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
g1.append(v.weight)
# 选择优化器 / 提供了三个优化器——g0
if opt.optimizer == 'Adam':
optimizer = Adam(g0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
elif opt.optimizer == 'AdamW':
optimizer = AdamW(g0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
else:
optimizer = SGD(g0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
# 设置优化的方式——g1 / g2
optimizer.add_param_group({'params': g1, 'weight_decay': hyp['weight_decay']}) # add g1 with weight_decay
optimizer.add_param_group({'params': g2}) # add g2 (biases)
# 打印log日志 优化信息
LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__} with parameter groups "
f"{len(g0)} weight (no decay), {len(g1)} weight, {len(g2)} bias")
# 删除变量
del g0, g1, g2
############################################ 5. Scheduler ##############################################
# 是否余弦学习率调整方式
if opt.cos_lr:
lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
else:
lf = lambda x: (1 - x / epochs) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # plot_lr_scheduler(optimizer, scheduler, epochs)
# EMA
# 使用EMA(指数移动平均)对模型的参数做平均, 一种给予近期数据更高权重的平均方法, 以求提高测试指标并增加模型鲁棒。
ema = ModelEMA(model) if RANK in [-1, 0] else None
# Resume
start_epoch, best_fitness = 0, 0.0
if pretrained:
# Optimizer
if ckpt['optimizer'] is not None:
optimizer.load_state_dict(ckpt['optimizer'])
best_fitness = ckpt['best_fitness']
# EMA
if ema and ckpt.get('ema'):
ema.ema.load_state_dict(ckpt['ema'].float().state_dict())
ema.updates = ckpt['updates']
# Epochs
start_epoch = ckpt['epoch'] + 1
if resume:
assert start_epoch > 0, f'{weights} training to {epochs} epochs is finished, nothing to resume.'
if epochs < start_epoch:
LOGGER.info(f"{weights} has been trained for {ckpt['epoch']} epochs. Fine-tuning for {epochs} more epochs.")
epochs += ckpt['epoch'] # finetune additional epochs
del ckpt, csd
# DP mode
# DP: 单机多卡模式
if cuda and RANK == -1 and torch.cuda.device_count() > 1:
LOGGER.warning('WARNING: DP not recommended, use torch.distributed.run for best DDP Multi-GPU results.\n'
'See Multi-GPU Tutorial at https://github.com/ultralytics/yolov5/issues/475 to get started.')
model = torch.nn.DataParallel(model)
# SyncBatchNorm 多卡归一化
if opt.sync_bn and cuda and RANK != -1:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
# 打印信息
LOGGER.info('Using SyncBatchNorm()')
# ############################################## 6. Trainloader / 数据加载 ######################################
# 训练集数据加载
train_loader, dataset = create_dataloader(train_path, imgsz, batch_size // WORLD_SIZE, gs, single_cls,
hyp=hyp, augment=True, cache=None if opt.cache == 'val' else opt.cache,
rect=opt.rect, rank=LOCAL_RANK, workers=workers,
image_weights=opt.image_weights, quad=opt.quad,
prefix=colorstr('train: '), shuffle=True)
# 标签编号最大值
mlc = int(np.concatenate(dataset.labels, 0)[:, 0].max()) # max label class
# 类别总数
nb = len(train_loader) # number of batches
# 判断编号是否正确
assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
# Process 0
# 验证集数据集加载
if RANK in [-1, 0]:
val_loader = create_dataloader(val_path, imgsz, batch_size // WORLD_SIZE * 2, gs, single_cls,
hyp=hyp, cache=None if noval else opt.cache,
rect=True, rank=-1, workers=workers * 2, pad=0.5,
prefix=colorstr('val: '))[0]
# 没有使用断点训练
if not resume:
labels = np.concatenate(dataset.labels, 0)
# c = torch.tensor(labels[:, 0]) # classes
# cf = torch.bincount(c.long(), minlength=nc) + 1. # frequency
# model._initialize_biases(cf.to(device))
if plots:
# 画出标签信息
plot_labels(labels, names, save_dir)
# Anchors
# 自适应anchor / anchor可以理解为程序预测的box
# 根据k-mean算法聚类生成新的锚框
if not opt.noautoanchor:
