
PyTorch详解经典网络ResNet实现流程
作者:峡谷的小鱼
简述
GoogleNet 和 VGG 等网络证明了,更深度的网络可以抽象出表达能力更强的特征,进而获得更强的分类能力。在深度网络中,随之网络深度的增加,每层输出的特征图分辨率主要是高和宽越来越小,而深度逐渐增加。
深度的增加理论上能够提升网络的表达能力,但是对于优化来说就会产生梯度消失的问题。在深度网络中,反向传播时,梯度从输出端向数据端逐层传播,传播过程中,梯度的累乘使得近数据段接近0值,使得网络的训练失效。
为了解决梯度消失问题,可以在网络中加入BatchNorm,激活函数换成ReLU,一定程度缓解了梯度消失问题。
深度增加的另一个问题就是网络的退化(Degradation of deep network)问题。即,在现有网络的基础上,增加网络的深度,理论上,只有训练到最佳情况,新网络的性能应该不会低于浅层的网络。因为,只要将新增加的层学习成恒等映射(identity mapping)就可以。换句话说,浅网络的解空间是深的网络的解空间的子集。但是由于Degradation问题,更深的网络并不一定好于浅层网络。
Residual模块的想法就是认为的让网络实现这种恒等映射。如图,残差结构在两层卷积的基础上,并行添加了一个分支,将输入直接加到最后的ReLU激活函数之前,如果两层卷积改变大量输入的分辨率和通道数,为了能够相加,可以在添加的分支上使用1x1卷积来匹配尺寸。
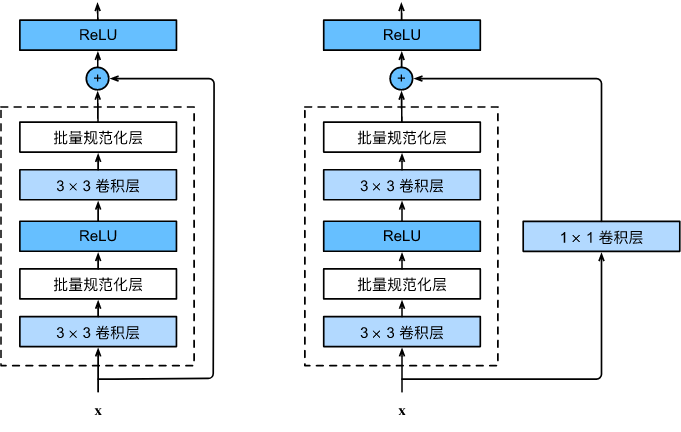
残差结构
ResNet网络有两种残差块,一种是两个3x3卷积,一种是1x1,3x3,1x1三个卷积网络串联成残差模块。
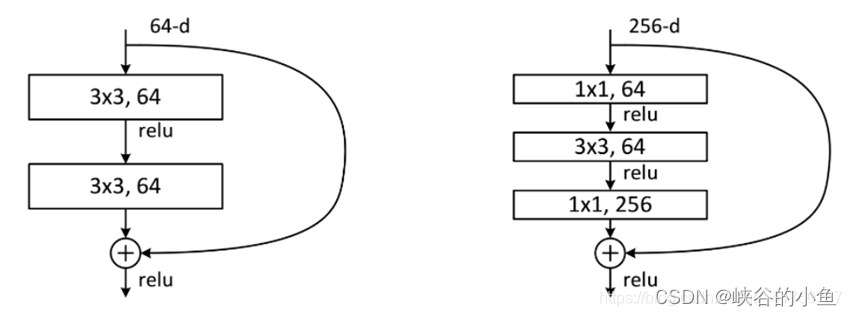
PyTorch 实现:
class Residual_1(nn.Module):
r"""
18-layer, 34-layer 残差块
1. 使用了类似VGG的3×3卷积层设计;
2. 首先使用两个相同输出通道数的3×3卷积层,后接一个批量规范化和ReLU激活函数;
3. 加入跨过卷积层的通路,加到最后的ReLU激活函数前;
4. 如果要匹配卷积后的输出的尺寸和通道数,可以在加入的跨通路上使用1×1卷积;
"""
def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):
r"""
parameters:
input_channels: 输入的通道上数
num_channels: 输出的通道数
use_1x1conv: 是否需要使用1x1卷积控制尺寸
stride: 第一个卷积的步长
"""
super().__init__()
# 3×3卷积,strides控制分辨率是否缩小
self.conv1 = nn.Conv2d(input_channels,
num_channels,
kernel_size=3,
padding=1,
stride=strides)
# 3×3卷积,不改变分辨率
self.conv2 = nn.Conv2d(num_channels,
num_channels,
kernel_size=3,
padding=1)
# 使用 1x1 卷积变换输入的分辨率和通道
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels,
num_channels,
kernel_size=1,
stride=strides)
else:
self.conv3 = None
# 批量规范化层
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
# print(X.shape)
Y += X
return F.relu(Y)class Residual_2(nn.Module):
r"""
50-layer, 101-layer, 152-layer 残差块
1. 首先使用1x1卷积,ReLU激活函数;
2. 然后用3×3卷积层,在接一个批量规范化,ReLU激活函数;
3. 再接1x1卷积层;
4. 加入跨过卷积层的通路,加到最后的ReLU激活函数前;
5. 如果要匹配卷积后的输出的尺寸和通道数,可以在加入的跨通路上使用1×1卷积;
