
Node.js 操作本地文件及深入了解fs内置模块
作者:海底烧烤店ai
前言
node.js作为服务端应用,肯定少不了对本地文件的操作,像创建一个目录、创建一个文件、读取文件内容等都是我们开发中经常需要用到的功能
这篇文章我们将深入学习node的内置模块:fs文件操作模块,并使用它来操作本地文件,让我们开始吧!
一、目录操作
创建目录
语法:
fs.mkdir(path[, options], callback)
参数:
path- 文件路径options配置对象,属性有:recursive是否以递归的方式创建目录(创建嵌套目录),默认为falsemode设置目录权限,默认为 0777( Windows 不支持)
callback回调函数,参数如下:err错误信息path仅在options配置recursive为true时出现,表示所创建的顶层目录的绝对路径
演示:
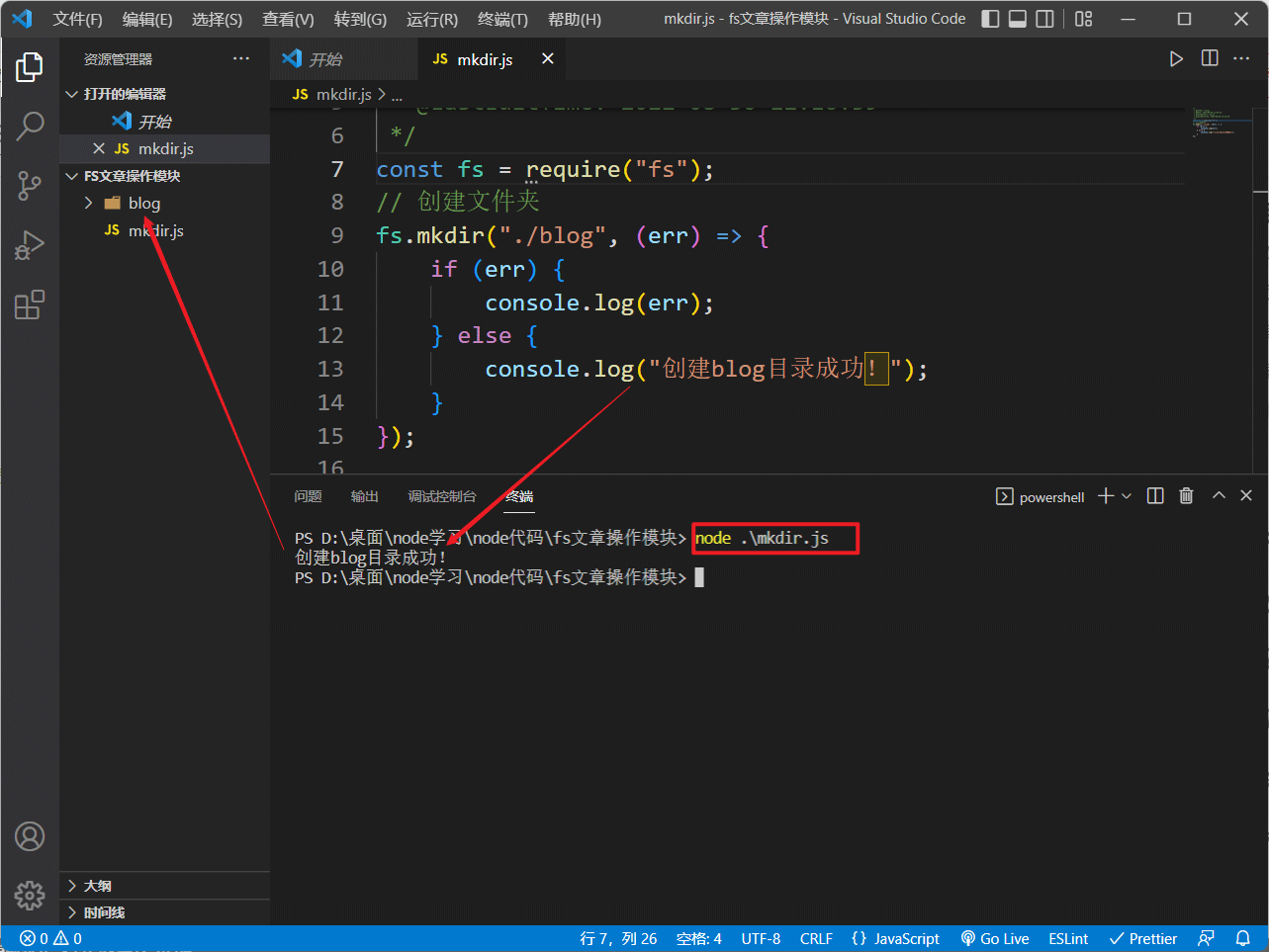
const fs = require("fs");
// 创建文件夹
fs.mkdir("./blog", (err) => {
if (err) {
console.log(err);
} else {
console.log("创建blog目录成功!");
}
});
我们无法直接创建嵌套的目录:
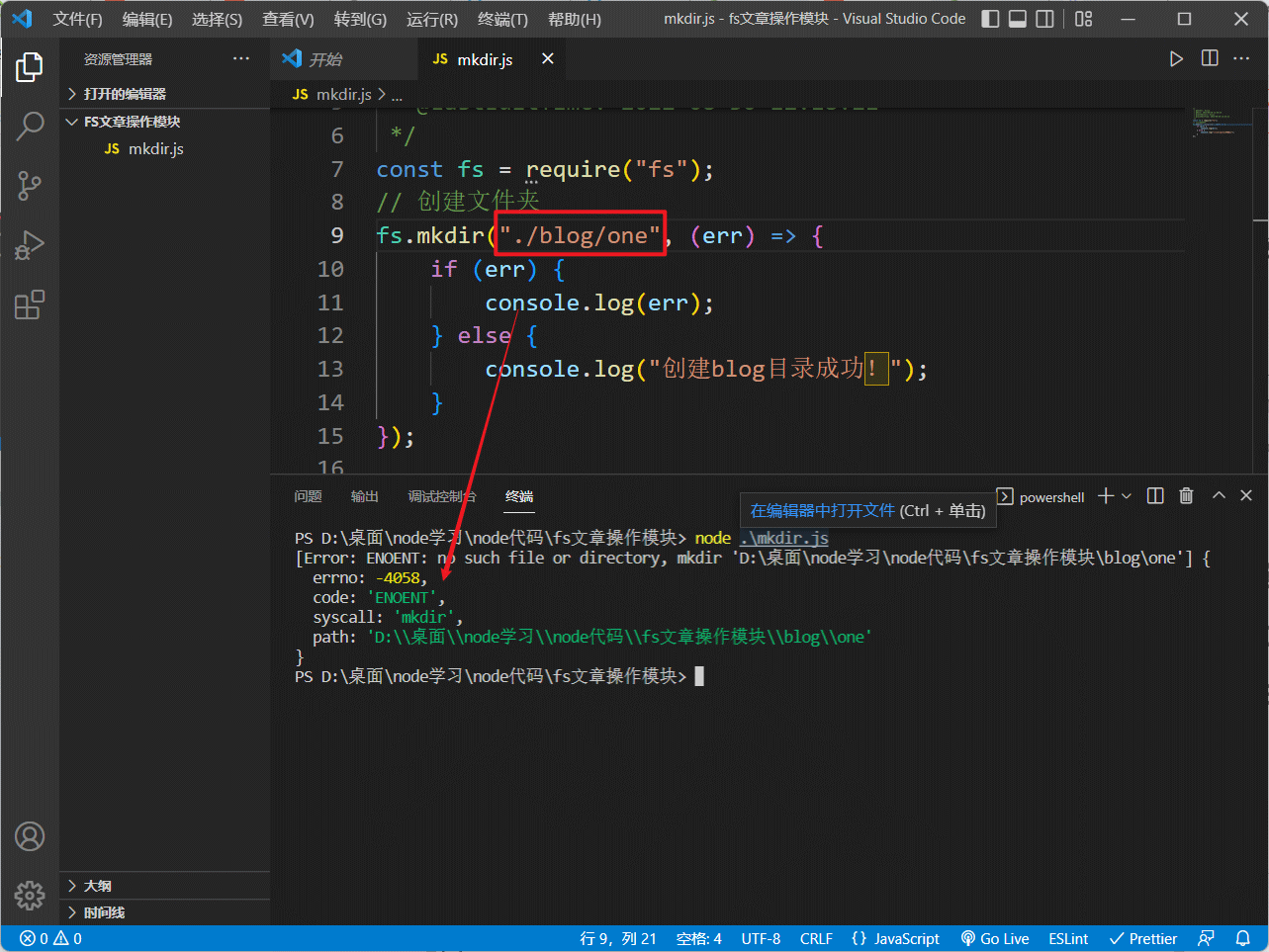
想要创建嵌套目录,需要配置options 对象:
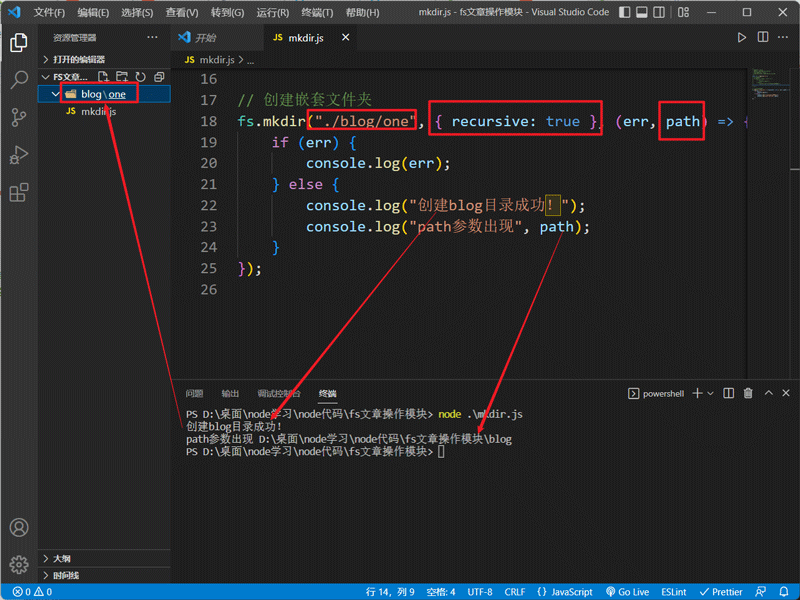
// 创建嵌套文件夹
fs.mkdir("./blog/one", { recursive: true }, (err, path) => {
if (err) {
console.log(err);
} else {
console.log("创建blog目录成功!");
console.log("path参数出现", path);
}
});
目录重命名
语法:
fs.rename(oldPath, newPath, callback)
参数:
- oldPath 老的名字
- newPath 新的名字
- callback 回调函数,参数如下:
- err 错误信息
演示:
// 文件夹重命名
fs.rename("./blog", "./newBlog", (err) => {
if (err) {
console.log(err);
} else {
console.log("重命名成功!");
}
});
读取目录
语法:
fs.readdir(path[, options], callback)
参数:
path目录路径options可以是指定编码格式的字符串,也可以是具有以下属性的对象encoding:指定编码格式,默认值: ‘utf-8’withFileTypesfiles数组是否包含<fs.Dirent>对象,默认值:false
callback回调函数err:错误信息files:目录里的内容,数组格式
演示:
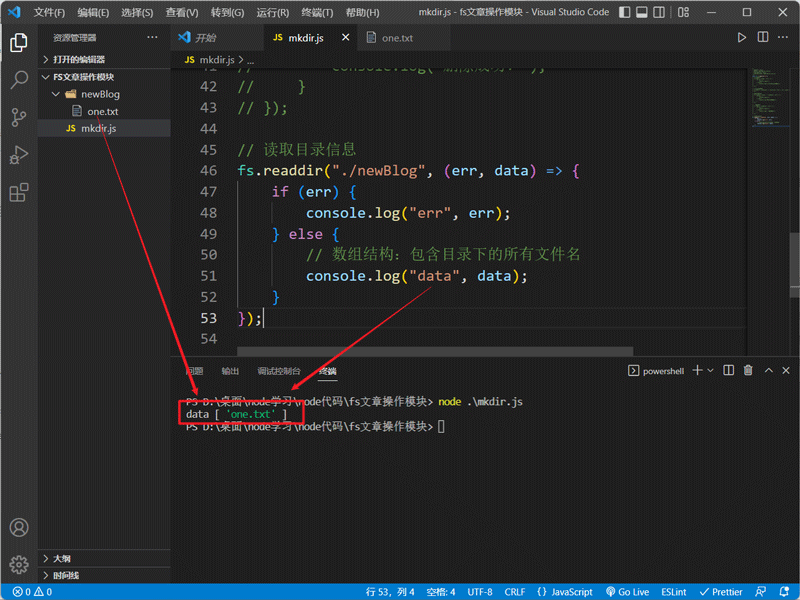
// 读取目录信息
fs.readdir("./newBlog", (err, data) => {
if (err) {
console.log("err", err);
} else {
// 数组结构:包含目录下的所有文件名
console.log("data", data);
}
});
删除目录
语法:
fs.rmdir(path[, options], callback)
参数:
path- 文件路径callback回调函数,参数如下:err错误信息
演示:
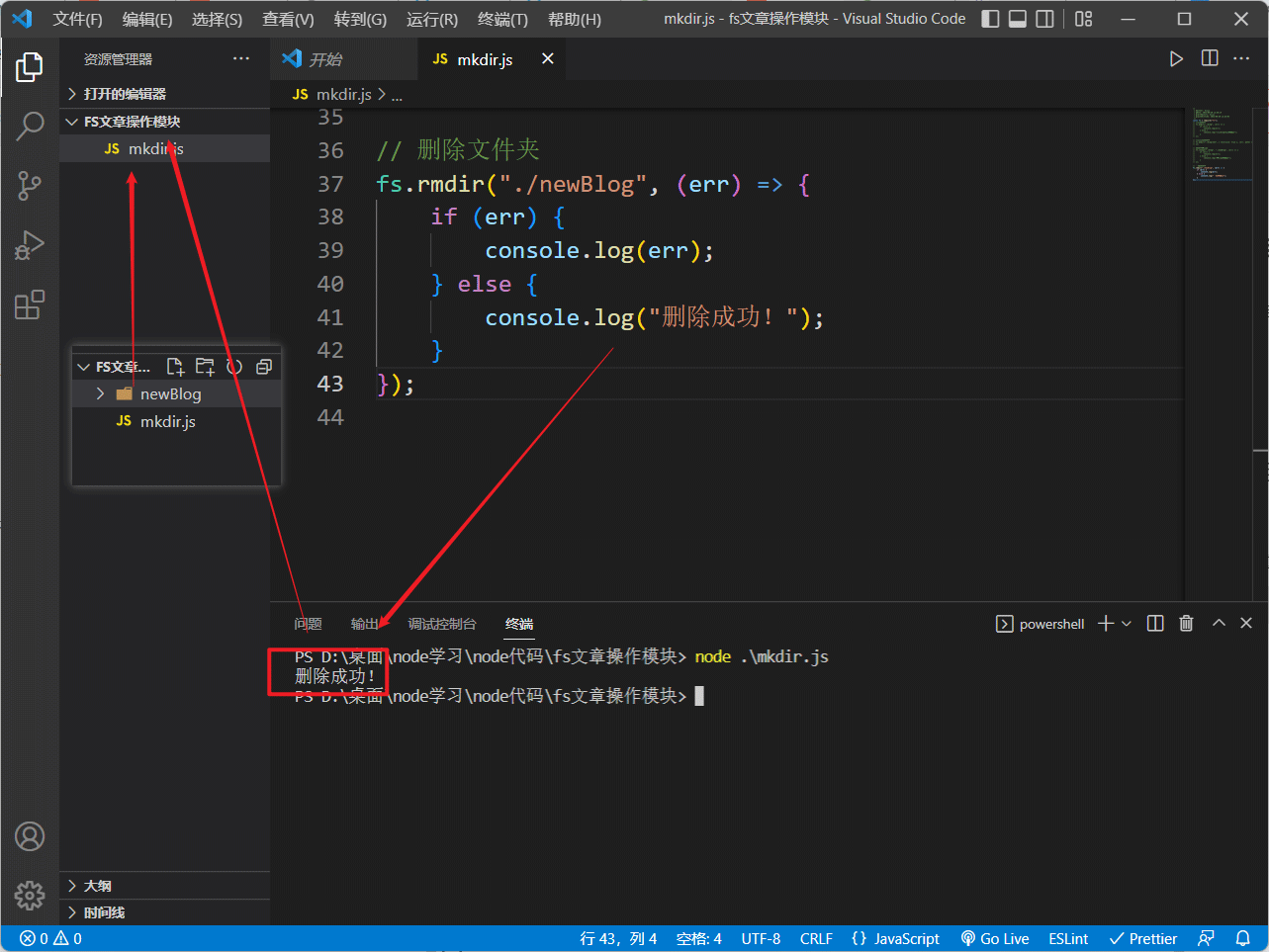
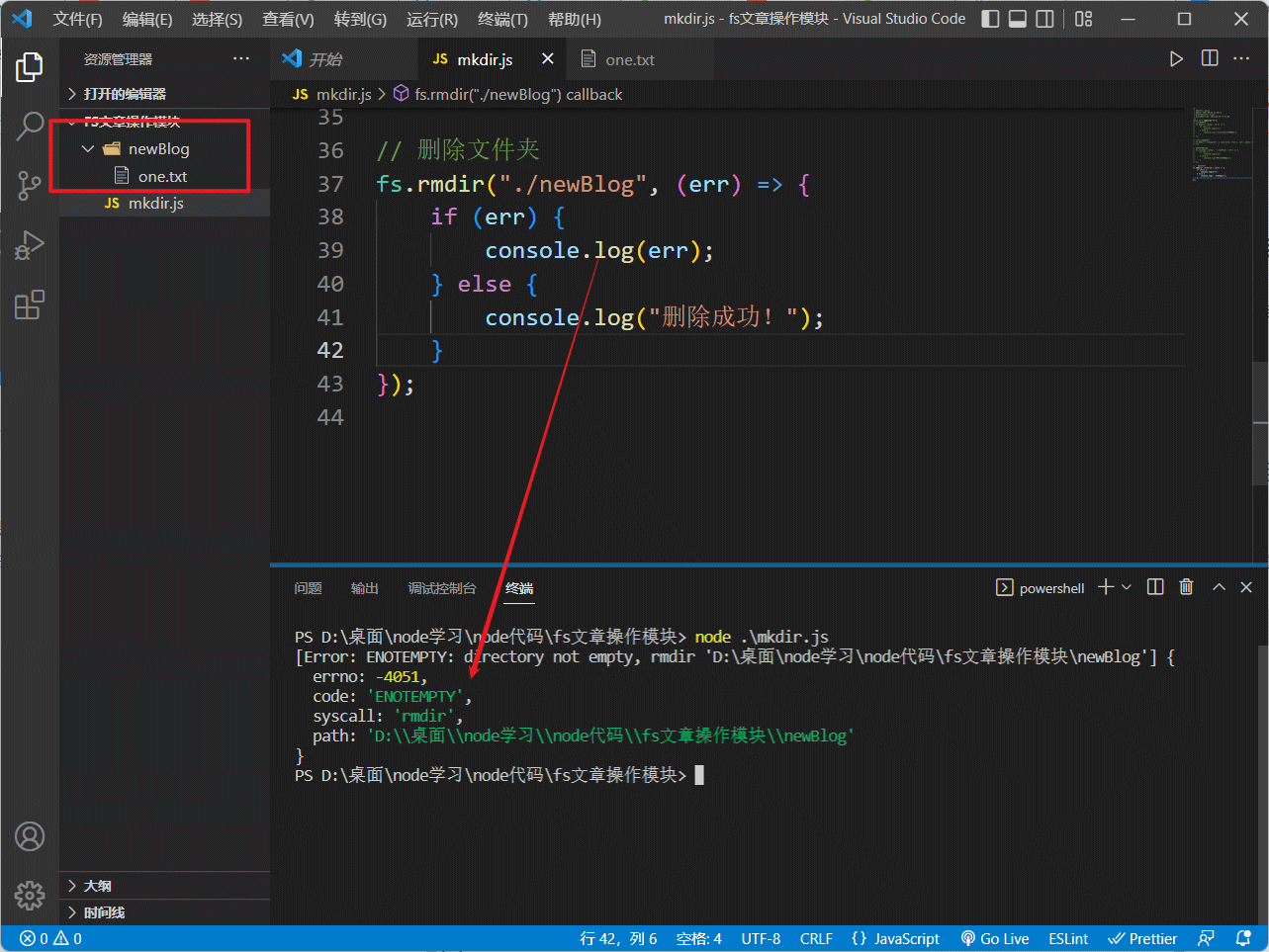
注意: 在目录里面有内容时,是无法直接删除该目录的,需要提前将目录下的所有内容给删掉,删除文件会在下面讲到:
二、文件操作
创建文件
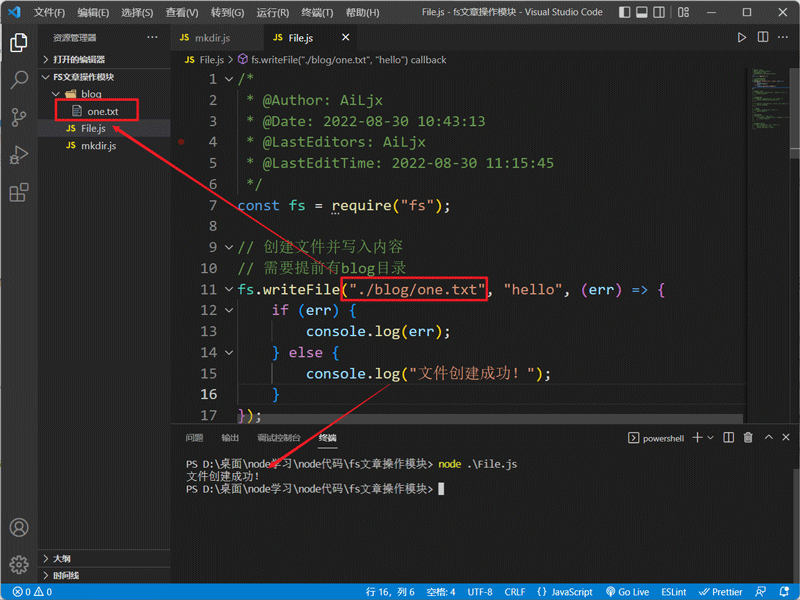