# 参数dataset代表的是训练集,hyp['anchor_t']是从配置文件hpy.scratch.yaml读取的超参数 anchor_t:4.0
# 当配置文件中的anchor计算bpr(best possible recall)小于0.98时才会重新计算anchor。
# best possible recall最大值1,如果bpr小于0.98,程序会根据数据集的label自动学习anchor的尺寸
check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)
# 半进度
model.half().float() # pre-reduce anchor precision
callbacks.run('on_pretrain_routine_end')
# #################################################### 7. 训练 ###############################################
# DDP mode
# DDP:多机多卡
if cuda and RANK != -1:
model = DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
# Model attributes
nl = de_parallel(model).model[-1].nl # number of detection layers (to scale hyps)
hyp['box'] *= 3 / nl # scale to layers
hyp['cls'] *= nc / 80 * 3 / nl # scale to classes and layers
hyp['obj'] *= (imgsz / 640) ** 2 * 3 / nl # scale to image size and layers
# 标签平滑
hyp['label_smoothing'] = opt.label_smoothing
model.nc = nc # attach number of classes to model
model.hyp = hyp # attach hyperparameters to model
# 从训练样本标签得到类别权重(和类别中的目标数即类别频率成反比)
model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights
model.names = names
# Start training
t0 = time.time()
# # 获取热身迭代的次数iterations: 3
nw = max(round(hyp['warmup_epochs'] * nb), 100) # number of warmup iterations, max(3 epochs, 100 iterations)
# nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of training
last_opt_step = -1
# # 初始化maps(每个类别的map)和results
maps = np.zeros(nc) # mAP per class
results = (0, 0, 0, 0, 0, 0, 0) # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)
# 设置学习率衰减所进行到的轮次,即使打断训练,使用resume接着训练也能正常衔接之前的训练进行学习率衰减
scheduler.last_epoch = start_epoch - 1 # do not move
# 设置amp混合精度训练
scaler = amp.GradScaler(enabled=cuda)
# 早停止,不更新结束训练
stopper = EarlyStopping(patience=opt.patience)
# 初始化损失函数
compute_loss = ComputeLoss(model) # init loss class
# 打印信息
LOGGER.info(f'Image sizes {imgsz} train, {imgsz} val\n'
f'Using {train_loader.num_workers * WORLD_SIZE} dataloader workers\n'
f"Logging results to {colorstr('bold', save_dir)}\n"
f'Starting training for {epochs} epochs...')
# 开始走起训练
for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
model.train()
# Update image weights (optional, single-GPU only)
# opt.image_weights
if opt.image_weights:
"""
如果设置进行图片采样策略,
则根据前面初始化的图片采样权重model.class_weights以及maps配合每张图片包含的类别数
通过random.choices生成图片索引indices从而进行采样
"""
cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weights
iw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weights
dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx
# Update mosaic border (optional)
# b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
# dataset.mosaic_border = [b - imgsz, -b] # height, width borders
mloss = torch.zeros(3, device=device) # mean losses
if RANK != -1:
train_loader.sampler.set_epoch(epoch)
pbar = enumerate(train_loader)
LOGGER.info(('\n' + '%10s' * 7) % ('Epoch', 'gpu_mem', 'box', 'obj', 'cls', 'labels', 'img_size'))
if RANK in [-1, 0]:
# 进度条显示
pbar = tqdm(pbar, total=nb, bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
# 梯度清零
optimizer.zero_grad()
for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
ni = i + nb * epoch # number integrated batches (since train start)
imgs = imgs.to(device, non_blocking=True).float() / 255 # uint8 to float32, 0-255 to 0.0-1.0
"""
热身训练(前nw次迭代)
在前nw次迭代中, 根据以下方式选取accumulate和学习率
"""
# Warmup
if ni <= nw:
xi = [0, nw] # x interp
# compute_loss.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
for j, x in enumerate(optimizer.param_groups):
"""
bias的学习率从0.1下降到基准学习率lr*lf(epoch),
其他的参数学习率从0增加到lr*lf(epoch).
