
js自己实现一个大文件切片上传+断点续传的示例代码
作者:转转技术团队
PM:喂,那个切图仔,我这里有个100G的视频要上传,你帮我做一个上传后台,下班前给我哦,辛苦了。
我:。。。
相信每个切图工程师,都接触过文件上传的需求,一般的小文件,我们直接使用 input file,然后构造一个 new FormData()对象,扔给后端就可以了。如果使用了 Ant design 或者 element ui 之类的ui库,那更简单,直接调用一下api即可。当然了,复杂一些的,市面上也有不少优秀的第三方插件,比如WebUploader。但是作为一个有追求的工程师,怎么能仅仅满足于使用插件呢,今天我们就来自己实现一个。
首先我们来分析一下需求
一个上传组件,需要具备的功能:
- 需要校验文件格式
- 可以上传任何文件,包括超大的视频文件(切片)
- 上传期间断网后,再次联网可以继续上传(断点续传)
- 要有进度条提示
- 已经上传过同一个文件后,直接上传完成(秒传)
前后端分工:
前端:
- 文件格式校验
- 文件切片、md5计算
- 发起检查请求,把当前文件的hash发送给服务端,检查是否有相同hash的文件
- 上传进度计算
- 上传完成后通知后端合并切片
后端:
- 检查接收到的hash是否有相同的文件,并通知前端当前hash是否有未完成的上传
- 接收切片
- 合并所有切片
架构图如下
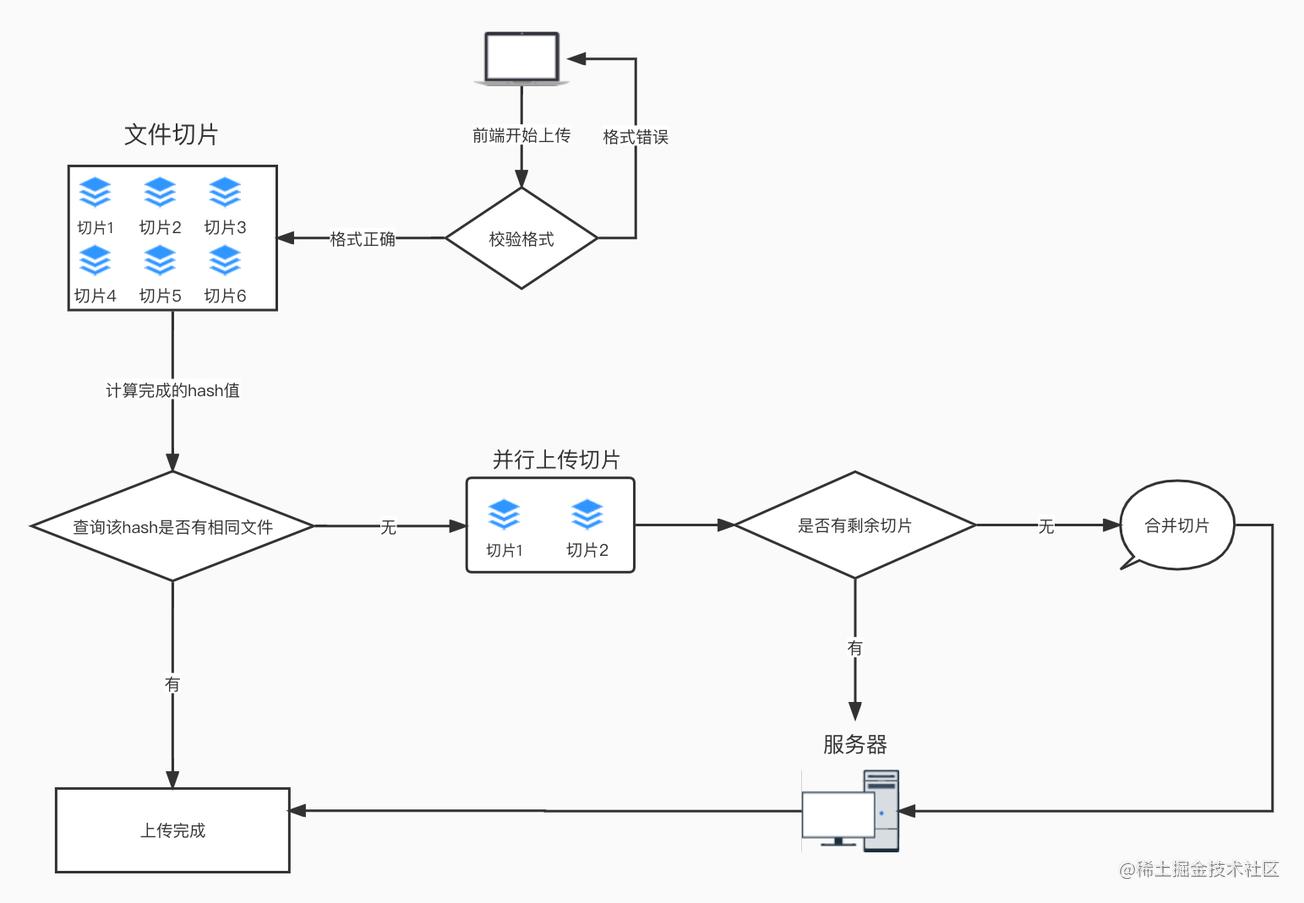
接下来开始具体实现
一、 格式校验
对于上传的文件,一般来说,我们要校验其格式,仅需要获取文件的后缀(扩展名),即可判断其是否符合我们的上传限制:
//文件路径
var filePath = "file://upload/test.png";
//获取最后一个.的位置
var index= filePath.lastIndexOf(".");
//获取后缀
var ext = filePath.substr(index+1);
//输出结果
console.log(ext);
// 输出: png但是,这种方式有个弊端,那就是我们可以随便篡改文件的后缀名,比如:test.mp4 ,我们可以通过修改其后缀名:test.mp4 -> test.png ,这样即可绕过限制进行上传。那有没有更严格的限制方式呢?当然是有的。
那就是通过查看文件的二进制数据来识别其真实的文件类型,因为计算机识别文件类型时,并不是真的通过文件的后缀名来识别的,而是通过 “魔数”(Magic Number)来区分,对于某一些类型的文件,起始的几个字节内容都是固定的,根据这几个字节的内容就可以判断文件的类型。借助十六进制编辑器,可以查看一下图片的二进制数据,我们还是以test.png为例:
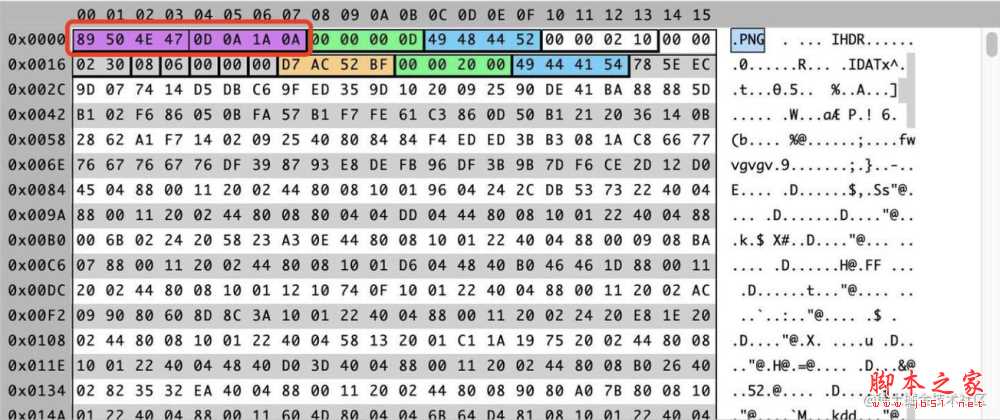
由上图可知,PNG 类型的图片前 8 个字节是 0x89 50 4E 47 0D 0A 1A 0A。基于这个结果,我们可以据此来做文件的格式校验,以vue项目为例:
<template>
<div>
<input
type="file"
id="inputFile"
@change="handleChange"
/>
</div>
</template>
<script>
export default {
name: "HelloWorld",
methods: {
check(headers) {
return (buffers, options = { offset: 0 }) =>
headers.every(
(header, index) => header === buffers[options.offset + index]
);
},
async handleChange(event) {
const file = event.target.files[0];
// 以PNG为例,只需要获取前8个字节,即可识别其类型
const buffers = await this.readBuffer(file, 0, 8);
const uint8Array = new Uint8Array(buffers);
const isPNG = this.check([0x89, 0x50, 0x4e, 0x47, 0x0d, 0x0a, 0x1a, 0x0a]);
// 上传test.png后,打印结果为true