使用fs.writeFile方法创建一个文件并写入内容,如果该文件本来就存在,则会替换文件原本的内容:
// 创建文件并写入内容
// 需要提前有blog目录
fs.writeFile("./blog/one.txt", "hello", (err) => {
if (err) {
console.log(err);
} else {
console.log("文件创建成功!");
}
});创建文件:
创建的内容:
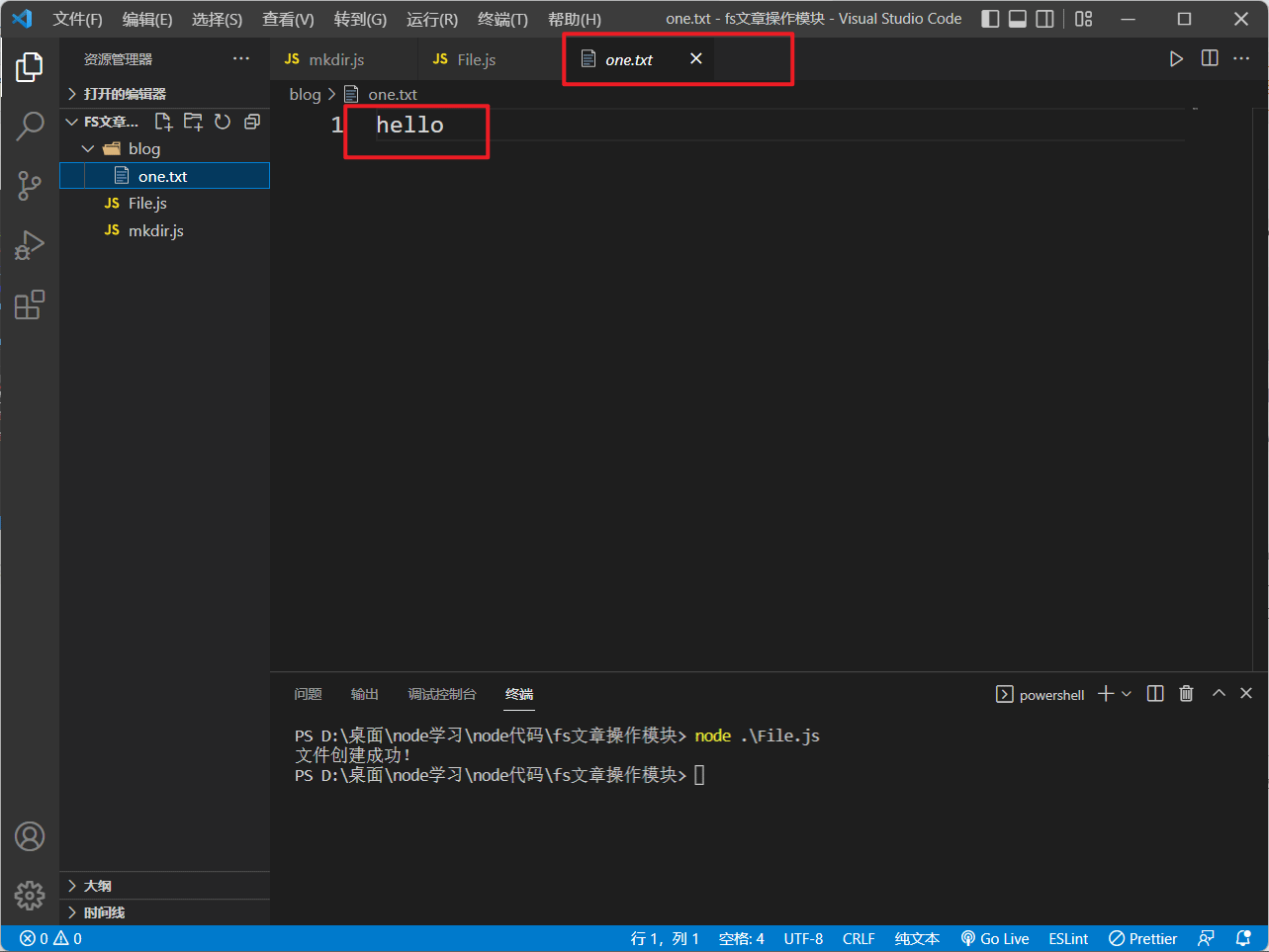
注意: 使用writeFile时,如要原本没有需要创建的这个文件,则writeFile会新建这个文件并向其中写入指定内容,但如果原本有这个文件,则writeFile会将原本的这个文件内容替换成我们指定的内容
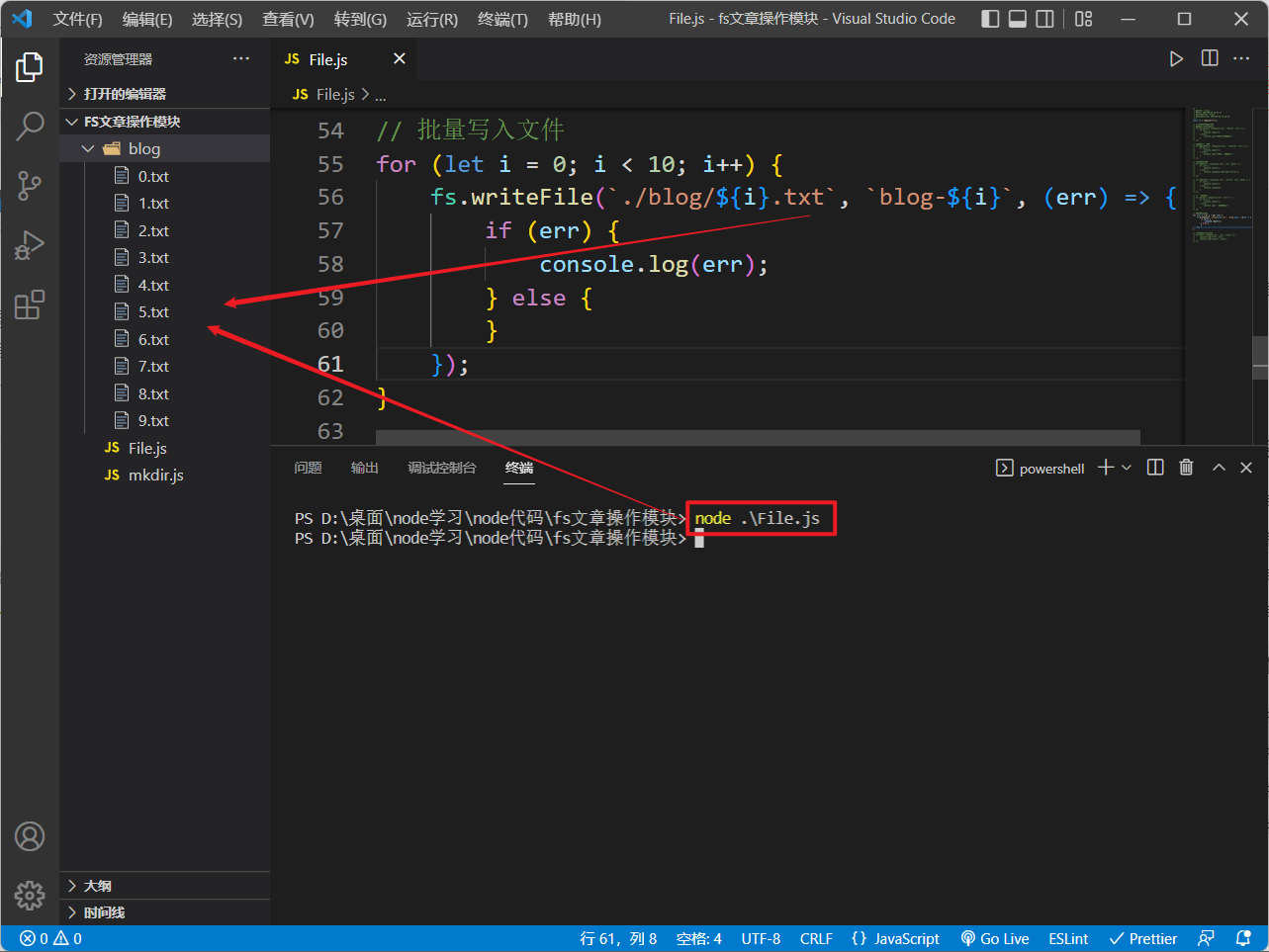
我们可以在循环中批量写入文件:
// 批量写入文件
for (let i = 0; i < 10; i++) {
fs.writeFile(`./blog/${i}.txt`, `blog-${i}`, (err) => {
if (err) {
console.log(err);
} else {
}
});
}
追加文件内容
使用fs.appendFile方法向一个文件内追加内容:
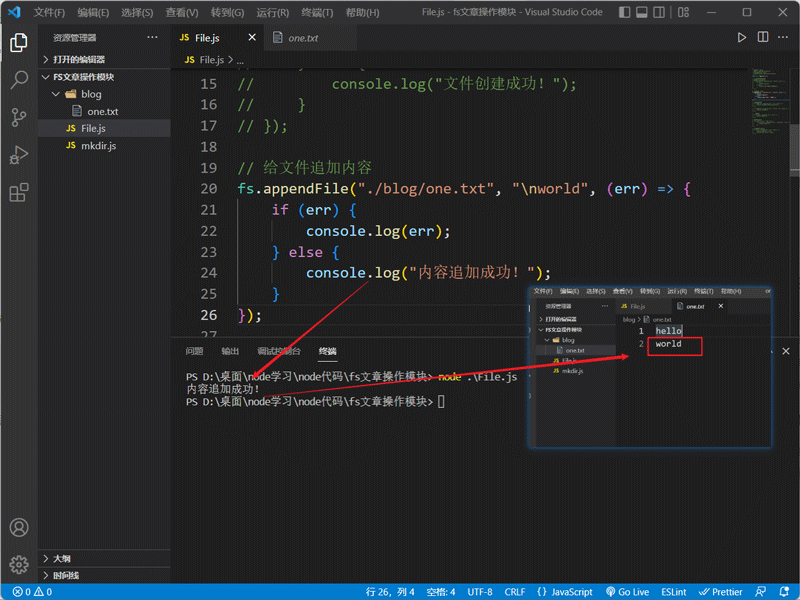
// 给文件追加内容
fs.appendFile("./blog/one.txt", "\nworld", (err) => {
if (err) {
console.log(err);
} else {
console.log("内容追加成功!");
}
});上面的代码将在
blog目录下的one.txt中另起一行追加world的内容,\n表示换行,同时也支持其它的转义符号
读取文件内容
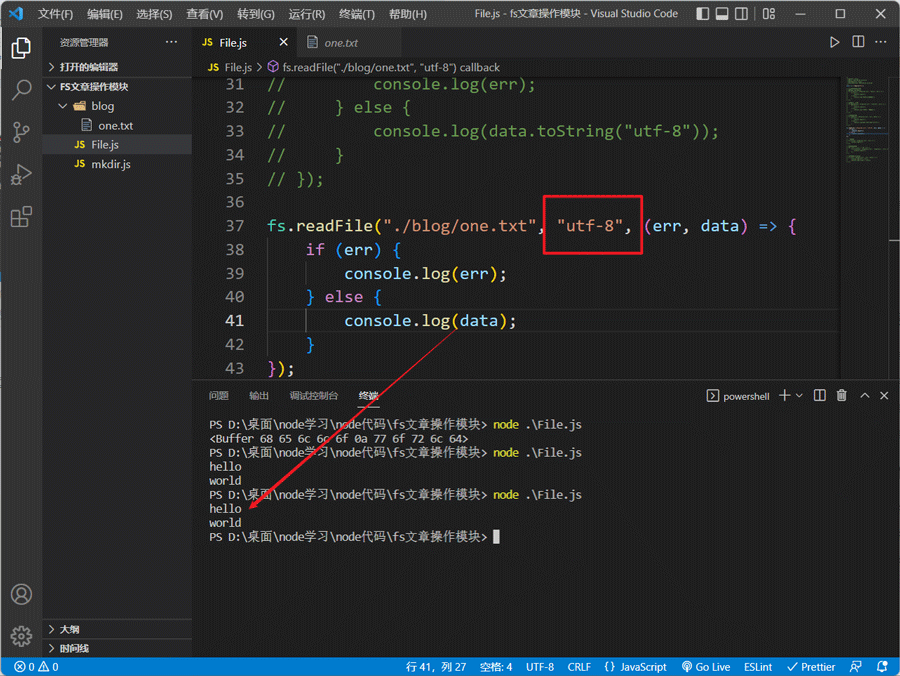
使用fs.readFile方法读取文件内容:
// 读取文件内容
fs.readFile("./blog/one.txt", (err, data) => {
if (err) {
console.log(err);
} else {
console.log(data);
}
});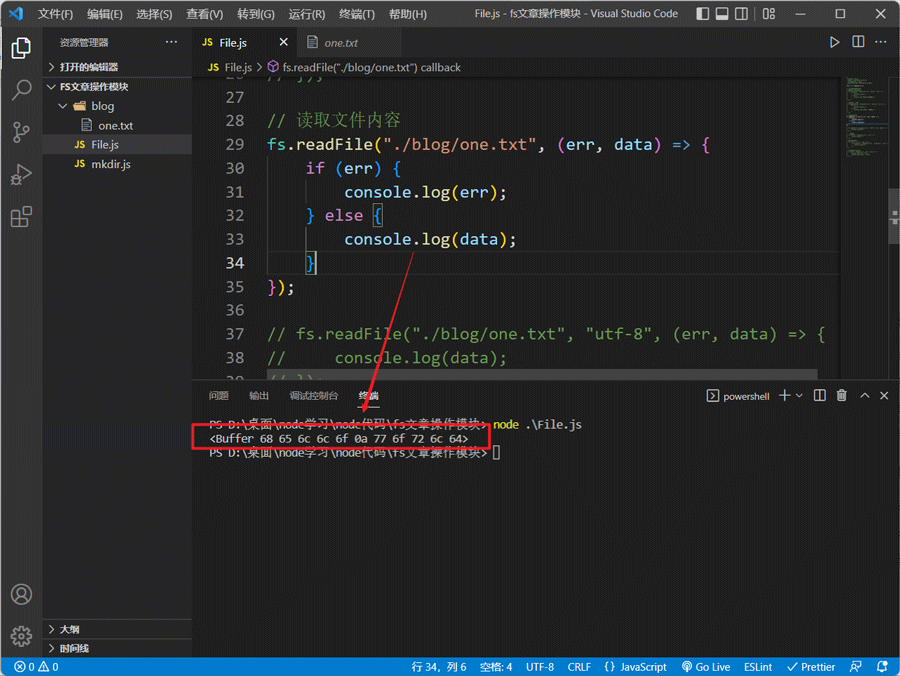
默认读取的内容是nodejs的Buffer数组格式,我们可以在获取数据时通过toString将其转化成字符串:
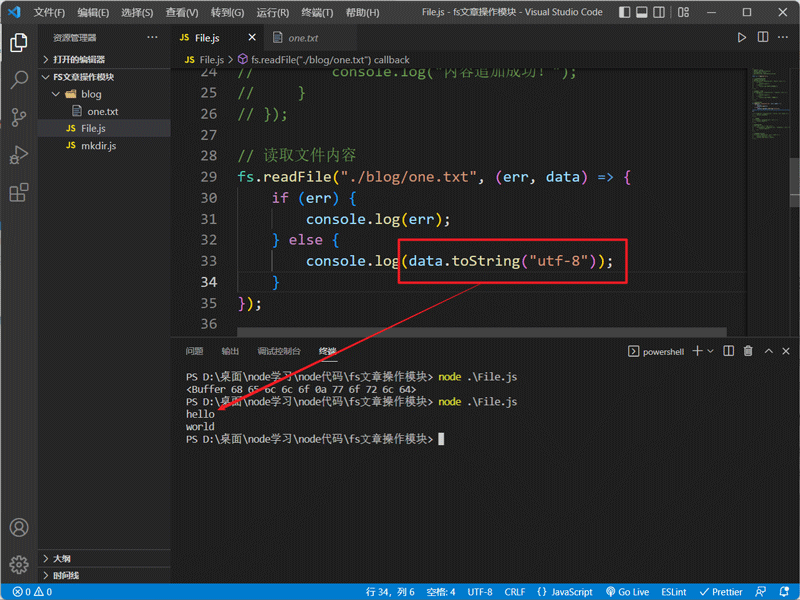
也可以直接在读取文件时指定读取的编码格式:
删除文件
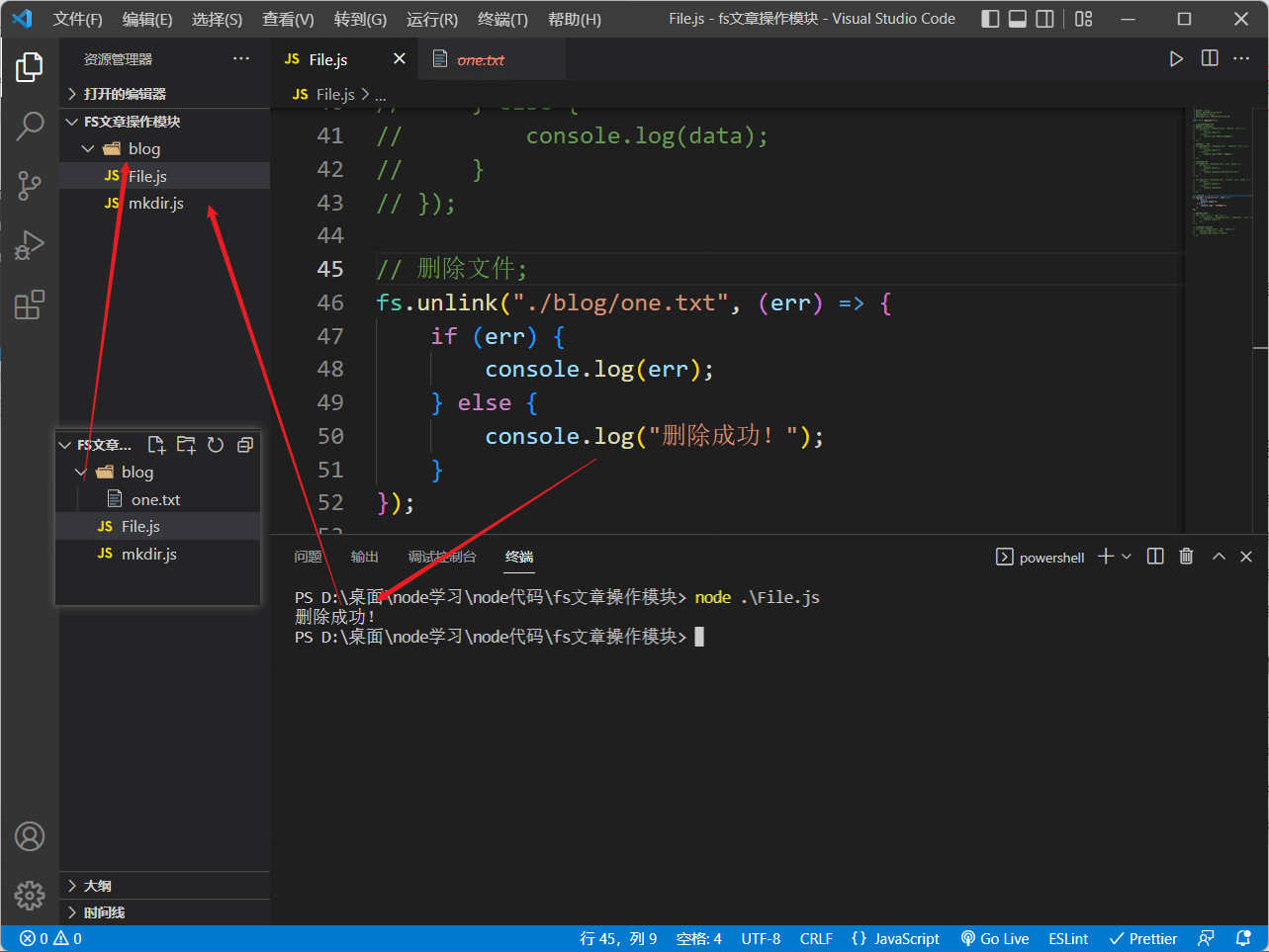
使用fs.unlink方法删除文件:
// 删除文件;
fs.unlink("./blog/one.txt", (err) => {
if (err) {
console.log(err);
} else {
console.log("删除成功!");
}
});
三、 读取文件/目录信息
使用fs.stat可以用来获取指定路径的内容的详细信息,包括文件大小、创建时间等:
// 读取文件/目录信息
fs.stat("./blog/one.txt", (err, stats) => {
if (err) {
console.log(err);
} else {
console.log("stats", stats);
}
});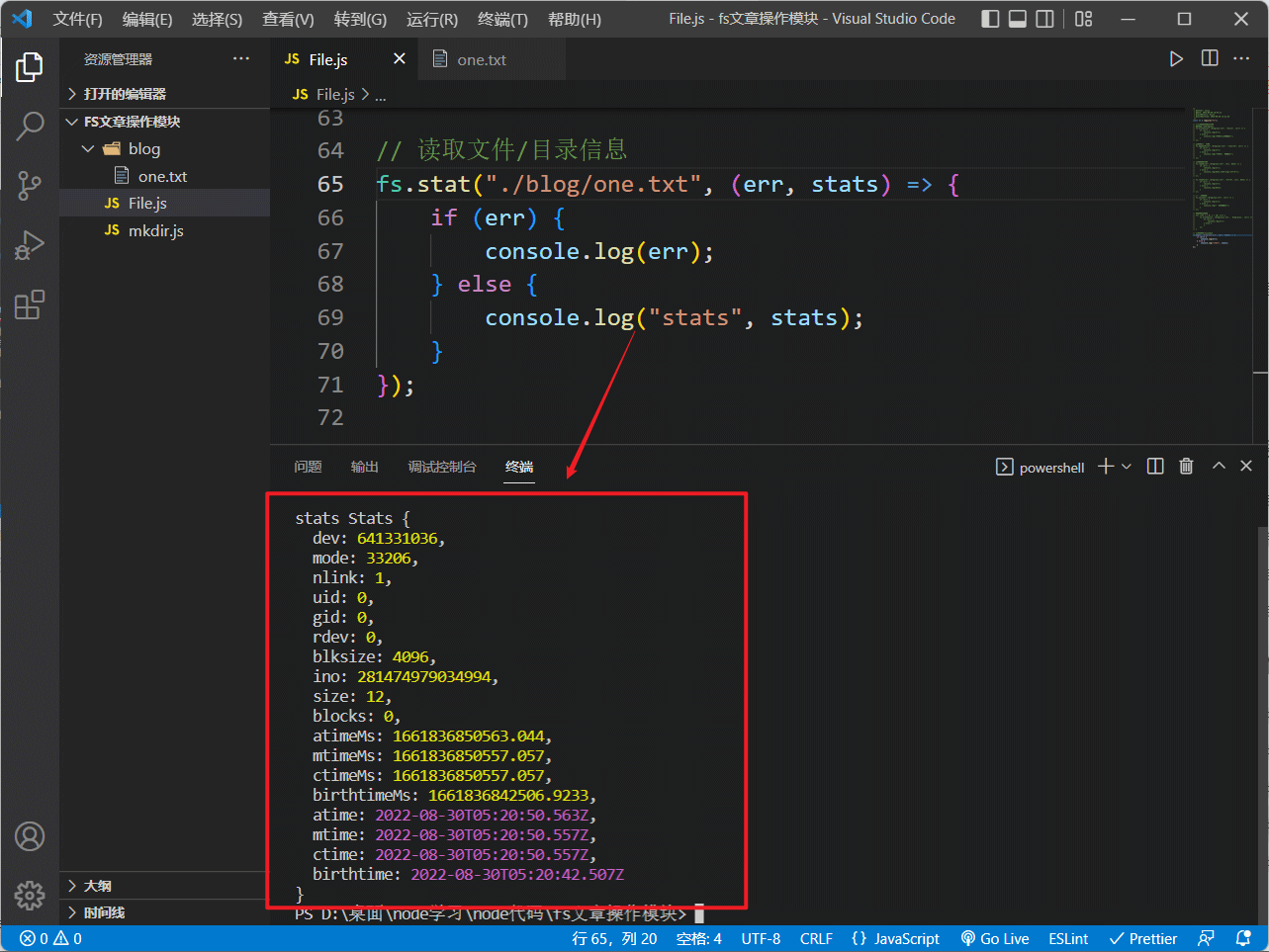
回调函数中的stats参数会接收到文件的详细信息对象,其中各个属性表示的含义如下:
Stats {
// 包含文件的设备的数值型标识
dev: 641331036,
// 描述文件类型和模式的位域
mode: 33206,
// 文件的硬链接数量
nlink: 1,
// 文件拥有者的数值型用户标识
uid: 0,
// 拥有文件的群组的数值型群组标识
gid: 0,
// 如果文件表示设备,则为数字设备标识符
