
最新MySql8.27主从复制及SpringBoot项目中的读写分离实战教程
作者:小钟要学习!!!
最新MySql8.27主从复制以及SpringBoot项目中的读写分离实战
1、MySql主从复制
MySQL主从复制是一个异步的复制过程,底层是基于MySQL1数据库自带的二进制日志功能。就是一台或多台MySQL数据库(slave,即从库)从另一台ySQL数据库(master,即主库)进行日志的复制然后再解析日志并应用到自身,最终实现从库的数据和主库的数据保持一致。SQL主从复制是MySQL数据库自带功能,无需借助第三方工具。
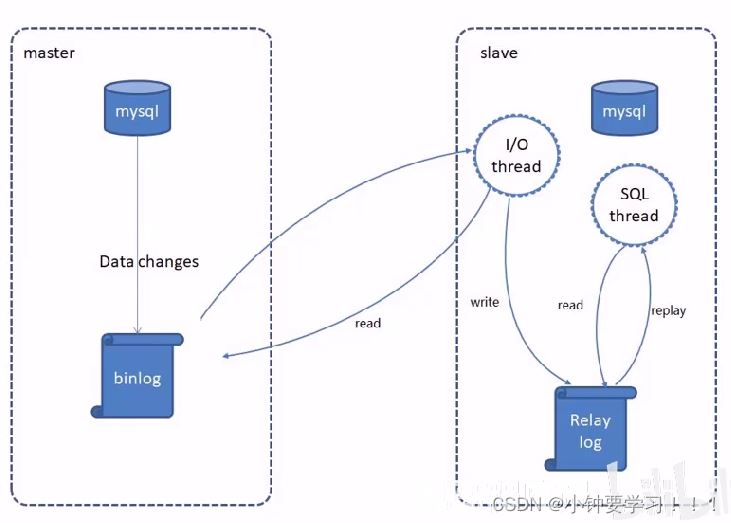
MySQL复制过程分成三步:
1、master将改变记录到二进制日志(binary log)
2、slave:将master的binary log拷贝到它的中继日志(relay log)
3、slave重做中继日志中的事件,将改变应用到自己的数据库中
说明:下面的配置需要准备两台服务器并且都要安装有MySQL数据库,同时安装数据库的方式不同修改配置文件的位置也不同,需要更具自身电脑来查询
2、配置-主库Master
修改MySql数据库的配置文件/etc/my.cnf,在配置日志文件中添加如下代码(不要第一行)
[mysqld] log-bin=mysql-bin # [必须]启用二进制日志 server-id=100 # [必须]服务器唯一ID
修改后重启MySql服务
登录MySQL执行下面的SQL语句
create user 'slave'@'%' IDENTIFIED WITH mysql_native_password BY '123456'; grant replication slave on *.* to 'slave'@'%';
注:上面SQL的作用是创建一个用户xiaoming,密码为Root@123456,并且给xiaoming用户授予REPLICATI0 N SLAVE
权限。常用于建立复制时所需要用到的用户权限,也就是slave必须被master授权具有该权限的用户,才能通过该用户复制。
登录MySQL数据库,执行下面的SQL,记录下结果中的File和Position的值
show master status
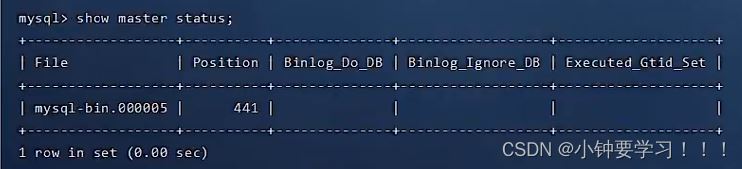
注意:上面的SQL的作用是查看Master状态,执行完此SQL后不要再执行任何操作
3、配置-从库Slave
修改MySQL数据库中的配置文件/etc/my.cnf
[mysqld] server-id=101 # [必须]服务器唯一ID
重启MySQL服务
systemctl restart mysql;
【重点】登录MySQL数据库,执行下面SQL语句(与配置主库最后查询的表格有关联)
change master to master_host='主库IP地址',master_user='slave',master_password='123456',master_log_file='mysql-bin.000001',master_log_pos=653; stop slave; start slave;
