
Python实现自动化处理PDF文件的方法详解
作者:梦里逆天
这篇文章主要为大家详细介绍了如何使用Python完成简单的PDF文件处理操作,如PDF文件的批量合并、拆分、加密以及添加水印等,需要的可以参考一下
自动化处理PDF文件
使用Python完成简单的PDF文件处理操作,如PDF文件的批量合并、拆分、加密以及添加水印等。
1. 批量合并PDF文件
from pathlib import Path
# PdfFileReader用于读取PDF文件,PdfFileMerger用于合并PDF文件
from PyPDF2 import PdfFileReader, PdfFileMerger
src_folder = Path('PDF1') # 设置要合并的多个PDF文件所在的文件路径
des_file = Path(r'PDF2\combine.pdf') # 设置合并后的PDF文件的保存文件夹和文件名
# 调用路径对象的parent属性返回父文件夹(即保存文件夹)的路径
if not des_file.parent.exists():
# 如果该文件夹不存在,则创建该文件夹
des_file.parent.mkdir(parents=True)
# 获取所有要合并的PDF文件的路径
file_list = list(src_folder.glob('*.pdf'))
# 读取PDF并进行合并
merger = PdfFileMerger() # 创建PdfFileMerger对象
outputPages = 0 # 统计合并到PDF文件的总页数
# 遍历文件列表
for pdf in file_list:
input_file = PdfFileReader(str(pdf)) # 读取待合并的PDF文件
merger.append(input_file) # 将PDF文件合并到PdfFileMerger对象中
pageCount = input_file.getNumPages() # 获取PDF文件的页数
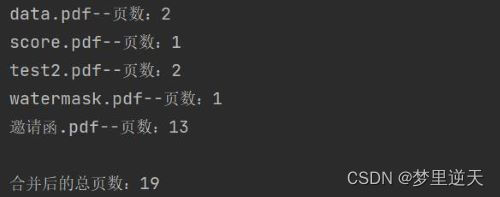
print(f'{pdf.name}--页数:{pageCount}')
outputPages += pageCount # 进行累加,统计总页数
merger.write(str(des_file)) # 将合并好的PDF文件写入指定的路径
merger.close() # 关闭PdfFileMerger对象,释放资源
print(f'\n合并后的总页数:{outputPages}')
测试文件:
效果:
2. 批量拆分PDF文件
from math import ceil
from pathlib import Path
from PyPDF2 import PdfFileReader, PdfFileWriter
src_folder = Path('PDF2') # 设置要拆分的多个PDF文件所在的文件路径
output_folder = Path('PDF2') # 设置拆分后的PDF文件的保存文件夹和文件名
# 获取所有要拆分的PDF文件的路径
file_list = list(src_folder.glob('*.pdf'))
# 采用按固定页数进行拆分
step = 5 # 每份为5页
for pdf in file_list:
inputFile = PdfFileReader(str(pdf))
pages = inputFile.getNumPages() # 获取PDF文件的页数
# 判断PDF文件页数是否小于等于step
if pages <= step:
# 若是则不进行拆分
continue
else:
parts = ceil(pages / step) # 拆分的份数,向上取整
# 根据份数进行循环
for pt in range(parts):
# 计算每一份的开始页码和结束页码
# PyPDF2模块中,PDF文件页码从0开始
start = step * pt
# 判断是否是最后一份
if pt != (parts - 1):
# 如果不是最后一份,那么结束页码为开始页码加每份页数减1
end = start + step - 1
else:
# 若是最后一份,则结束页码等于文件页数减1
end = pages - 1
# 拆分文件
outputfile = PdfFileWriter() # 创建PdfFileWriter对象
for pageNum in range(start, end + 1):
outputfile.addPage(inputFile.getPage(pageNum))
# 调用路径对象的stem属性获取文件的主名,与后面的字符串拼接成PDF文件名
pt_name = f'{pdf.stem}_第{pt + 1}份.pdf'
pt_file = output_folder / pt_name # 生成当前份的PDF文件的保存路径
with open(pt_file, 'wb') as f:
outputfile.write(f)
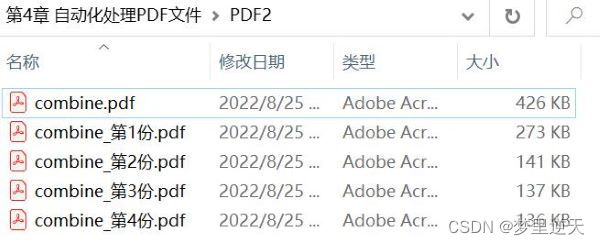