rdev: 0,
// i/o 操作的文件系统块大小
blksize: 4096,
// 文件的文件系统特定的“inode”号
ino: 281474979034994,
// 文件的字节大小
size: 12,
// 分配给文件的块的数量
blocks: 0,
// 指示上次访问此文件的时间戳
atimeMs: 1661836850563.044,
// 指示该文件最后一次修改的时间戳
mtimeMs: 1661836850557.057,
// 指示文件状态最后一次更改的时间戳
ctimeMs: 1661836850557.057,
// 指示此文件创建时间的时间戳
birthtimeMs: 1661836842506.9233,
// 表示文件最后一次被访问的时间
atime: 2022-08-30T05:20:50.563Z,
// 表示文件最后一次被修改的时间
mtime: 2022-08-30T05:20:50.557Z,
// 表示文件状态最后一次被改变的时间
ctime: 2022-08-30T05:20:50.557Z,
// 表示文件的创建时间
birthtime: 2022-08-30T05:20:42.507Z
}stats还有如下的常用方法:
stats.isDirectory()判断该内容是否是一个目录stats.isFile()判断该文件是否是一个常规文件
四、同步方法
上面三节所讲的所有fs的方法都是异步的,如下图所示:
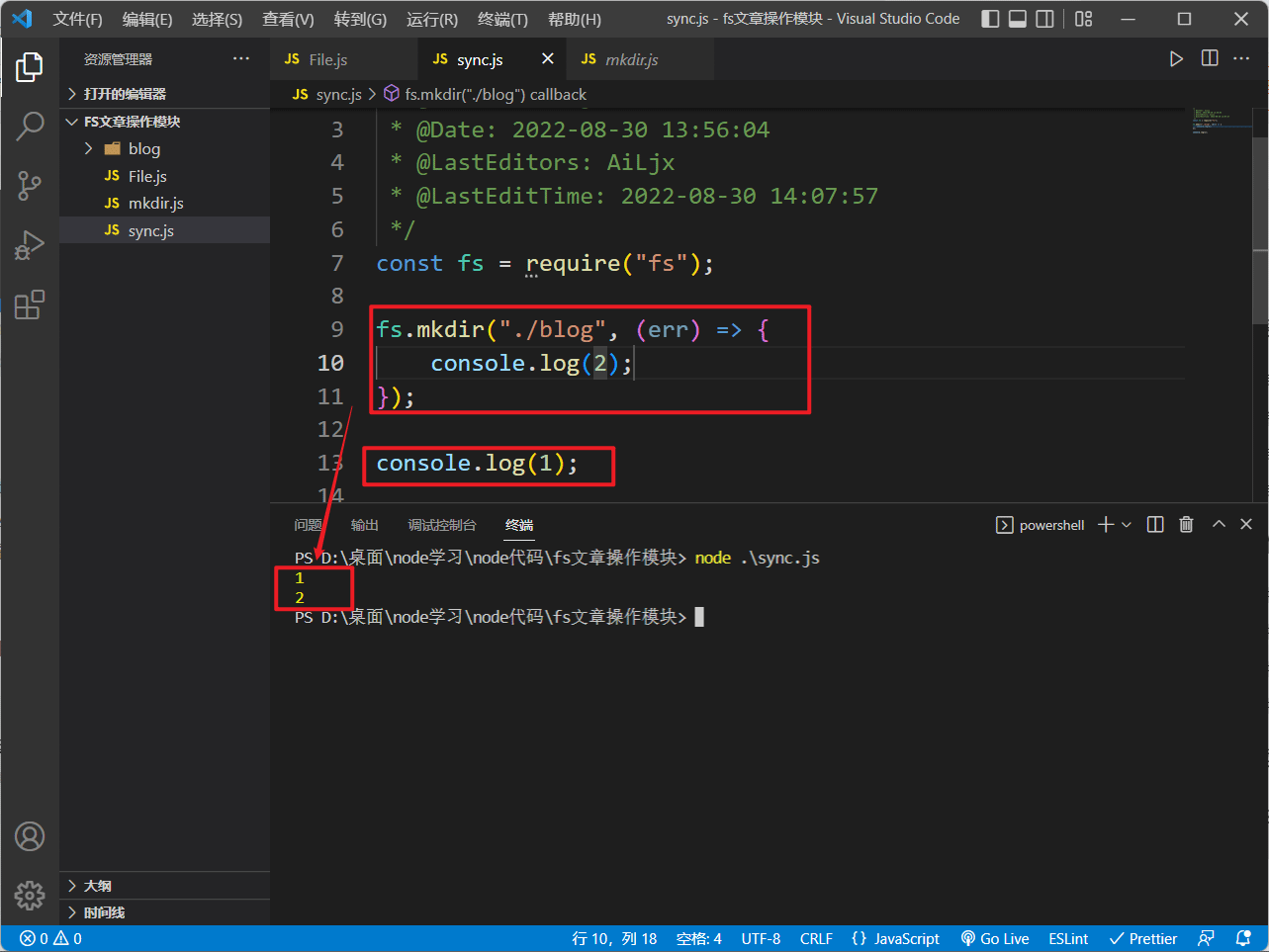
由于Node环境执行的JavaScript代码是服务器端代码,所以绝大部分需要在服务器运行期反复执行业务逻辑的代码必须使用异步代码
否则,同步代码在执行时期,服务器将停止响应,因为JavaScript只有一个执行线程
Sync同步方法
但node也为我们提供了一些fs的同步方法,我们只需在对应的方法名后加上Sync即可使用它的同步方法:
fs.mkdirSync("./blog");注意:fs的同步方法没有callback(回调函数)参数,需要获取的内容(如readdir方法回调函数参数中的files参数数据)会通过函数return的形式返回出去
大家可以自己动手试一下:在上面我们遇到过的
fs的方法名加上Sync后缀使其变成同步方法。这里就不一一举例了
更多fs同步的api可见:nodejs官方文档
捕捉错误
需要注意的是:如果我们使用同步写法,一定要做好错误收集与处理!以防止服务端因同步方法报错而导致宕机:
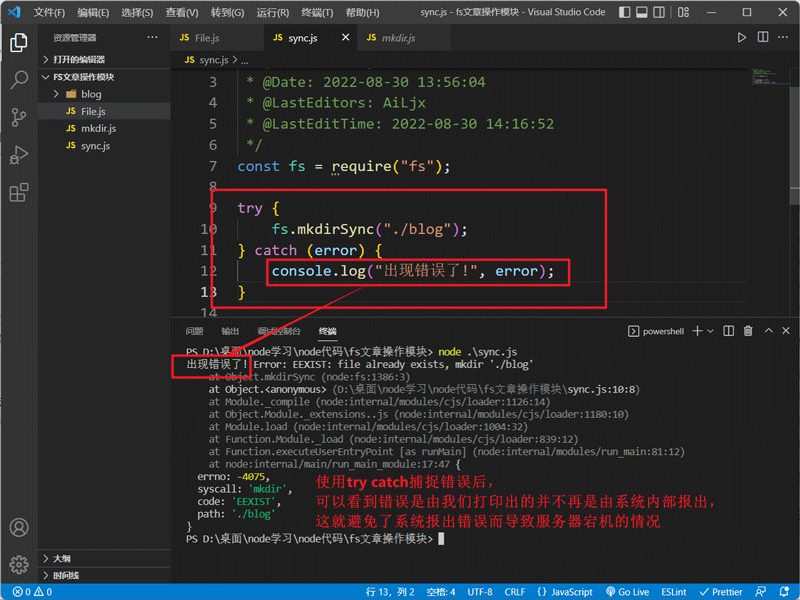
删除不为空目录的案例
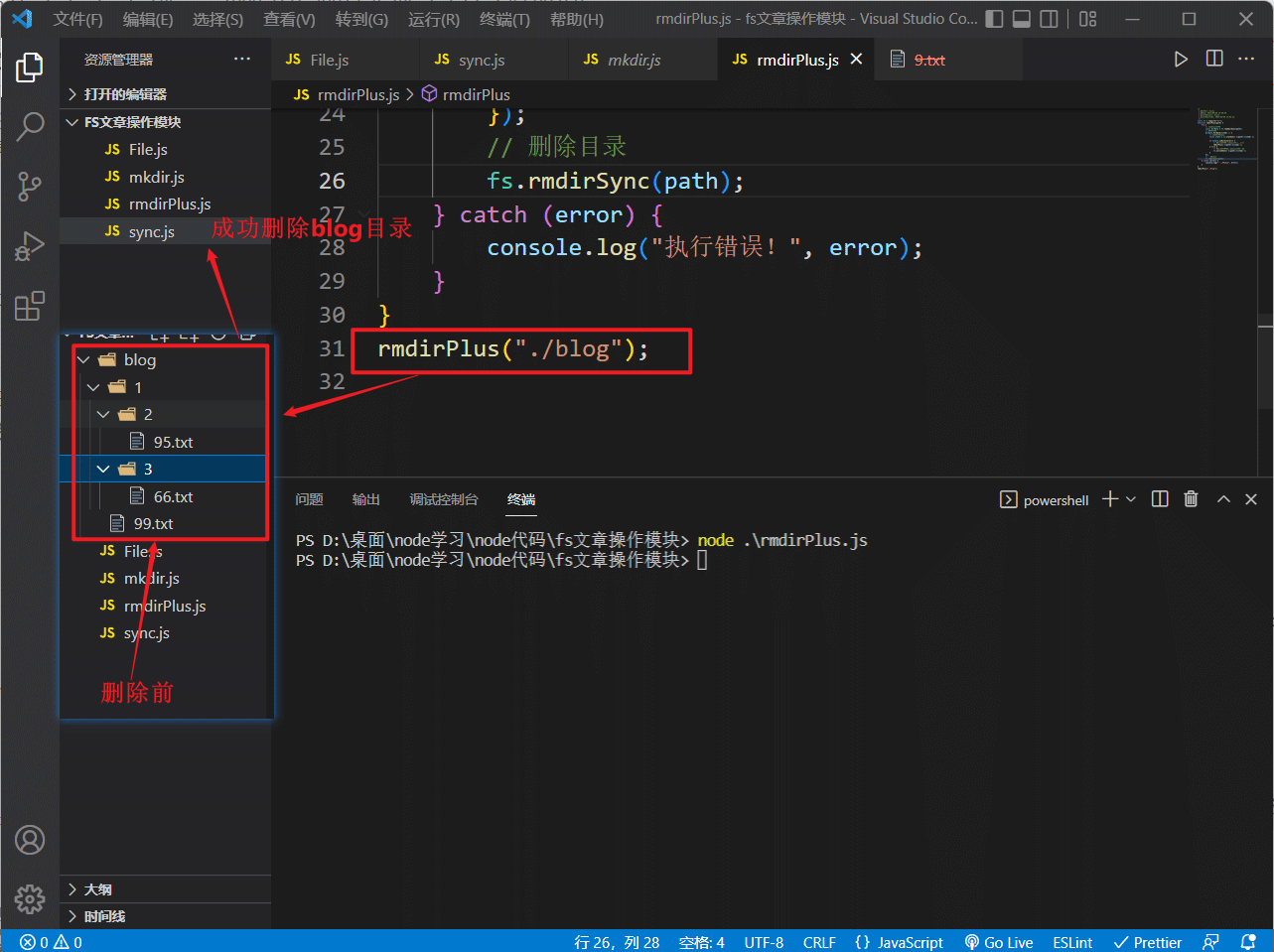
在目录操作中,我们了解到在目录内容不为空时,我们是无法直接使用rmdir删除该目录的
那么我们就需要先使用unlink将目录内的文件删除掉,这里我们将使用同步方法实现一个通用函数,来实现删除任何指定的目录,不管它内容为不为空:
const fs = require("fs");
function rmdirPlus(path) {
try {
// 读取目录内容
const dirData = fs.readdirSync(path);
// 遍历内容
dirData.forEach((item) => {
// 获取内容信息
const stats = fs.statSync(`${path}/${item}`);
if (stats.isDirectory()) {
// 如果该内容为目录,则进行递归
rmdirPlus(`${path}/${item}`);
} else {
// 如果该内容不为目录,直接删除
fs.unlinkSync(`${path}/${item}`);
}
});
// 删除目录
fs.rmdirSync(path);
} catch (error) {
console.log("执行错误!", error);
}
}
在服务端,如果没有必要就尽量不要使用同步代码!非必要不使用
