
Flask项目搭建及部署(最全教程)
作者:0世界和平0
flask搭建及部署
- pip 19.2.3
- python 3.7.5
- Flask 1.1.1
- Flask-SQLAlchemy 2.4.1
- Pika 1.1.0
- Redis 3.3.11
- flask-wtf 0.14.2
1、创建flask项目:

创建完成后整个项目结构树:

app.py: 项⽬管理⽂件,通过它管理项⽬。
static: 存放静态文件
templates文件夹:用于放置html模板文件
由于flask属于轻量级web框架, 更加自由、灵活,可扩展性强,第三方库的选择面广,开发时可以结合自己最喜欢用的轮子,也能结合最流行最强大的Python库 。所以这个框架的代码架构需要自己设计。
2、创建项目主要逻辑代码保存目录
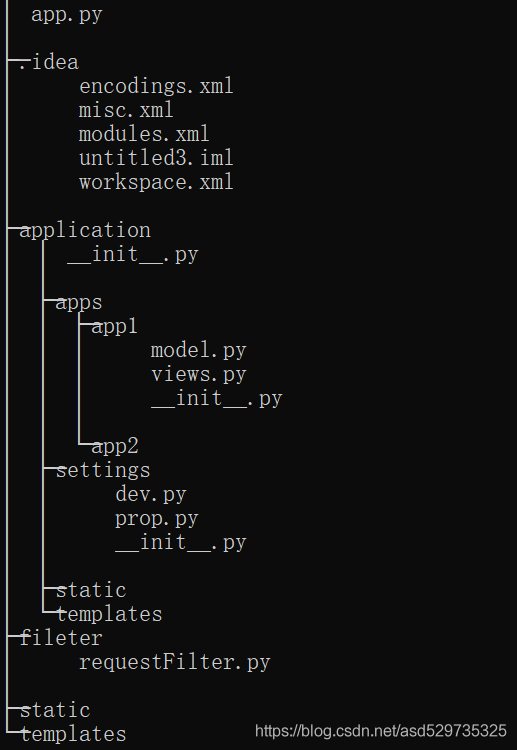
手动创建application目录、filter目录及其子目录
application : 项目主要逻辑代码保存目录
_init_.py : 创建flask应用并加载配置,如mysql,redis,rabbitmq,
apps : 专门用于保存每一个项目的蓝图
app1 : app1蓝图目录,在app1下的init_.py中文件中创建蓝图对象,view.py中新增对应的视图文件,在 model.py中写模型代码
settings : 项目配置存储目录
dev.py : 项目开发阶段配置文件
prop.py : 项目生成阶段配置文件
static : 项目静态文件夹(用于存放css一类的文件)
templates : 用于放置html模板文件
filter : 整个项目拦截器目录
requestFilter.py: 针对整个app项目全局路由拦截规则定义
app.py : 项⽬管理⽂件,通过它启动整个项目
2.1 配置mysql数据库,加载配置文件并针对整个app项目定义全局db
2.1.1 settings.py
#全局通用配置类
class Config(object):
"""项目配置核心类"""
#调试模式
DEBUG=False
# 配置日志
# LOG_LEVEL = "DEBUG"
LOG_LEVEL = "INFO"
# 配置redis
# 项目上线以后,这个地址就会被替换成真实IP地址,mysql也是
REDIS_HOST = 'your host'
REDIS_PORT = your port
REDIS_PASSWORD = 'your password'
REDIS_POLL = 10
#数据库连接格式
SQLALCHEMY_DATABASE_URI = "mysql+pymysql://user:password@localhost:3306/test?charset=utf8"
# 动态追踪修改设置,如未设置只会提示警告
SQLALCHEMY_TRACK_MODIFICATIONS = False
# 查询时会显示原始SQL语句
SQLALCHEMY_ECHO = False
# 数据库连接池的大小
SQLALCHEMY_POOL_SIZE=10
#指定数据库连接池的超时时间
SQLALCHEMY_POOL_TIMEOUT=10
# 控制在连接池达到最大值后可以创建的连接数。当这些额外的 连接回收到连接池后将会被断开和抛弃。
SQLALCHEMY_MAX_OVERFLOW=2
#rabbitmq参数配置
RABBITUSER="user"
RABBITPASSWORD="password"
RABBITHOST="your ip"
RABBITPORT=your port2.1.2 dev.py
from . import Config
class DevelopmentConfig(Config):
'开发模式下的配置'
# 查询时会显示原始SQL语句
SQLALCHEMY_ECHO = True2.1.3 prop.py
from . import Config
class ProductionConfig(Config):
"""生产模式下的配置"""
DEBUG = False2.1.4 加载配置文件,定义全局的db( SQLALchemy类的实例 )供项目使用
# 主应用的根目录
app = Flask(__name__)
config = {
'dev': DevelopmentConfig,
'prop': ProductionConfig,
}
# 设置配置类
Config = config['dev']
# 加载配置
app.config.from_object(Config)
# 创建数据库连接对象
db = SQLAlchemy(app)dev : 测试环境配置
prop: 生产环境配置
Flask应用app配置加载
通常三种方式
- 从配置对象中加载:app.config.from_object()
- 从配置文件中加载:app.config.from_pyfile()-ini文件
- 从环境变量中加载:app.config.from_envvar()
配置对象
从配置对象中加载,创建配置的类:
# 配置对象,里面定义需要给 APP 添加的一系列配置
class Config(object):
DEBUG = True
app = Flask(__name__)
# 从配置对象中加载配置
app.config.from_object(Config)
app.run()配置文件
从配置文件中加载,在目录中定义一个配置文件config.ini
app = Flask(__name__)
# 从配置对象中加载配置
app.config.from_pyfile("config.ini")
app.run()环境变量
app = Flask(__name__)
# 从环境变量中加载
app.config.from_envvar("FLASKCONFIG")
app.run()2.2 定义model模型,负责和数据库交互
app1.model
from application import db
class Wdtest(db.Model):
__tablename__ = "wdtest" #设置表名
id = db.Column(db.String(100), primary_key=True, comment="主键ID")
name = db.Column(db.String(20), index=True, comment="姓名" )
age = db.Column(db.Integer, default=True, comment="年龄")模型 表示程序使用的持久化实体. 在Flask-SQLALchemy 中, 模型一般是一个 Python 类, 类中的属性对应数据库中的表.