"""
def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):
r"""
parameters:
input_channels: 输入的通道上数
num_channels: 输出的通道数
use_1x1conv: 是否需要使用1x1卷积控制尺寸
stride: 第一个卷积的步长
"""
super().__init__()
# 1×1卷积,strides控制分辨率是否缩小
self.conv1 = nn.Conv2d(input_channels,
num_channels,
kernel_size=1,
padding=1,
stride=strides)
# 3×3卷积,不改变分辨率
self.conv2 = nn.Conv2d(num_channels,
num_channels,
kernel_size=3,
padding=1)
# 1×1卷积,strides控制分辨率是否缩小
self.conv3 = nn.Conv2d(input_channels,
num_channels,
kernel_size=1,
padding=1)
# 使用 1x1 卷积变换输入的分辨率和通道
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels,
num_channels,
kernel_size=1,
stride=strides)
else:
self.conv3 = None
# 批量规范化层
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = F.relu(self.bn2(self.conv2(Y)))
Y = self.conv3(Y)
if self.conv3:
X = self.conv3(X)
# print(X.shape)
Y += X
return F.relu(Y)ResNet有不同的网络层数,比较常用的是50-layer,101-layer,152-layer。他们都是由上述的残差模块堆叠在一起实现的。
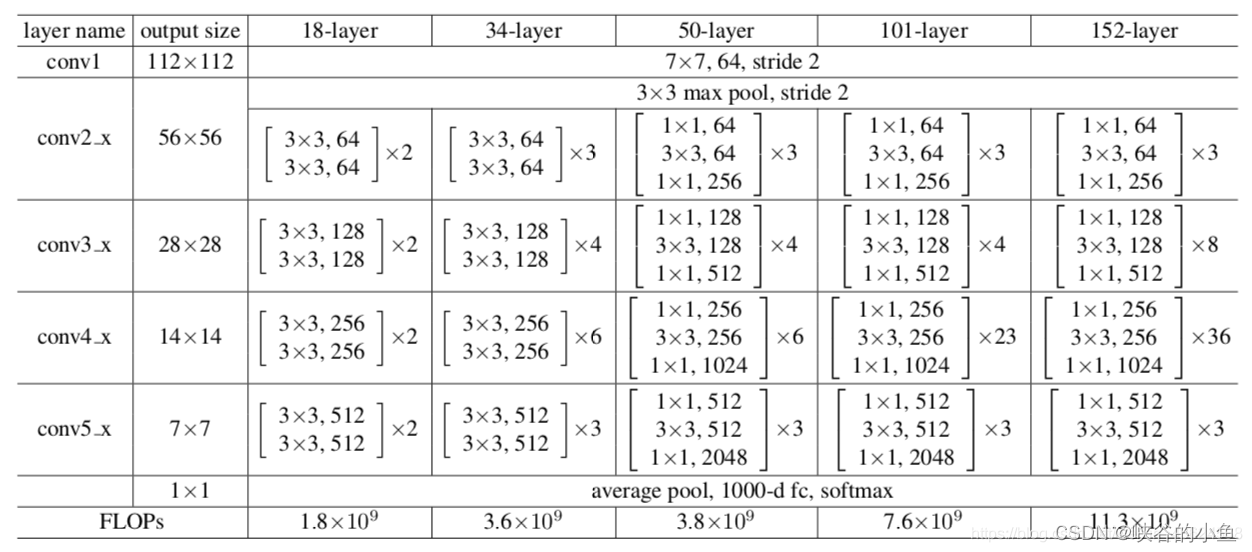
以18-layer为例,层数是指:首先,conv_1 的一层7x7卷积,然后conv_2~conv_5四个模块,每个模块两个残差块,每个残差块有两层的3x3卷积组成,共4×2×2=16层,最后是一层分类层(fc),加总一起共1+16+1=18层。
18-layer 实现
首先定义由残差结构组成的模块:
# ResNet模块
def resnet_block(input_channels, num_channels, num_residuals, first_block=False):
r"""残差块组成的模块"""
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual_1(input_channels,
num_channels,
use_1x1conv=True,
strides=2))
else:
blk.append(Residual_1(num_channels, num_channels))
return blk定义18-layer的最开始的层:
# ResNet的前两层:
# 1. 输出通道数64, 步幅为2的7x7卷积层
# 2. 步幅为2的3x3最大汇聚层
conv_1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))定义残差组模块:
# ResNet模块 conv_2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True)) conv_3 = nn.Sequential(*resnet_block(64, 128, 2)) conv_4 = nn.Sequential(*resnet_block(128, 256, 2)) conv_5 = nn.Sequential(*resnet_block(256, 512, 2))
ResNet 18-layer模型:
net = nn.Sequential(conv_1, conv_2, conv_3, conv_4, conv_5,
