
关于Python文本生成的Beam Search解码问题
作者:deephub
这篇文章主要介绍了Python文本生成的Beam Search解码,本文给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下
贪婪搜索是在每个时间步中选择概率最高的单词,也是我们最常用的一种方法,Beam Search不取每个标记本身的绝对概率,而是考虑每个标记的所有可能扩展。然后根据其对数概率选择最合适的标记序列。
例如令牌的概率如下所示:
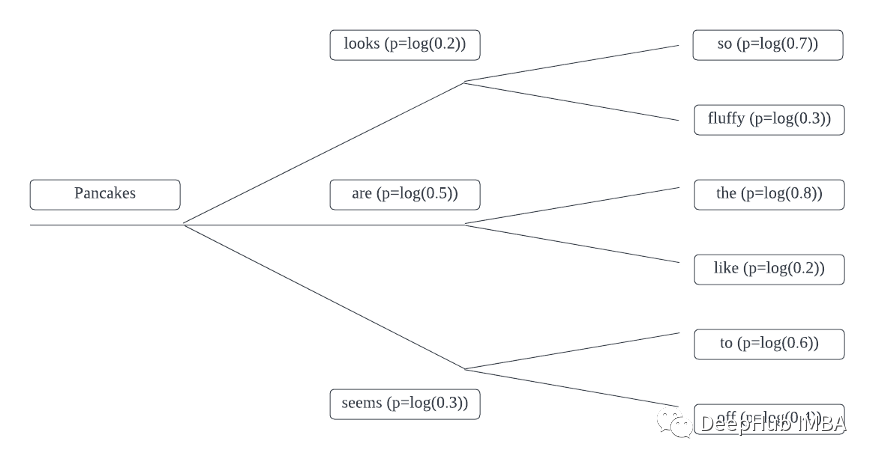
例如,Pancakes + looks时间段1的概率等效于:
Pancakes looks so = log(0.2) + log(0.7)= -1.9 Pancakes looks fluffy = log(0.2) + log(0.3)= -2.8
所以我们需要定义一个函数来完成整句的概率计算:
import torch.nn.functional as F
def log_probability_single(logits, labels):
logp = F.log_softmax(logits, dim=-1)
logp_label = torch.gather(logp, 2, labels.unsqueeze(2)).squeeze(-1)
return logp_label
def sentence_logprob(model, labels, input_len=0):
with torch.no_grad():
result = model(labels)
log_probability = log_probability_single(result.logits[:, :-1, :],
labels[:, 1:])
sentence_log_prob = torch.sum(log_probability[:, input_len:])
return sentence_log_prob.cpu().numpy()接下来,可以将其应用于贪婪搜索解码方法生成的输出,并计算生成的序列的对数概率。
在此示例中,我将在村上春木的书中简要介绍:1Q84。
input_sentence = "A love story, a mystery, a fantasy, a novel of self-discovery, a dystopia to rival George Orwell's — 1Q84 is Haruki Murakami's most ambitious undertaking yet: an instant best seller in his native Japan, and a tremendous feat of imagination from one of our most revered contemporary writers."
max_sequence = 100
input_ids = tokenizer(input_sentence,
return_tensors='pt')['input_ids'].to(device)
output = model.generate(input_ids, max_length=max_sequence, do_sample=False)
greedy_search_output = sentence_logprob(model,
output,
input_len=len(input_ids[0]))
print(tokenizer.decode(output[0]))我们可以看到生成的序列的对数概率为-52.31。

现在,我们将并比较通过Beam Search生成的序列的对数概率得分,得分越高潜在结果越好。
我们可以增加n-gram惩罚参数no_repeat_ngram_size,这有助于减少输出中的重复生成的序列。
beam_search_output = model.generate(input_ids,
max_length=max_sequence,
num_beams=5,
do_sample=False,
no_repeat_ngram_size=2)
beam_search_log_prob = sentence_logprob(model,
beam_search_output,
input_len=len(input_ids[0]))
print(tokenizer.decode(beam_search_output[0]))
print(f"\nlog_prob: {beam_search_log_prob:.2f}")输出如下:

分时和连贯性要比贪婪的方法好很多,对吧。
到此这篇关于Python文本生成的Beam Search解码的文章就介绍到这了,更多相关Python文本生成的Beam Search内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!