注意:
master_user:是在主库中创建的权限账户
master_password:是创建账户的密码
master_log_file:是创建主库最后执行的show master statusSQL语句查询出来的【文件名称】
master_log_pos:是文件的位置,与上一句查询同出一处
登录MySQL数据库,执行下面的SQL查看从数据库的状态
show slave status;

3、主从复制测试
1、在主数据库下创建一个新的数据库,然后在从库中刷新,如果出现主库设置的数据库那么就是成功了
4、读写分离案例
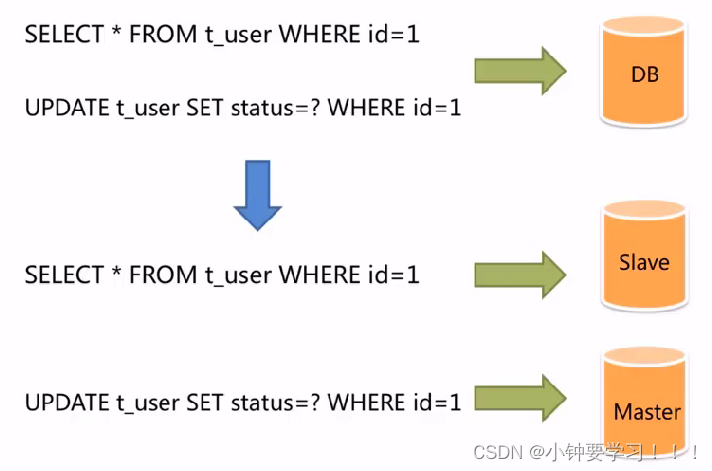
面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。对于同一时刻有大量并发读操作和较少写操作类型的
应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效
的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
4.1、Sharding-JDBC框架介绍
Sharding-JDBC定位为轻量级Java框架,在Java的DBC层提供的额外服务。它使用客户端直连数据库,以jar包形式
提供服务,无需额外部署和依赖,可理解为增强版的DBC驱动,完全兼容JDBC和各种ORM框架。
使用Sharding-JDBC可以在程序中轻松的实现数据库读写分离。
- 适用于任何基于JDBC的ORM框架,如:JPA,Hibernate,.Mybatis,Spring JDBC Template或直接使用DBC。
- 支持任何第三方的数据库连接池,如:DBCP,C3PO,BoneCP,Druid,HikariCP等。
- 支持任意实现DBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库
springboot项目中只需要导入核心依赖即可
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
案例要求需要完成上面的内容
在主库中设置一个数据库以及一个user字段,并填写上几个简单字段方便后面代码的测试

主库主要是用来完成增、删、改操作
从库主要是用来完成查询操作
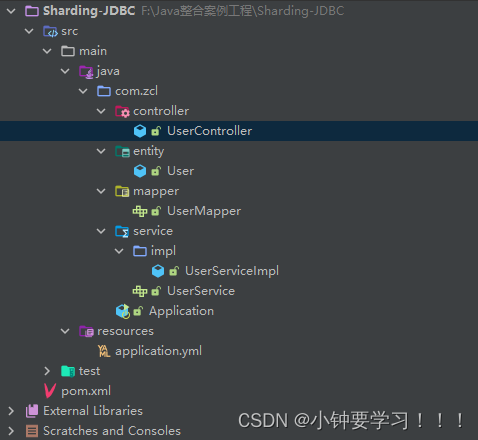
案例目录结构
基于MP快速开发,下面给出基本的控制器代码,在控制中进行二次开发
package com.zcl.controller;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.zcl.entity.User;
import com.zcl.service.UserService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import javax.sql.DataSource;