console.log(isPNG(uint8Array))
},
readBuffer(file, start = 0, end = 2) {
// 获取文件的二进制数据,因为我们只需要校验前几个字节即可,所以并不需要获取整个文件的数据
return new Promise((resolve, reject) => {
const reader = new FileReader();
reader.onload = () => {
resolve(reader.result);
};
reader.onerror = reject;
reader.readAsArrayBuffer(file.slice(start, end));
});
}
}
};
</script>以上为校验文件类型的方法,对于其他类型的文件,比如mp4,xsl等,大家感兴趣的话,也可以通过工具查看其二进制数据,以此来做格式校验。
以下为汇总的一些文件的二进制标识:
1.JPEG/JPG - 文件头标识 (2 bytes): ff, d8 文件结束标识 (2 bytes): ff, d9
2.TGA - 未压缩的前 5 字节 00 00 02 00 00 - RLE 压缩的前 5 字节 00 00 10 00 00
3.PNG - 文件头标识 (8 bytes) 89 50 4E 47 0D 0A 1A 0A
4.GIF - 文件头标识 (6 bytes) 47 49 46 38 39(37) 61
5.BMP - 文件头标识 (2 bytes) 42 4D B M
6.PCX - 文件头标识 (1 bytes) 0A
7.TIFF - 文件头标识 (2 bytes) 4D 4D 或 49 49
8.ICO - 文件头标识 (8 bytes) 00 00 01 00 01 00 20 20
9.CUR - 文件头标识 (8 bytes) 00 00 02 00 01 00 20 20
10.IFF - 文件头标识 (4 bytes) 46 4F 52 4D
11.ANI - 文件头标识 (4 bytes) 52 49 46 46
二、 文件切片
假设我们要把一个1G的视频,分割为每块1MB的切片,可定义 DefualtChunkSize = 1 * 1024 * 1024,通过 spark-md5来计算文件内容的hash值。那如何分割文件呢,使用文件对象File的方法File.prototype.slice即可。
需要注意的是,切割一个较大的文件,比如10G,那分割为1Mb大小的话,将会生成一万个切片,众所周知,js是单线程模型,如果这个计算过程在主线程中的话,那我们的页面必然会直接崩溃,这时,就该我们的 Web Worker 来上场了。
Web Worker 的作用,就是为 JavaScript 创造多线程环境,允许主线程创建 Worker 线程,将一些任务分配给后者运行。在主线程运行的同时,Worker 线程在后台运行,两者互不干扰。具体的作用,不了解的同学可以自行去学些一下。这里就不展开讲了。
以下为部分关键代码:
// upload.js
// 创建一个worker对象
const worker = new worker('worker.js')
// 向子线程发送消息,并传入文件对象和切片大小,开始计算分割切片
worker.postMessage(file, DefualtChunkSize)
// 子线程计算完成后,会将切片返回主线程
worker.onmessage = (chunks) => {
...
}子线程代码:
// worker.js
// 接收文件对象及切片大小
onmessage (file, DefualtChunkSize) => {
let blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice,
chunks = Math.ceil(file.size / DefualtChunkSize),
currentChunk = 0,
spark = new SparkMD5.ArrayBuffer(),
fileReader = new FileReader();
fileReader.onload = function (e) {
console.log('read chunk nr', currentChunk + 1, 'of');