lf为上面设置的余弦退火的衰减函数
动量momentum也从0.9慢慢变到hyp['momentum'](default=0.937)
"""
# bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 2 else 0.0, x['initial_lr'] * lf(epoch)])
if 'momentum' in x:
x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
# Multi-scale
if opt.multi_scale:
"""
Multi-scale 设置多尺度训练,从imgsz * 0.5, imgsz * 1.5 + gs随机选取尺寸
"""
sz = random.randrange(imgsz * 0.5, imgsz * 1.5 + gs) // gs * gs # size
sf = sz / max(imgs.shape[2:]) # scale factor
if sf != 1:
ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
imgs = nn.functional.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
# Forward / 前向传播
with amp.autocast(enabled=cuda):
pred = model(imgs) # forward
# # 计算损失,包括分类损失,objectness损失,框的回归损失
# loss为总损失值,loss_items为一个元组,包含分类损失,objectness损失,框的回归损失和总损失
loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size
if RANK != -1:
# 平均不同gpu之间的梯度
loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
if opt.quad:
loss *= 4.
# Backward
scaler.scale(loss).backward()
# Optimize # 模型反向传播accumulate次之后再根据累积的梯度更新一次参数
if ni - last_opt_step >= accumulate:
scaler.step(optimizer) # optimizer.step
scaler.update()
optimizer.zero_grad()
if ema:
ema.update(model)
last_opt_step = ni
# Log
if RANK in [-1, 0]:
mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G' # (GB)
pbar.set_description(('%10s' * 2 + '%10.4g' * 5) % (
f'{epoch}/{epochs - 1}', mem, *mloss, targets.shape[0], imgs.shape[-1]))
callbacks.run('on_train_batch_end', ni, model, imgs, targets, paths, plots, opt.sync_bn)
if callbacks.stop_training:
return
# end batch ------------------------------------------------------------------------------------------------
# Scheduler 进行学习率衰减
lr = [x['lr'] for x in optimizer.param_groups] # for loggers
scheduler.step()
if RANK in [-1, 0]:
# mAP
callbacks.run('on_train_epoch_end', epoch=epoch)
# 将model中的属性赋值给ema
ema.update_attr(model, include=['yaml', 'nc', 'hyp', 'names', 'stride', 'class_weights'])
# 判断当前的epoch是否是最后一轮
final_epoch = (epoch + 1 == epochs) or stopper.possible_stop
# notest: 是否只测试最后一轮 True: 只测试最后一轮 False: 每轮训练完都测试mAP
if not noval or final_epoch: # Calculate mAP
"""
测试使用的是ema(指数移动平均 对模型的参数做平均)的模型
results: [1] Precision 所有类别的平均precision(最大f1时)
[1] Recall 所有类别的平均recall
[1] map@0.5 所有类别的平均mAP@0.5
[1] map@0.5:0.95 所有类别的平均mAP@0.5:0.95
[1] box_loss 验证集回归损失, obj_loss 验证集置信度损失, cls_loss 验证集分类损失
maps: [80] 所有类别的mAP@0.5:0.95
"""
results, maps, _ = val.run(data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
model=ema.ema,
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
plots=False,
callbacks=callbacks,
compute_loss=compute_loss)
# Update best mAP
# Update best mAP 这里的best mAP其实是[P, R, mAP@.5, mAP@.5-.95]的一个加权值
# fi: [P, R, mAP@.5, mAP@.5-.95]的一个加权值 = 0.1*mAP@.5 + 0.9*mAP@.5-.95
fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
if fi > best_fitness:
best_fitness = fi
log_vals = list(mloss) + list(results) + lr
callbacks.run('on_fit_epoch_end', log_vals, epoch, best_fitness, fi)
# Save model
"""
保存带checkpoint的模型用于inference或resuming training
保存模型, 还保存了epoch, results, optimizer等信息
optimizer将不会在最后一轮完成后保存
model保存的是EMA的模型
"""
if (not nosave) or (final_epoch and not evolve): # if save
ckpt = {'epoch': epoch,
'best_fitness': best_fitness,
'model': deepcopy(de_parallel(model)).half(),
'ema': deepcopy(ema.ema).half(),
'updates': ema.updates,
'optimizer': optimizer.state_dict(),
'wandb_id': loggers.wandb.wandb_run.id if loggers.wandb else None,
'date': datetime.now().isoformat()}
# Save last, best and delete
torch.save(ckpt, last)
if best_fitness == fi:
torch.save(ckpt, best)
if (epoch > 0) and (opt.save_period > 0) and (epoch % opt.save_period == 0):
torch.save(ckpt, w / f'epoch{epoch}.pt')
del ckpt
callbacks.run('on_model_save', last, epoch, final_epoch, best_fitness, fi)
# Stop Single-GPU
if RANK == -1 and stopper(epoch=epoch, fitness=fi):
break
# Stop DDP TODO: known issues shttps://github.com/ultralytics/yolov5/pull/4576
# stop = stopper(epoch=epoch, fitness=fi)
# if RANK == 0:
# dist.broadcast_object_list([stop], 0) # broadcast 'stop' to all ranks
# Stop DPP
# with torch_distributed_zero_first(RANK):
# if stop:
# break # must break all DDP ranks
# end epoch ----------------------------------------------------------------------------------------------------
# end training --------------------------------------------------------------------------------------------------
############################################### 8. 打印训练信息 ##########################################
if RANK in [-1, 0]:
LOGGER.info(f'\n{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.')
