
VuePress使用Algolia实现全文搜索
作者:Gaby
引言
Algolia 为构建者提供构建世界级体验所需的搜索和推荐服务。Algolia 是一个数据库实时搜索服务,能够提供毫秒级的数据库搜索服务,并且其服务能以 API 的形式方便地布局到网页、客户端、APP 等多种场景。
VuePress 官方文档就有 Algolia 搜索插件,可以直接安装使用,使用 Algolia 搜索最大的好处就是方便,它会自动爬取网站的页面内容并构建索引,你只用申请一个 Algolia 授权服务,在网站上添加一些代码,就可以像添加统计代码一样,实现一个全文搜索功能了。
为了给网站再加点灵魂实现一个这样的全文搜索功能,刚好今天有空且申请的Algolia也已通过,官网已经将 AppID 等信息发邮件通知了,那说干就干吧,还得是撸起袖子加油干!
确认眼神
好不好用,那得上图,有图有真相,实实在在的效果出来了,坑还是有的但是帮大家走一下,避免了好些冤枉路,具体我也会在文中加以说明的。
先看导航图

再看搜索图

申请授权
已经确认过眼神👁了,那么这就是你要用的,那怎么用呢,不可能直接网上一搜代码一找就能用的,但凡商业的东西,多少还是会有些限制的。
第一步先申请授权,申请地址:docsearch

打开后填写网站地址、邮箱和仓库地址等信息,然后勾选上下面三项,并提交。之后就静待邮件,一般两三天就都会有回复的。
注意: 如果你没有注册过账号,这里官网会用这个邮箱帮你注册账号,且网站需要是公开可访问的 如果你网站不是他们要求的类型的,可以先搭建个文档类型的再进行申请。
如果申请通过,我们就会收到邮件,内容如下:
官方邮箱地址:support@algolia.com
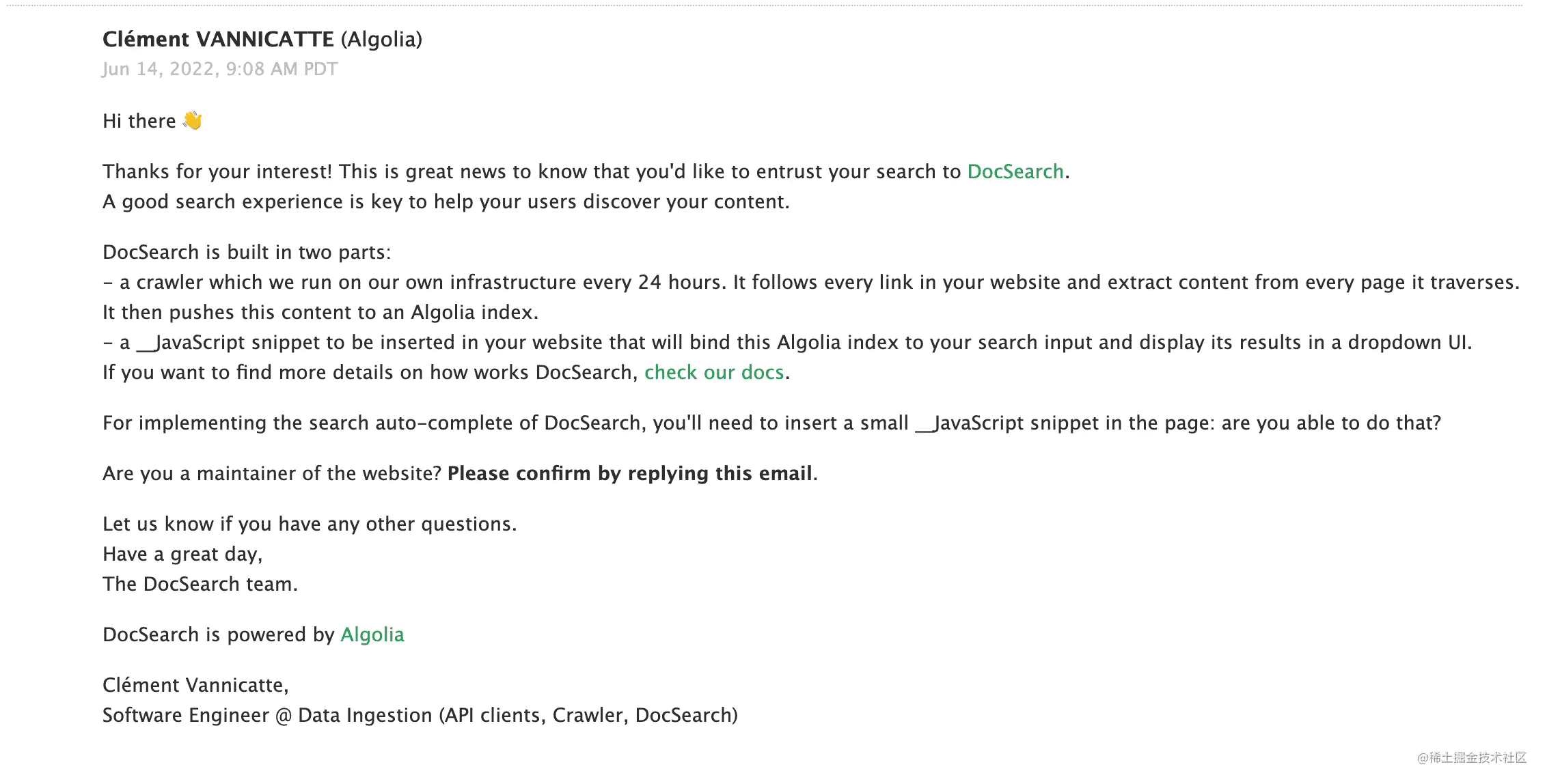
根据文中内容,回复确认你是站长网站的维护者并可以更改代码并简单说明要用 DocSearch 产品即可,之后就会得到官方发送的 AppID 等信息,内容如下:

通过 文中的邀请链接,就可以设置密码,然后用你的邮箱登录就可以了。algolia 登录页
实施部署
vuepress 官方有 docsearch 插件相关的文档,☞ 文档传送门,有文档不见得就能不踩坑的一次成功!有些东西还需要特别说明下的。
安装方法:
// 安装
npm i -D @vuepress/plugin-docsearch@next
// 配置 vuepress/docs/.vuepress/config.js
const { docsearchPlugin } = require('@vuepress/plugin-docsearch')
module.exports = {
plugins: [
docsearchPlugin({
// 配置项 配置上申请下来的 apiKey、indexName、appId
apiKey: '',
indexName: '',
appId: '',
placeholder: '搜索文档',
translations: {
button: {
buttonText: '搜索文档',
},
}
}),
],
}
注意:安装的插件版本,要同使用的 vuepress 版本保持一致,否则会报错不能用。尤其是早期创建的项目,现在直接按照文档安装最新版本的插件,就可能会存在问题。
就这么简单么,so easy !当你以为一切顺利万事大吉的时候,然而,很可能你的全文搜索还不可以用。可能一搜还都是找不到结果,那这是为何呢,文章还未结束,配置还在进行,且往下看!
调试爬取
如果你搜任何数据,都显示搜索不到数据,那很可能是爬取的数据有问题,我们登陆 www.algolia.com/ 打开管理后台,点击左侧选项栏里的 Search,查看对应的 index 数据,如果 Browse 这里没有显示数据,那说明爬取的数据可能有问题,导致没有生成对应的 Records:
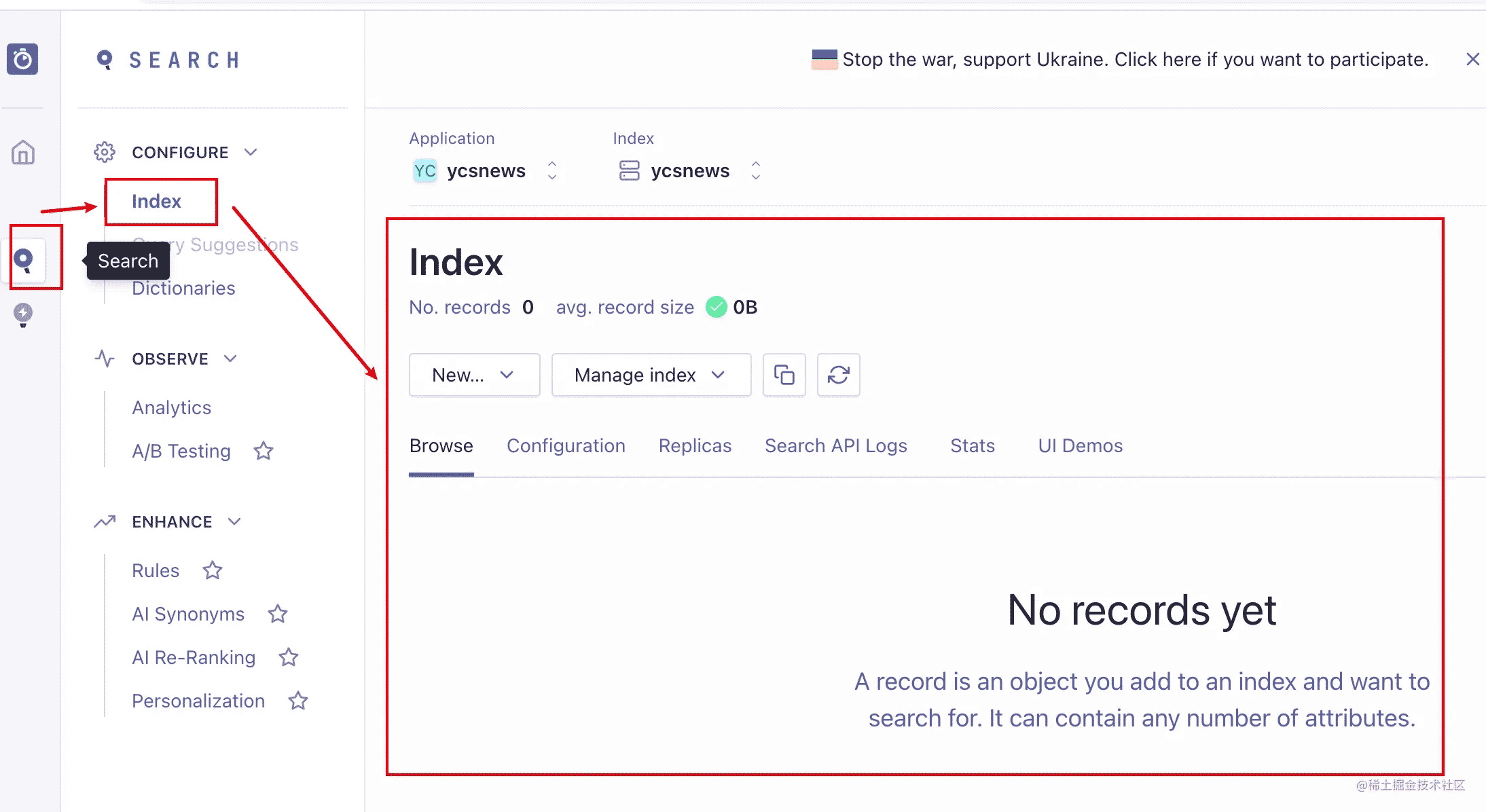
这个时候要使用官方工具进行调试,调试工具地址,打开调试台,打开 Overview 菜单。如果显示成功爬取,也有 Monitoring Success 的数据,但 Records 为 0,那大概是爬虫提取数据的逻辑有问题,点击左侧选项栏中的 Editor,查看具体的爬虫逻辑:

打开 Editor 菜单,可以看到调试爬虫代码的界面。这里可以根据 vuepress 官方提供的模版,看着调整。

vuepress 官方爬虫配置示例:
主要代码贴出来,具体详细的,大家直接转到 docsearch 插件文档

new Crawler({
rateLimit: 8,
// 这是 Algolia 开始抓取网站的初始地址
// 如果你的网站被分为数个独立部分,你可能需要在此设置多个入口链接
startUrls: ["https://docs.ycsnews.com/"],
renderJavaScript: false,
// 如果你在使用 Sitemap 插件 (如: vuepress-plugin-sitemap2),你可以提供 Sitemap 链接
sitemaps: ["https://docs.ycsnews.com/sitemap.xml"],
ignoreCanonicalTo: true,
// 这是 Algolia 抓取 URL 的范围 没有特殊要求就全站抓取
discoveryPatterns: ["https://docs.ycsnews.com/**"],
// 爬虫执行的计划时间,可根据文档更新频率设置
schedule: "at 11:50 every 1 day",
actions: [
{
// 使用适当的名称为索引命名 申请授权的时候就会有的
indexName: "ycsnews", // 默认会填好 不是自己的可以修改下
// 索引生效的路径
pathsToMatch: ["https://docs.ycsnews.com/**"],
// 控制 Algolia 如何抓取你的站点
recordExtractor: ({ helpers }) => {
return helpers.docsearch({
// Algolia 初次默认的可能都存在问题,所以这个还是根据 vuepress 官方提供的,或者自己审查元素查找匹配节点进行修改
recordProps: {
lvl1: ".theme-default-content h1",
content:
".theme-default-content .theme-default-content div .theme-default-content p .theme-default-content li",
lvl0: {
selectors: ".sidebar-heading.active",
defaultValue: "Documentation",
},
lvl2: ".theme-default-content h2",
lvl3: ".theme-default-content h3",
lvl4: ".theme-default-content h4",
lvl5: ".theme-default-content h5",
lvl6: ".theme-default-content h6",
lang: "",
tags: {
defaultValue: ["v1"],
},
},
indexHeadings: true,
aggregateContent: true,
});
},
},
],
// 下面的配置基本不用修改 大致看下即可
initialIndexSettings: {
ycsnews: {
attributesForFaceting: ["type", "lang", "language", "version"],
attributesToRetrieve: [
"hierarchy",
"content",
"anchor",
"url",
"url_without_anchor",
"type",
],
attributesToHighlight: ["hierarchy", "hierarchy_camel", "content"],
attributesToSnippet: ["content:10"],
camelCaseAttributes: ["hierarchy", "hierarchy_radio", "content"],
searchableAttributes: [
"unordered(hierarchy_radio_camel.lvl0)",
"unordered(hierarchy_radio.lvl0)",
"unordered(hierarchy_radio_camel.lvl1)",
"unordered(hierarchy_radio.lvl1)",