import java.util.List;
/**
* 项目名称:Sharding-JDBC
* 描述:控制器
*
* @author zhong
* @date 2022-08-06 20:36
*/
@Slf4j
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private DataSource dataSource;
@Autowired
private UserService userService;
/**
* 新增用户
* @param user
* @return
*/
@PostMapping
public User save(User user){
userService.save(user);
return user;
}
/**
* 根据id删除
* @param id
*/
@DeleteMapping("/{id}")
public void delete(@PathVariable("id") Long id){
userService.removeById(id);
}
/**
* 根据id修改用户
* @param user
* @return
*/
@PutMapping
public User update(User user){
userService.updateById(user);
return user;
}
/**
* 根据id查询用户
* @param id
* @return
*/
@GetMapping("/{id}")
public User getById(@PathVariable("id") Long id){
return userService.getById(id);
}
/**
* 条件查询
* @param user
* @return
*/
@GetMapping("/list")
public List<User> list(User user){
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(user.getId() != null,User::getId,user.getId());
queryWrapper.eq(user.getName() != null, User::getName,user.getName());
return userService.list(queryWrapper);
}
}注意:一定需要在pom文件中引入核心的依赖包,否则无法完成下面application.yml配置的工作
server:
port: 8080
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
map-underscore-to-camel-case: true
global-config:
db-config:
id-type: ASSIGN_ID
spring:
shardingsphere:
datasource:
names: master,slave
# 主数据源
master:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://192.168.26.131:3306/rw?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 1234
# 从数据源
slave:
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://192.168.26.131:13306/rw?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&useSSL=false&allowPublicKeyRetrieval=true
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 1234
masterslave:
# 读写分离设置【负载均衡策略】
load-balance-algorithm-type: round_robin
# 最终的数据源名称
name: dataSource
# 主数据源名称【与上面对应】
master-data-source-name: master
# 从数据源名称【与上面对应】
slave-data-source-names: slave
props:
sql:
show: true # 开启SQL显示,默认false
main:
allow-bean-definition-overriding: true # 允许bean覆盖
在配置项中设置允许bean定义覆盖配置项如果不进行设置就会出现启动项目报错,主要的原因是引两个jar包都会创建数据源对象,导致报错,开启bean配置覆盖就可以解决问题了
如果启动报错:url连接不上的,请查看mysql数据库的版本以及连接mysql的具体信息,8.0以上的版本与老版本的连接路径上需要添加很多的参数
启动控制台输出
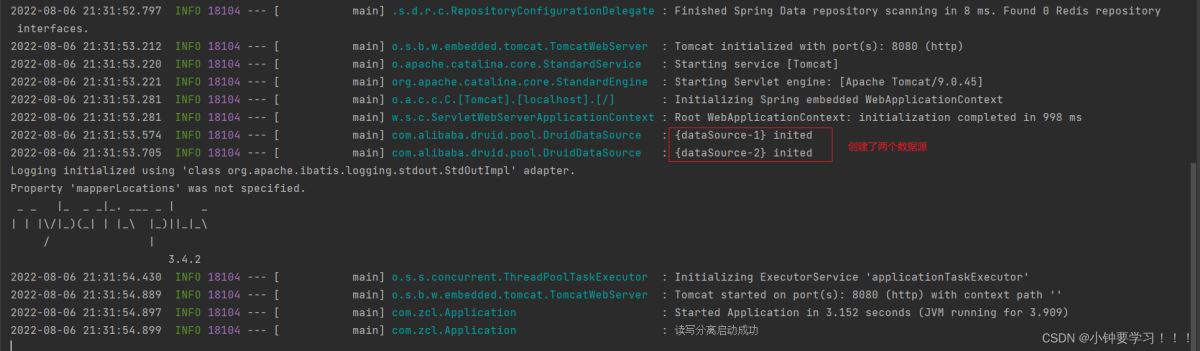
使用接口测试工具或插件来完成接口的调用测试是否使用哪一个数据源
我这里使用的是IDEA中的RestfulToolc插件
通过请求一个【查询】接口,然后断点查看一下,目前
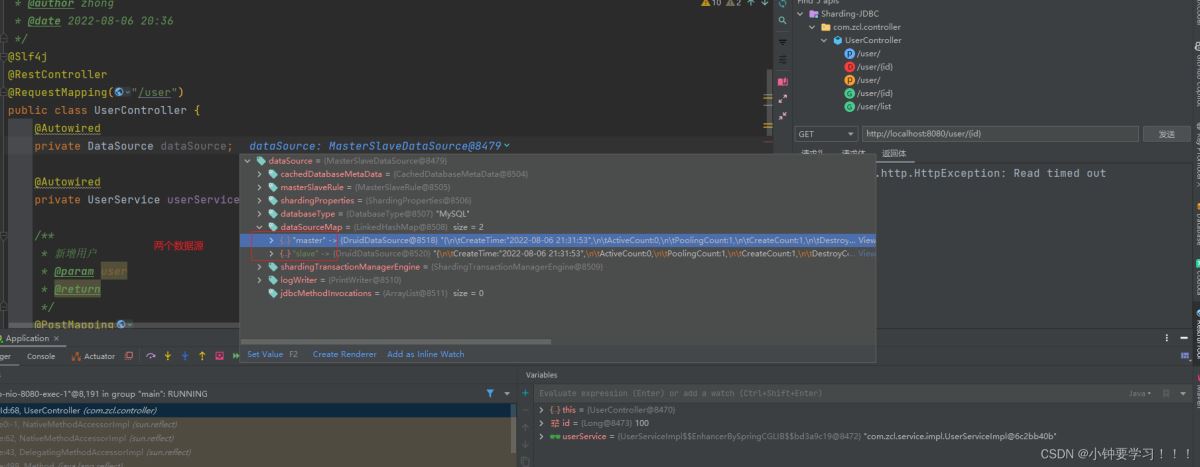
放行查看具体的数据
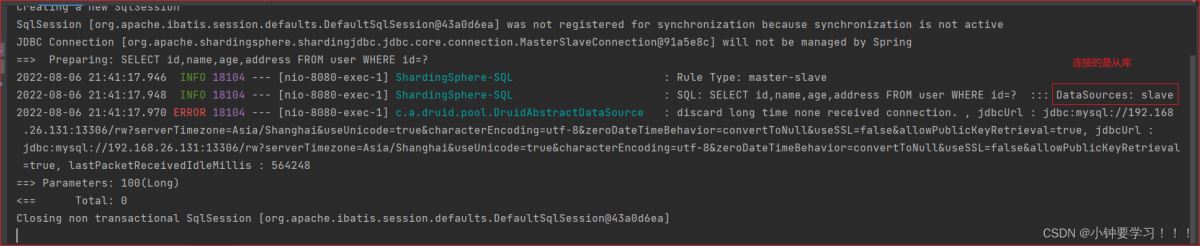
再次请求一个【添加或删除】完成主库操作
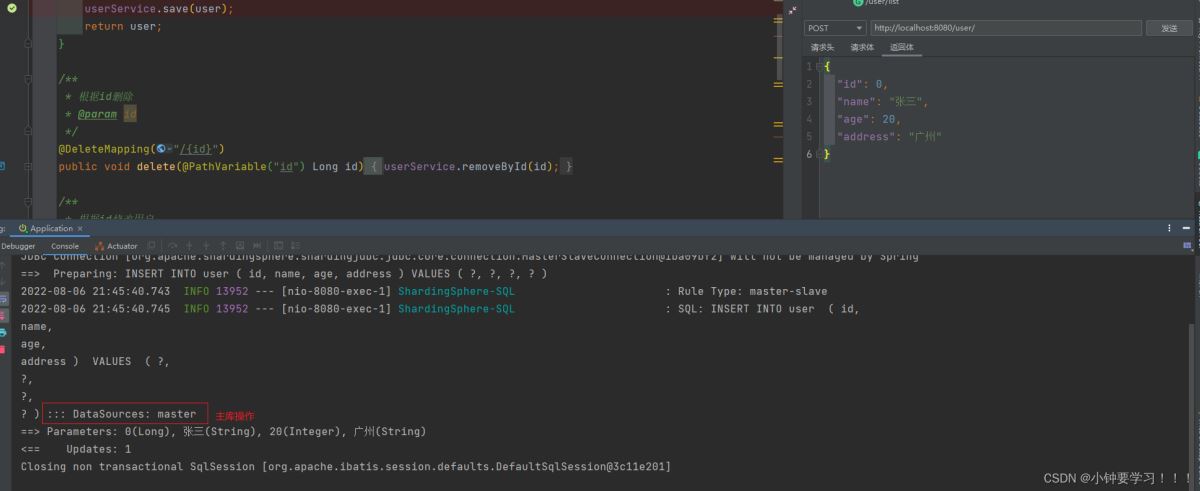
到此这篇关于最新MySql8.27主从复制及SpringBoot项目中的读写分离实战教程的文章就介绍到这了,更多相关MySql主从复制内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!