
深入解析opencv骨架提取的算法步骤
作者:追天一方
前言
个人感觉骨架提取提取的就是开运算过程的不可逆。
一.算法步骤
1.算法步骤
首先上一下比较官方的算法步骤:
1.获得原图像的首地址及图像的宽和高,并设置循环标志1
2.用结构元素腐蚀原图像,并保存腐蚀结果
3.设置循环标志为0,如果腐蚀结果中有一个点为255,即原图像尚未被完全腐蚀成空集,则将循环标志设为1.
4.用结构元素对腐蚀后的图像进行开运算(消除小的白色区域),并求取腐蚀运算与开运算的差(得到消除的白色区域)
5.用[4]中求得的结果与之前求得的骨架进行并集运算,以获得本次循环求得的骨架
6.把本次循环中保存的腐蚀结果赋值给原图像
7.重复步骤[2]-[6],直到将原图像腐蚀成空集为止。
最终求得的骨架就是结果。
2.分析
作者的理解是这样的:
输入:img(二值图)
输出:out(和img一样shape的图像,初始化是全0)
while img中有像素值为255(在这个循环里面,一直腐蚀我们的二值图,直到全部为黑色):
腐蚀img图像
对img开运算
img2=开运算前的图像减去开运算后的图像
out+=img2
输出out
首先说一下开运算,就是对图像先做腐蚀再做膨胀。上面一个核心点就是这一步(img2=开运算前的图像减去开运算后的图像),在这里为什么说个人感觉骨架提取提取的就是开运算过程的不可逆呢?我们对这个开运算过程分析一下:
1.假如开运算后的图像和开运算前的图像不一样,比如下面这张图片:
可以看到这张图片中白色的大部分都比较细小,我们对这张图片做开运算的时候,我们先腐蚀,很容易就让一部分的白色的部分消失掉,那么这个白色的部分消失掉之后对腐蚀后的图片做膨胀消失的白色部分是膨胀不回来的。这些消失的部分就是开运算过程中的不可逆的部分了。
然后我们在后面(img2=开运算前的图像减去开运算后的图像),这一步当中就是得到了开运算中消失的那些白色部分了,这一部分就是开运算过程中的不可逆的部分,然后将它叠加到out上。
然后我们通过对图像不断的腐蚀,开运算,得到了所有这些图像中在开运算中不可逆的部分,就得到了我们的骨架了。
2.假如开运算后的图像和开运算前的图像不一样,那这样的话我们在这一步(img2=开运算前的图像减去开运算后的图像)得到img2中的每一个元素就为0了,那在后面out+=img2这一步的时候就out相当于不变,进入下一步循环在继续把白色部分腐蚀地更小,直到得到开运算中出现了不可逆地部分再叠加到out上。
所以粗暴地来说,骨架提取就是对我们地前景区域,不断地腐蚀,细化前景,直到将前景压缩到细地不能再细了。我们的骨架提取提取的就是这一部分。
二.代码实现
1.预处理
这里我们的图片是以灰度图片方式读取进来的,然后需要阈值处理转换到二值图。
然后我们的图片可能会有一些其他的较大的噪声的影响,我们首先对图像先进行腐蚀操作,手动过滤掉一些滤波可能无法过滤的较大噪声。
'''
用于挑选一个好的二值图
'''
import cv2
import numpy as np
import os
def refine(img_path):
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
# thresh, img = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
thresh, img = cv2.threshold(img, 50, 255, cv2.THRESH_BINARY)
h, w = img.shape[0:2]
#前景背景反转
for i in range(h):
for j in range(w):
if img[i, j] == 255:
img[i, j] = 0
else:
img[i, j] = 255
cv2.namedWindow("binary", 0)
cv2.resizeWindow("binary", 640, 480)
cv2.imshow('binary', img)
dst = img.copy()
num_erode = 0
while (True):
if np.sum(dst) == 0:
break
kernel = cv2.getStructuringElement(cv2.MORPH_CROSS, (3, 3))
dst = cv2.erode(dst, kernel)
cv2.namedWindow("z", 0)
cv2.resizeWindow("z", 640, 480)
cv2.imshow('z', dst)
c = cv2.waitKey(0)
if c == ord("q"):
print("保存")
cv2.imwrite("./refine.png", dst)
break
num_erode = num_erode + 1
if __name__ == '__main__':
refine("input.png")
在这里需要注意的是我们对图像进行二值化可能会将我们的背景和前景反转,在这里我们需要反转回来。否则的话把反转的代码注释掉即可。
我的原图如下:

然后经过腐蚀的图片如下:

2. 骨架提取实现
然后下面就是骨架提取的代码了:
'''
骨架提取
'''
import cv2
import numpy as np
#由于我们经过之前的代码转换到了二值图,所以这里不需要转换
img = cv2.imread('refine.png', cv2.IMREAD_GRAYSCALE)
dst = img.copy()
skeleton = np.zeros(dst.shape, np.uint8)
while (True):
if np.sum(dst) == 0:
break
kernel = cv2.getStructuringElement(cv2.MORPH_CROSS, (7, 7))
dst = cv2.erode(dst, kernel, None, None, 1)
open_dst = cv2.morphologyEx(dst, cv2.MORPH_OPEN, kernel)
result = dst - open_dst
skeleton = skeleton + result
cv2.waitKey(1)
cv2.namedWindow("result",0)
cv2.resizeWindow("result",640,480)
cv2.imshow('result', skeleton)
cv2.imwrite("output.png",skeleton)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这里我们可以通过开运算的结果元大小来稍微调整一下提取的骨架粗细。
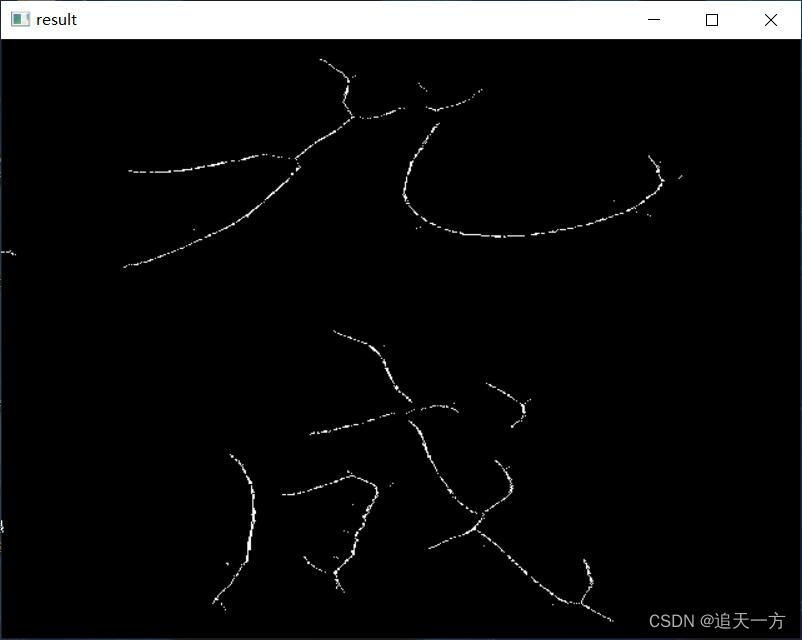
77开运算结构元提取的骨架如下:

55开运算结构元提取的骨架如下:
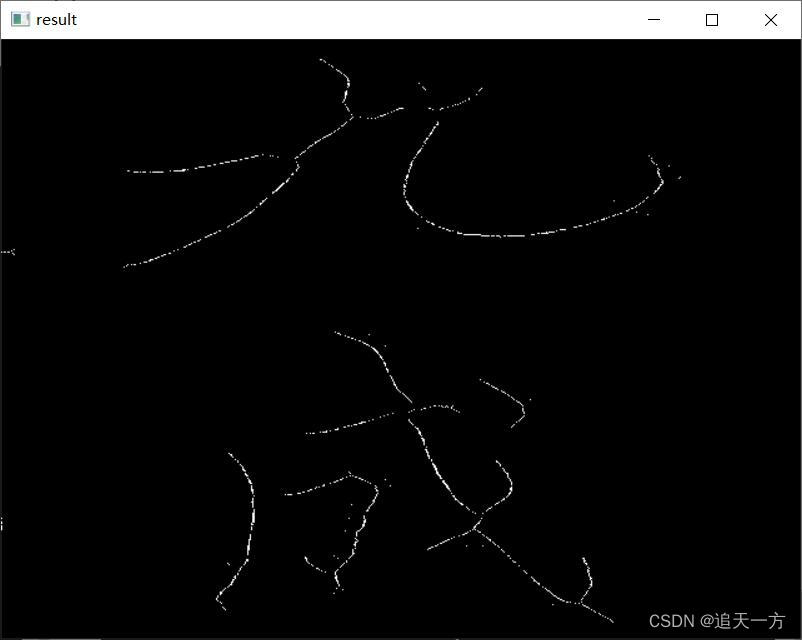
到此这篇关于深入解析opencv骨架提取的算法步骤的文章就介绍到这了,更多相关opencv骨架提取内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!