print(f'【{pdf.name}】共{pages}页,拆分为{parts}份-->完成')
效果:

3. 批量加密PDF文件
from pathlib import Path
from PyPDF2 import PdfFileReader, PdfFileWriter
src_folder = Path('PDF2') # 设置要加密的多个PDF文件所在的文件路径
output_folder = Path('PDF2') # 设置加密后的PDF文件的保存文件夹和文件名
# 获取所有要加密的PDF文件的路径
file_list = list(src_folder.glob('*.pdf'))
# 遍历文件列表
for pdf in file_list:
inputFile = PdfFileReader(str(pdf)) # 读取文件
outputFile = PdfFileWriter() # 创建PdfFileWriter对象
pageCount = len(inputFile.pages) # 获得PDF文件页数
for pageNum in range(pageCount):
# 将PDF内容逐页添加到输出文件
outputFile.add_page(inputFile.pages[pageNum])
# 进行加密
outputFile.encrypt('123456')
# 输出文件名
output_name = f'{pdf.stem}_encrypted.pdf'
# 输出文件的路径
output_path = output_folder / output_name
with open(output_path, 'wb') as pf:
outputFile.write(pf)
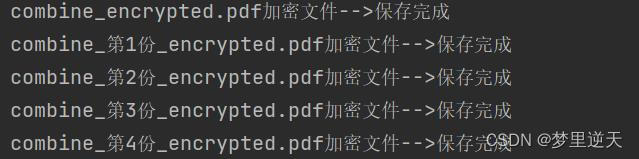
print(f'{output_name}加密文件-->保存完成')
效果:

4. 批量PDF添加水印
4.1 创建水印文件
安装reportlab模块
pip install reportlab
def createWatermark(content):
"""
创建水印
:param content: 水印内容
:return:
"""
filename = 'watermark.pdf' # 水印文件的文件名
can = canvas.Canvas(filename=filename, pagesize=(30 * cm, 30 * cm)) # 设置水印文件的页面大小
can.translate(5 * cm, 0 * cm) # 设置页面的坐标原点
# 注册水印文件需要使用的字体
reportlab.pdfbase.ttfonts.pdfmetrics.registerFont(
reportlab.pdfbase.ttfonts.TTFont(name='华文行楷', filename=r'C:\Windows\Fonts\STXINGKA.TTF'))
can.setFont(psfontname='华文行楷', size=25) # 设置水印字体即字号
can.rotate(28) # 设置水印旋转角度
can.setFillColorRGB(r=0.3, g=0.6, b=0.9) # 设置填充颜色
can.setFillAlpha(a=0.2) # 设置透明度
for i in range(0, 30, 5):
for j in range(0, 30, 5):
can.drawString(x=i * cm, y=j * cm, text=content) # 绘制6行x6列的水印文字
can.save() # 保存水印
return filename
4.2 添加水印
def addWatermark(pdf_file_input, pdf_file_mark, pdf_file_output):
"""
添加水印
:param pdf_file_input: 需要添加水印的文件
:param pdf_file_mark: 水印文件
:param pdf_file_output: 输出文件
:return:
"""
input_file = PdfFileReader(pdf_file_input)
output_file = PdfFileWriter() # 创建PdfFileWriter对象
page_count = len(input_file.pages) # 获得PDF文件页数
water_mark = PdfFileReader(pdf_file_mark) # 读取水印PDF文件
for pageNum in range(page_count):
page = input_file.pages[pageNum]
page.merge_page(water_mark.pages[0]) # 将两张PDF合并成1张
output_file.add_page(page) # 将页面添加到PDF文件
with open(pdf_file_output, 'wb') as pf:
output_file.write(pf)
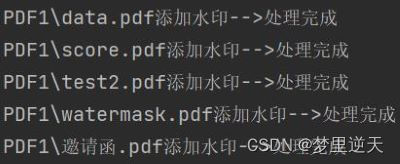