for f in last, best:
if f.exists():
# 模型训练完后, strip_optimizer函数将optimizer从ckpt中删除
# 并对模型进行model.half() 将Float32->Float16 这样可以减少模型大小, 提高inference速度
strip_optimizer(f) # strip optimizers
if f is best:
LOGGER.info(f'\nValidating {f}...')
results, _, _ = val.run(data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
model=attempt_load(f, device).half(),
iou_thres=0.65 if is_coco else 0.60, # best pycocotools results at 0.65
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
save_json=is_coco,
verbose=True,
plots=True,
callbacks=callbacks,
compute_loss=compute_loss) # val best model with plots
if is_coco:
callbacks.run('on_fit_epoch_end', list(mloss) + list(results) + lr, epoch, best_fitness, fi)
# 回调函数
callbacks.run('on_train_end', last, best, plots, epoch, results)
LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}")
# 释放显存
torch.cuda.empty_cache()
return results
def parse_opt(known=False):
parser = argparse.ArgumentParser()
# weights 权重的路径./weights/yolov5s.pt....
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
# cfg 配置文件(网络结构) anchor/backbone/numclasses/head,该文件需要自己生成
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
# data 数据集配置文件(路径) train/val/label/, 该文件需要自己生成
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
# hpy超参数设置文件(lr/sgd/mixup)
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
# epochs 训练轮次
parser.add_argument('--epochs', type=int, default=300)
# batchsize 训练批次
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
# imagesize 设置图片大小
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
# rect 是否采用矩形训练,默认为False
parser.add_argument('--rect', action='store_true', help='rectangular training')
# resume 是否接着上次的训练结果,继续训练
parser.add_argument('--resume', nargs='?', const=True, default=True, help='resume most recent training')
# nosave 保存最好的模型
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
# noval 最后进行测试
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
# noautoanchor 不自动调整anchor, 默认False
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
# evolve参数进化
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
# bucket谷歌优盘
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
# cache 是否提前缓存图片到内存,以加快训练速度,默认False
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
# mage-weights 加载的权重文件
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
# device 设备选择
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
# multi-scale 多测度训练
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
# single-cls 数据集是否多类/默认True
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
# optimizer 优化器选择
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
# sync-bn:是否使用跨卡同步BN,在DDP模式使用
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
# workers/dataloader的最大worker数量
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
# 保存路径
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
# 实验名称
parser.add_argument('--name', default='exp', help='save to project/name')
# 项目位置是否存在
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
# cos-lr 余弦学习率
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
# 标签平滑
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
# 早停止忍耐次数
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
# 冻结训练次数
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