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(512, 10))
# 观察模型各层的输出尺寸
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)输出:
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 128, 28, 28])
Sequential output shape: torch.Size([1, 256, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1])
Flatten output shape: torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])
在数据集训练
def load_datasets_Cifar10(batch_size, resize=None):
trans = [transforms.ToTensor()]
if resize:
transform = trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
train_data = torchvision.datasets.CIFAR10(root="../data", train=True, transform=trans, download=True)
test_data = torchvision.datasets.CIFAR10(root="../data", train=False, transform=trans, download=True)
print("Cifar10 下载完成...")
return (torch.utils.data.DataLoader(train_data, batch_size, shuffle=True),
torch.utils.data.DataLoader(test_data, batch_size, shuffle=False))
def load_datasets_FashionMNIST(batch_size, resize=None):
trans = [transforms.ToTensor()]
if resize:
transform = trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
train_data = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)
test_data = torchvision.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)
print("FashionMNIST 下载完成...")
return (torch.utils.data.DataLoader(train_data, batch_size, shuffle=True),
torch.utils.data.DataLoader(test_data, batch_size, shuffle=False))
def load_datasets(dataset, batch_size, resize):
if dataset == "Cifar10":
return load_datasets_Cifar10(batch_size, resize=resize)
else:
return load_datasets_FashionMNIST(batch_size, resize=resize)
train_iter, test_iter = load_datasets("", 128, 224) # Cifar10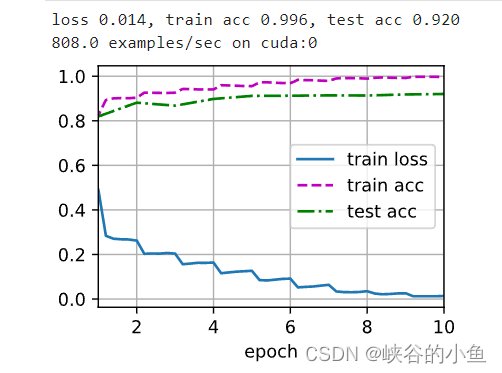
到此这篇关于PyTorch详解经典网络ResNet实现流程的文章就介绍到这了,更多相关PyTorch ResNet内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!