服务器启动时如果需要读取配置文件,或者结束时需要写入到状态文件时,可以使用同步代码,因为这些代码只在启动和结束时执行一次,不影响服务器正常运行时的异步执行
五、Promise方法
内置模块fs的所有异步方法都可以改写成promise的写法,我们只需在引入fs模块时指定promises后缀:
const fs = require("fs").promises;之后使用fs的方法就可以直接使用promise的写法了:
const fs = require("fs").promises
fs.readFile('./blog/one.txt', 'utf-8').then(data => {
console.log(data)
})让我们使用promise的写法改写一下上边删除不为空目录的案例:
const fs = require("fs").promises;
async function rmdirPlus(path) {
try {
// 读取目录内容
const dirData = await fs.readdir(path);
await Promise.all(
dirData.map(async (item) => {
// 获取内容信息
const stats = await fs.stat(`${path}/${item}`);
if (stats.isDirectory()) {
// 如果该内容为目录,则进行递归
await rmdirPlus(`${path}/${item}`);
} else {
// 如果该内容不为目录,直接return出去
return fs.unlink(`${path}/${item}`);
}
})
);
// 删除目录
await fs.rmdir(path);
} catch (error) {
console.log("执行错误!", error);
}
}这里巧妙的使用了map方法和Promise.all方法,并通过async和await来实现我们的需求
如果你需要同步使用fs,推荐使用async和await 来代替上面提到的Sync同步方法!