# Weights & Biases arguments
# 在线可视化工具,类似于tensorboard工具,想了解这款工具可以查看https://zhuanlan.zhihu.com/p/266337608
parser.add_argument('--entity', default=None, help='W&B: Entity')
# upload_dataset: 是否上传dataset到wandb tabel(将数据集作为交互式 dsviz表 在浏览器中查看、查询、筛选和分析数据集) 默认False
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
# bbox_interval: 设置界框图像记录间隔 Set bounding-box image logging interval for W&B 默认-1 opt.epochs // 10
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
# 使用数据的版本
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
# 传入的基本配置中没有的参数也不会报错# parse_args()和parse_known_args()
# parse = argparse.ArgumentParser()
# parse.add_argument('--s', type=int, default=2, help='flag_int')
# parser.parse_args() / parse_args()
opt = parser.parse_known_args()[0] if known else parser.parse_args()
return opt
def main(opt, callbacks=Callbacks()):
############################################### 1. Checks ##################################################
if RANK in [-1, 0]:
# 输出所有训练参数 / 参数以彩色的方式表现
print_args(FILE.stem, opt)
# 检查代码版本是否更新
check_git_status()
# 检查安装是否都安装了 requirements.txt, 缺少安装包安装。
# 缺少安装包:建议使用 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
check_requirements(exclude=['thop'])
############################################### 2. Resume ##################################################
# 初始化可视化工具wandb,wandb使用教程看https://zhuanlan.zhihu.com/p/266337608
# 断点训练使用教程可以查看:https://blog.csdn.net/CharmsLUO/article/details/123410081
if opt.resume and not check_wandb_resume(opt) and not opt.evolve: # resume an interrupted run
# isinstance()是否是已经知道的类型
# 如果resume是True,则通过get_lastest_run()函数找到runs为文件夹中最近的权重文件last.pt
ckpt = opt.resume if isinstance(opt.resume, str) else get_latest_run() # specified or most recent path
# 判断是否是文件
assert os.path.isfile(ckpt), 'ERROR: --resume checkpoint does not exist'
# # 相关的opt参数也要替换成last.pt中的opt参数 safe_load()yaml文件加载数据
with open(Path(ckpt).parent.parent / 'opt.yaml', errors='ignore') as f:
# argparse.Namespace 可以理解为字典
opt = argparse.Namespace(**yaml.safe_load(f)) # replace
opt.cfg, opt.weights, opt.resume = '', ckpt, True # reinstate
# 打印断点训练信息
LOGGER.info(f'Resuming training from {ckpt}')
else:
# 不使用断点训练就在加载输入的参数
opt.data, opt.cfg, opt.hyp, opt.weights, opt.project = \
check_file(opt.data), check_yaml(opt.cfg), check_yaml(opt.hyp), str(opt.weights), str(opt.project) # checks
assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
# opt.evolve=False,opt.name='exp' opt.evolve=True,opt.name='evolve'
if opt.evolve:
if opt.project == str(ROOT / 'runs/train'): # if default project name, rename to runs/evolve
opt.project = str(ROOT / 'runs/evolve')
opt.exist_ok, opt.resume = opt.resume, False # pass resume to exist_ok and disable resume
# 保存相关信息
opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))
# ############################################## 3.DDP mode ###############################################
# 选择设备cpu/cuda
device = select_device(opt.device, batch_size=opt.batch_size)
# 多卡训练GPU
if LOCAL_RANK != -1:
msg = 'is not compatible with YOLOv5 Multi-GPU DDP training'
assert not opt.image_weights, f'--image-weights {msg}'
assert not opt.evolve, f'--evolve {msg}'
assert opt.batch_size != -1, f'AutoBatch with --batch-size -1 {msg}, please pass a valid --batch-size'