const chunk = e.target.result;
spark.append(chunk);
currentChunk++;
if (currentChunk < chunks) {
loadNext();
} else {
let fileHash = spark.end();
console.info('finished computed hash', fileHash);
// 此处为重点,计算完成后,仍然通过postMessage通知主线程
postMessage({ fileHash, fileReader })
}
};
fileReader.onerror = function () {
console.warn('oops, something went wrong.');
};
function loadNext() {
let start = currentChunk * DefualtChunkSize,
end = ((start + DefualtChunkSize) >= file.size) ? file.size : start + DefualtChunkSize;
let chunk = blobSlice.call(file, start, end);
fileReader.readAsArrayBuffer(chunk);
}
loadNext();
}以上利用worker线程,我们即可得到计算后的切片,以及md5值。
三、 断点续传 + 秒传 + 上传进度
在拿到切片和md5后,我们首先去服务器查询一下,是否已经存在当前文件。
- 如果已存在,并且已经是上传成功的文件,则直接返回前端上传成功,即可实现"秒传"。
- 如果已存在,并且有一部分切片上传失败,则返回给前端已经上传成功的切片name,前端拿到后,根据返回的切片,计算出未上传成功的剩余切片,然后把剩余的切片继续上传,即可实现"断点续传"。
- 如果不存在,则开始上传,这里需要注意的是,在并发上传切片时,需要控制并发量,避免一次性上传过多切片,导致崩溃。
// 检查是否已存在相同文件
async function checkAndUploadChunk(chunkList, fileMd5Value) {
const requestList = []
// 如果不存在,则上传
for (let i = 0; i < chunkList; i++) {
requestList.push(upload({ chunkList[i], fileMd5Value, i }))
}
// 并发上传
if (requestList?.length) {
await Promise.all(requestList)
}
}
// 上传chunk
function upload({ chunkList, chunk, fileMd5Value, i }) {
current = 0
let form = new FormData()
form.append("data", chunk) //切片流
form.append("total", chunkList.length) //总片数
form.append("index", i) //当前是第几片
form.append("fileMd5Value", fileMd5Value)
return axios({
method: 'post',
url: BaseUrl + "/upload",
data: form
}).then(({ data }) => {
if (data.stat) {
current = current + 1
// 获取到上传的进度
const uploadPercent = Math.ceil((current / chunkList.length) * 100)
}
})
}所有切片上传完成后,再向后端发送一个上传完成的请求,即通知后端把所有切片进行合并,最终完成整个上传流程。
大功告成!由于篇幅有限,本文主要讲了前端的实现思路,最终落地成完整的项目,还是需要大家根据真实的项目需求来实现。
到此这篇关于js自己实现一个大文件切片上传+断点续传的示例代码的文章就介绍到这了,更多相关js大文件切片上传+断点续传内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!