因为
await必须用在async函数中,async函数调用不会造成阻塞,它内部所有的await阻塞都被封装在一个Promise对象中异步执行
六、大文件操作
前面我们是通过readFile方法来读取文件内容,通过writeFile和appendFile来写入文件内容,这些方法对文件数据的操作都是一次性操作,即一次性将数据读出或一次性将数据写入
在文件数据内容比较大时,这些方法的效率就会变得很慢,那有没有什么效率高的方式呢?这就需要引入fs模块的stream流了
stream流介绍
stream是Node.js提供的一个仅在服务区端可用的模块,目的是支持“流”这种数据结构
什么是流? 流是一种抽象的数据结构
想象水流,当在水管中流动时,就可以从某个地方(例如自来水厂)源源不断地到达另一个地方(比如你家的洗手池)
我们也可以把数据看成是数据流,比如你敲键盘的时候,就可以把每个字符依次连起来,看成字符流。这个流是从键盘输入到应用程序,实际上它还对应着一个名字:标准输入流(stdin)
如果应用程序把字符一个一个输出到显示器上,这也可以看成是一个流,这个流也有名字:标准输出流(stdout)。流的特点是数据是有序的,而且必须依次读取,或者依次写入,不能像Array那样随机定位
有些流用来读取数据,比如从文件读取数据时,可以打开一个文件流,然后从文件流中不断地读取数据。有些流用来写入数据,比如向文件写入数据时,只需要把数据不断地往文件流中写进去就可以了
读取数据
在Node.js中,读取流(Readable流) 也是一个对象,我们只需要响应流的事件就可以了:
data事件表示流的数据已经可以读取了end事件表示这个流已经到末尾了,没有数据可以读取了error事件表示出错了
const fs = require("fs");
// 创建一个可读的流
const rs = fs.createReadStream("./1.txt", "utf-8");
// 监听data事件,数据会一点一点的进行读取
rs.on("data", function (chunk) {
console.log("on", chunk);
});
// 监听end事件,数据读取完毕后触发
rs.on("end", function () {
console.log("end");
});
// 监听error事件,出错时触发
rs.on("error", function (err) {
console.log("error", err);
});要注意,data事件可能会有多次,每次传递的chunk是流的一部分数据
写入数据
要以流的形式写入文件,只需要使用 写入流(Writable流) 不断调用write()方法,最后以end()结束:
const fs = require("fs");
// 创建一个可写的流
const ws = fs.createWriteStream("./2.txt", "utf-8");
// 写入内容
ws.write("11111111111111111111");
ws.write("22222222222222222222");
ws.write("33333333333333333333");
ws.write("44444444444444444444");
ws.end();管道(文件复制)
我们需要将一个大文件的内容复制到另一个大文件里,这就需要同时使用读取流和写入流,但我们自己使用两者结合时,可能会无法控制某一方的速率,导致两方速率不同步,使得最后复制过去的数据不完整
而node贴心的为我们提供了一个pipe管道(Readable流的pipe()方法),用来联通读取流和写入流,并自动控制两者的速率
pipe就像可以把两个水管串成一个更长的水管一样,两个流也可以串起来。一个Readable流和一个Writable流串起来后,所有的数据自动从Readable流进入Writable流,这种操作叫pipe。
让我们用pipe()把一个文件流和另一个文件流串起来,这样源文件的所有数据就自动写入到目标文件里了,所以,这实际上是一个复制文件的程序:
const fs = require("fs");
const readStream = fs.createReadStream("./1.txt");
const writeStream = fs.createWriteStream("./2.txt");
// 将1.txt内的数据复制到2.txt中
// 若开始时没有2.txt文件,则会自动创建
// 若开始时有2.txt文件,则会使用1.txt的内容替换掉其中的内容
readStream.pipe(writeStream);❗️ 注意:
我们使用readStream.pipe(writeStream)时,数据是从左到右,从可读流到可写流传递,既将readStream的数据传递到writeStream中
小技巧:
pipe管道可以链式调用,这在下一节我们讲到gzip时会用到
七、补充
判断路径是否存在:
fs中exists方法能够判断某一路径是否存在,但exists异步的方法官方已经不建议使用,建议使用的是加Sync的同步方法:
const fs = require("fs");
// exists方法:判断路径是否存在,异步的方法官方已经不建议使用,建议使用的是加Sync的同步方法
console.log(fs.existsSync("./stream流")); // true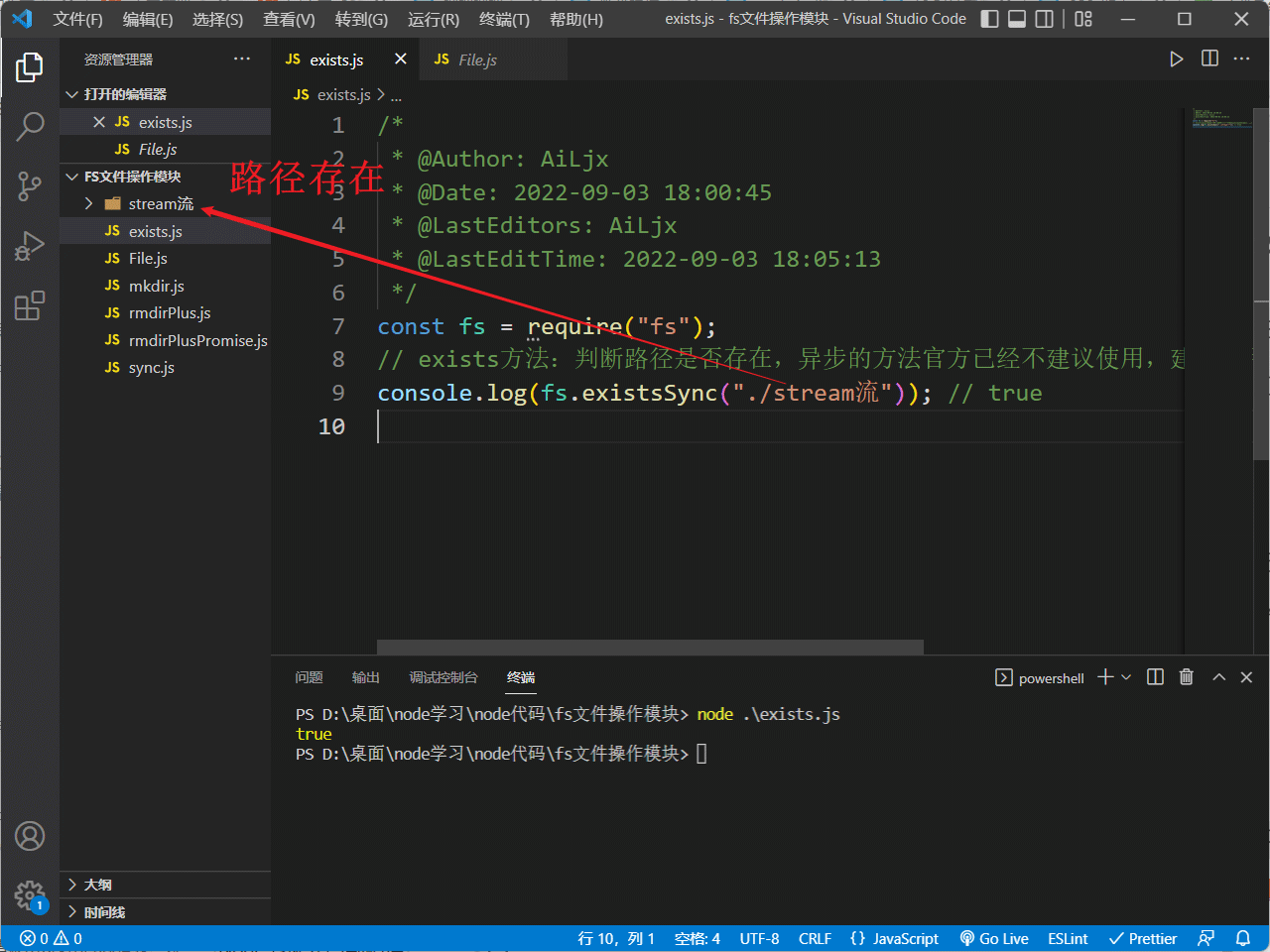
结语
本篇文章详细讲解了node.js的内置模块fs的常用方法,并介绍了fs的同步方法与Promise方法,需要注意的是,在node开发中应尽量减少同步的写法,从而避免因同步阻塞代码执行导致服务器宕机
到此这篇关于Node.js 操作本地文件及深入了解 fs 内置模块的文章就介绍到这了,更多相关Node.js fs 内置模块内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!