assert opt.batch_size % WORLD_SIZE == 0, f'--batch-size {opt.batch_size} must be multiple of WORLD_SIZE'
assert torch.cuda.device_count() > LOCAL_RANK, 'insufficient CUDA devices for DDP command'
# 根据编号选择设备
#使用torch.cuda.set_device()可以更方便地将模型和数据加载到对应GPU上, 直接定义模型之前加入一行代码即可
# torch.cuda.set_device(gpu_id) #单卡
# torch.cuda.set_device('cuda:'+str(gpu_ids)) #可指定多卡
torch.cuda.set_device(LOCAL_RANK)
device = torch.device('cuda', LOCAL_RANK)
# 初始化多进程
dist.init_process_group(backend="nccl" if dist.is_nccl_available() else "gloo")
################################################ 4. Train #################################################
# 不设置evolve直接调用train训练
if not opt.evolve:
train(opt.hyp, opt, device, callbacks)
# 分布式训练 WORLD_SIZE=主机的数量
# 如果是使用多卡训练, 那么销毁进程组
if WORLD_SIZE > 1 and RANK == 0:
LOGGER.info('Destroying process group... ')
# 使用多卡训练, 那么销毁进程组
dist.destroy_process_group()
# Evolve hyperparameters (optional)
# 遗传净化算法/一边训练一遍进化
# 了解遗传算法可以查看我的博客:
else:
# Hyperparameter evolution metadata (mutation scale 0-1, lower_limit, upper_limit)
# 超参数列表(突变范围 - 最小值 - 最大值)
meta = {'lr0': (1, 1e-5, 1e-1), # initial learning rate (SGD=1E-2, Adam=1E-3)
'lrf': (1, 0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)
'momentum': (0.3, 0.6, 0.98), # SGD momentum/Adam beta1
'weight_decay': (1, 0.0, 0.001), # optimizer weight decay
'warmup_epochs': (1, 0.0, 5.0), # warmup epochs (fractions ok)
'warmup_momentum': (1, 0.0, 0.95), # warmup initial momentum
'warmup_bias_lr': (1, 0.0, 0.2), # warmup initial bias lr
'box': (1, 0.02, 0.2), # box loss gain
'cls': (1, 0.2, 4.0), # cls loss gain
'cls_pw': (1, 0.5, 2.0), # cls BCELoss positive_weight
'obj': (1, 0.2, 4.0), # obj loss gain (scale with pixels)
'obj_pw': (1, 0.5, 2.0), # obj BCELoss positive_weight
'iou_t': (0, 0.1, 0.7), # IoU training threshold
'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold
'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)
'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)
'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
'hsv_s': (1, 0.0, 0.9), # image HSV-Saturation augmentation (fraction)
'hsv_v': (1, 0.0, 0.9), # image HSV-Value augmentation (fraction)
'degrees': (1, 0.0, 45.0), # image rotation (+/- deg)
'translate': (1, 0.0, 0.9), # image translation (+/- fraction)
'scale': (1, 0.0, 0.9), # image scale (+/- gain)
'shear': (1, 0.0, 10.0), # image shear (+/- deg)
'perspective': (0, 0.0, 0.001), # image perspective (+/- fraction), range 0-0.001
'flipud': (1, 0.0, 1.0), # image flip up-down (probability)
'fliplr': (0, 0.0, 1.0), # image flip left-right (probability)
'mosaic': (1, 0.0, 1.0), # image mixup (probability)
'mixup': (1, 0.0, 1.0), # image mixup (probability)
'copy_paste': (1, 0.0, 1.0)} # segment copy-paste (probability)
with open(opt.hyp, errors='ignore') as f:
# 加载yaml超参数
hyp = yaml.safe_load(f) # load hyps dict
if 'anchors' not in hyp: # anchors commented in hyp.yaml
hyp['anchors'] = 3
opt.noval, opt.nosave, save_dir = True, True, Path(opt.save_dir) # only val/save final epoch
# ei = [isinstance(x, (int, float)) for x in hyp.values()] # evolvable indices
# 保存进化的超参数列表
evolve_yaml, evolve_csv = save_dir / 'hyp_evolve.yaml', save_dir / 'evolve.csv'