print(f'{pdf_file_input}添加水印-->处理完成')
完整代码
# author:mlnt
# createdate:2022/8/25
from pathlib import Path
from PyPDF2 import PdfFileReader, PdfFileWriter
from reportlab.lib.units import cm
from reportlab.pdfgen import canvas
import reportlab.pdfbase.ttfonts
def createWatermark(content):
"""
创建水印
:param content: 水印内容
:return:
"""
filename = 'watermark.pdf' # 水印文件的文件名
can = canvas.Canvas(filename=filename, pagesize=(30 * cm, 30 * cm)) # 设置水印文件的页面大小
can.translate(5 * cm, 0 * cm) # 设置页面的坐标原点
# 注册水印文件需要使用的字体
reportlab.pdfbase.ttfonts.pdfmetrics.registerFont(
reportlab.pdfbase.ttfonts.TTFont(name='华文行楷', filename=r'C:\Windows\Fonts\STXINGKA.TTF'))
can.setFont(psfontname='华文行楷', size=25) # 设置水印字体即字号
can.rotate(28) # 设置水印旋转角度
can.setFillColorRGB(r=0.3, g=0.6, b=0.9) # 设置填充颜色
can.setFillAlpha(a=0.2) # 设置透明度
for i in range(0, 30, 5):
for j in range(0, 30, 5):
can.drawString(x=i * cm, y=j * cm, text=content) # 绘制6行x6列的水印文字
can.save() # 保存水印
return filename
def addWatermark(pdf_file_input, pdf_file_mark, pdf_file_output):
"""
添加水印
:param pdf_file_input: 需要添加水印的文件
:param pdf_file_mark: 水印文件
:param pdf_file_output: 输出文件
:return:
"""
input_file = PdfFileReader(pdf_file_input)
output_file = PdfFileWriter() # 创建PdfFileWriter对象
page_count = len(input_file.pages) # 获得PDF文件页数
water_mark = PdfFileReader(pdf_file_mark) # 读取水印PDF文件
for pageNum in range(page_count):
page = input_file.pages[pageNum]
page.merge_page(water_mark.pages[0]) # 将两张PDF合并成1张
output_file.add_page(page) # 将页面添加到PDF文件
with open(pdf_file_output, 'wb') as pf:
output_file.write(pf)
print(f'{pdf_file_input}添加水印-->处理完成')
if __name__ == '__main__':
# 创建Path对象
src_folder = Path('PDF1')
output_folder = Path('PDF_mark')
# 判断输出目录是否存在
if not output_folder.exists():
# 不存在则创建
output_folder.mkdir(parents=True)
file_list = list(src_folder.glob('*.pdf')) # 获得给定目录下的所有pdf文件的路径
for file in file_list:
pdf_file_in = str(file) # 输入文件路径
# 创建水印
pdf_file_mark = createWatermark('绝密文件')
# 输出文件名
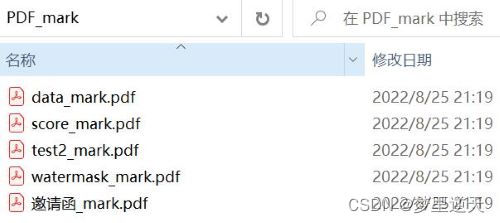
output_name = f'{file.stem}_mark.pdf'
pdf_file_out = str(output_folder / output_name) # 输出文件的路径
addWatermark(pdf_file_in, pdf_file_mark, pdf_file_out) # 添加水印
效果:


以上就是Python实现自动化处理PDF文件的方法详解的详细内容,更多关于Python自动化处理PDF的资料请关注脚本之家其它相关文章!