"unordered(hierarchy_radio_camel.lvl2)",
"unordered(hierarchy_radio.lvl2)",
"unordered(hierarchy_radio_camel.lvl3)",
"unordered(hierarchy_radio.lvl3)",
"unordered(hierarchy_radio_camel.lvl4)",
"unordered(hierarchy_radio.lvl4)",
"unordered(hierarchy_radio_camel.lvl5)",
"unordered(hierarchy_radio.lvl5)",
"unordered(hierarchy_radio_camel.lvl6)",
"unordered(hierarchy_radio.lvl6)",
"unordered(hierarchy_camel.lvl0)",
"unordered(hierarchy.lvl0)",
"unordered(hierarchy_camel.lvl1)",
"unordered(hierarchy.lvl1)",
"unordered(hierarchy_camel.lvl2)",
"unordered(hierarchy.lvl2)",
"unordered(hierarchy_camel.lvl3)",
"unordered(hierarchy.lvl3)",
"unordered(hierarchy_camel.lvl4)",
"unordered(hierarchy.lvl4)",
"unordered(hierarchy_camel.lvl5)",
"unordered(hierarchy.lvl5)",
"unordered(hierarchy_camel.lvl6)",
"unordered(hierarchy.lvl6)",
"content",
],
distinct: true,
attributeForDistinct: "url",
customRanking: [
"desc(weight.pageRank)",
"desc(weight.level)",
"asc(weight.position)",
],
ranking: [
"words",
"filters",
"typo",
"attribute",
"proximity",
"exact",
"custom",
],
highlightPreTag: '<span class="algolia-docsearch-suggestion--highlight">',
highlightPostTag: "</span>",
minWordSizefor1Typo: 3,
minWordSizefor2Typos: 7,
allowTyposOnNumericTokens: false,
minProximity: 1,
ignorePlurals: true,
advancedSyntax: true,
attributeCriteriaComputedByMinProximity: true,
removeWordsIfNoResults: "allOptional",
},
},
appId: "",// 默认会填好 不是自己的可以修改下
apiKey: "", // 默认会填好 不是自己的可以修改下
});
配置完成后,点击右上角的 save 进行保存在;然后找个文档的链接,测试下,看是否能成功,成功则进行下一步,否则继续调整抓取规则,指导能抓取成功!如下图,多测几个链接,保证都可用。

链接测试完成后,返回到 Overview 菜单, 点击右上角的 Restart crawling 按钮,进行抓取,成功后,下面的 Indices 栏会显示 Records 数,此时再去自己的网站试试,应该就可以了,如果不行,就重复执行下,再等一等再试!

等到看到类似这样的效果图,就可以了,至于其他高级的功能,就自行开发,好好利用吧!

总结回顾
对于 vuepress 来说,就是安装个插件配置参数的事,可还是让人耽误了好些时间。官方文档中并未对常见的一些问题予以说明,还需咱们自己踩坑,希望大家也能将自己日常踩的坑分享出来,避免更多的人,无休止的耗费精力。祝大家一切顺利,所踩之坑,皆能被填平!据说,点赞加关注的人都被领导加鸡腿了!😄
以上就是VuePress使用Algolia实现全文搜索的详细内容,更多关于VuePress Algolia全文搜索的资料请关注脚本之家其它相关文章!