if opt.bucket:
os.system(f'gsutil cp gs://{opt.bucket}/evolve.csv {evolve_csv}') # download evolve.csv if exists
"""
遗传算法调参:遵循适者生存、优胜劣汰的法则,即寻优过程中保留有用的,去除无用的。
遗传算法需要提前设置4个参数: 群体大小/进化代数/交叉概率/变异概率
"""
# 默认选择进化300代
for _ in range(opt.evolve): # generations to evolve
if evolve_csv.exists(): # if evolve.csv exists: select best hyps and mutate
# Select parent(s)
# 进化方式--single / --weight
parent = 'single' # parent selection method: 'single' or 'weighted'
# 加载evolve.txt文件
x = np.loadtxt(evolve_csv, ndmin=2, delimiter=',', skiprows=1)
# 选取进化结果代数
n = min(5, len(x)) # number of previous results to consider
x = x[np.argsort(-fitness(x))][:n] # top n mutations
# 根据resluts计算hyp权重
w = fitness(x) - fitness(x).min() + 1E-6 # weights (sum > 0)
# 根据不同进化方式获得base hyp
if parent == 'single' or len(x) == 1:
# x = x[random.randint(0, n - 1)] # random selection
x = x[random.choices(range(n), weights=w)[0]] # weighted selection
elif parent == 'weighted':
x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination
# Mutate
# # 获取突变初始值
mp, s = 0.8, 0.2 # mutation probability, sigma
npr = np.random
npr.seed(int(time.time()))
g = np.array([meta[k][0] for k in hyp.keys()]) # gains 0-1
ng = len(meta)
v = np.ones(ng)
# 设置突变
while all(v == 1): # mutate until a change occurs (prevent duplicates)
# 将突变添加到base hyp上
# [i+7]是因为x中前7个数字为results的指标(P,R,mAP,F1,test_loss=(box,obj,cls)),之后才是超参数hyp
v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)
for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)
hyp[k] = float(x[i + 7] * v[i]) # mutate
# Constrain to limits
# 限制超参再规定范围
for k, v in meta.items():
hyp[k] = max(hyp[k], v[1]) # lower limit
hyp[k] = min(hyp[k], v[2]) # upper limit
hyp[k] = round(hyp[k], 5) # significant digits
# Train mutation
# 训练 使用突变后的参超 测试其效果
results = train(hyp.copy(), opt, device, callbacks)
callbacks = Callbacks()
# Write mutation results
# Write mutation results
# 将结果写入results 并将对应的hyp写到evolve.txt evolve.txt中每一行为一次进化的结果
# 每行前七个数字 (P, R, mAP, F1, test_losses(GIOU, obj, cls)) 之后为hyp
# 保存hyp到yaml文件
print_mutation(results, hyp.copy(), save_dir, opt.bucket)
# Plot results
# 将结果可视化 / 输出保存信息
plot_evolve(evolve_csv)
LOGGER.info(f'Hyperparameter evolution finished {opt.evolve} generations\n'
f"Results saved to {colorstr('bold', save_dir)}\n"
f'Usage example: $ python train.py --hyp {evolve_yaml}')
def run(**kwargs):
# 执行这个脚本/ 调用train函数 / 开启训练
# Usage: import train; train.run(data='coco128.yaml', imgsz=320, weights='yolov5m.pt')
opt = parse_opt(True)
for k, v in kwargs.items():
# setattr() 赋值属性,属性不存在则创建一个赋值
setattr(opt, k, v)
main(opt)
return opt
if __name__ == "__main__":
# 接着上次训练
# python train.py --data ./data/mchar.yaml --cfg yolov5l_mchar.yaml --epochs 80 --batch-size 8 --weights ./runs/train/exp7/weights/last.pt
opt = parse_opt()
main(opt)使用教程
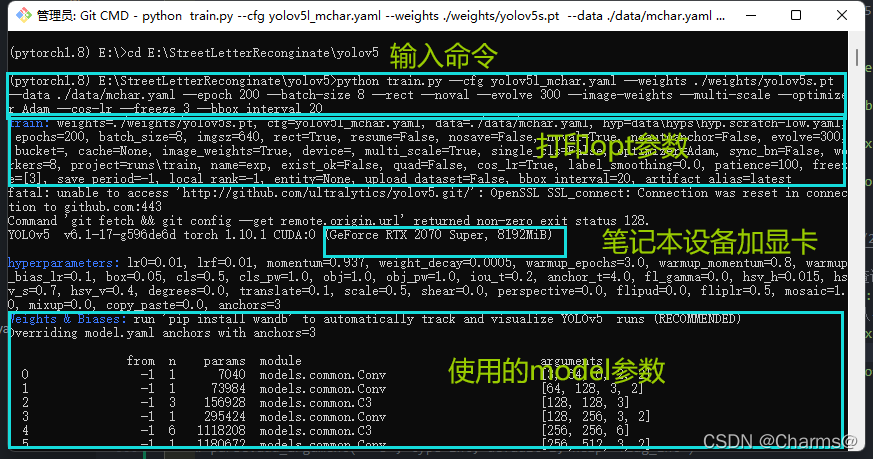
下面我把大家能使用到的参数,给大家打个样,大家可以一葫芦画瓢,根据自己的情况设置这些参数,运行代码如下
python train.py --cfg yolov5l_mchar.yaml --weights ./weights/yolov5s.pt --data ./data/mchar.yaml --epoch 200 --batch-size 8 --rect --noval --evolve 300 --image-weights --multi-scale --optimizer Adam --cos-lr --freeze 3 --bbox_interval 20

总结
到此这篇关于yolov5中train.py代码注释详解与使用的文章就介绍到这了,更多相关yolov5 train.py代码注释内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!