db.Model :创建模型,
db.Column : 创建模型属性.
tablename :指定表名
模型属性类型 :
| 类型名 | Python类型 | 说明 |
|---|---|---|
| Integer | int | 普通整数,一般是 32 位 |
| SmallInteger | int | 取值范围小的整数,一般是 16 位 |
| Big Integer | int 或 long | 不限制精度的整数 |
| Float | float | 浮点数 |
| Numeric | decimal.Decimal | 定点数 |
| String | str | 变长字符串 |
| Text | str | 变长字符串,对较长或不限长度的字符串做了优化 |
| Unicode | unicode | 变长 Unicode 字符串 |
| Unicode Text | unicode | 变长 Unicode 字符串,对较长或不限长度的字符串做了优化 |
| Boolean | bool | 布尔值 |
| Date | datetime.date | 日期 |
| Time | datetime.time | 时间 |
| DateTime | datetime.datetime | 日期和时间 |
| Interval | datetime.timedelta | 时间间隔 |
| Enum | str | 一组字符串 |
| PickleType | 任何 Python 对象 | 自动使用 Pickle 序列化 |
| LargeBinary | str | 二进制文件 |
常用 SQLAlchemy 列选项
| 选项名 | 说明 |
|---|---|
| primary_key | 如果设为 True,这列就是表的主键 |
| unique | 如果设为 True,这列不允许出现重复的值 |
| index | 如果设为 True,为这列创建索引,提升查询效率 |
| nullable | 如果设为 True,这列允许使用空值;如果设为 False,这列不允许使用空值 |
| default | 为这列定义默认值 |
2.3 声明蓝图
app1._init.py
#给app取别名为 'index'
index_blu=Blueprint('index',__name__,template_folder='templates',static_folder='static')
from .views import *template_folder:指定模板文件路径,查找顺序,先全局templates里面找,没找到,再往子蓝图里面找.
这里是把view中所有的视图都声明在index这个蓝图里面,接下来我们需要做的是将这个声明好的蓝图,注册进我们的项目中。
2.4 将声明好的蓝图注册进app中
application.init_:
from application.settings.dev import DevelopmentConfig
from application.settings.prop import ProductionConfig
# 主应用的根目录
app = Flask(__name__)
config = {
'dev': DevelopmentConfig,
'prop': ProductionConfig,
}
# 设置配置类
Config = config['dev']
# 加载配置
app.config.from_object(Config)
# 创建数据库连接对象
db = SQLAlchemy(app)
# todo 注册蓝图
from .apps.app1 import index_blu
app.register_blueprint(index_blu, url_prefix='/index')针对:app = Flask(name)解释
Flask类初始化参数
Flask类init方法部分代码
def __init__(
self,
import_name,
static_url_path=None,
static_folder="static",
static_host=None,
host_matching=False,
subdomain_matching=False,
template_folder="templates",
instance_path=None,
instance_relative_config=False,
root_path=None,
):passimport_name:Flask程序所在的包(模块),传 __name__
static_url_path:静态文件访问路径,可以不传,默认为:/ + static_folder
static_folder:静态文件存储的文件夹,可以不传,默认为 static
template_folder:模板文件存储的文件夹,可以不传,默认为 templates
3 通过以上的步骤后,我们可以基本操作数据库了:
以下所有示例代码,皆在view.py中去实现
3.1 增:
先写怎么增,然后增加,最后提交
student = Wdtest(id=ids , name=name, age=age)
try:
application.db.session.add(student)
application.db.session.commit()
except:
# 事務回滾
application.db.session.rollback()3.2 删:
先获取数据库中的这个数据,再删除它
user = Wdtest.query.first()
application.db.session.delete(user)
application.db.session.commit()3.3 改:
user = Wdtest.query.first()
user.name = name
try:
application.db.session.commit()
except:
# 事務回滾
application.db.session.rollback()3.4 查:
# 查询所有⽤户数据
user_list=Wdtest.query.all()
# 查询有多少个⽤户
user_list_num=Wdtest.query.count()
# 查询第1个⽤户
user=Wdtest.query.first()
# 查询id为3的⽤户[3种⽅式]
user=Wdtest.query.get(3) # 根据主键查询
user_list=Wdtest.query.filter_by(id=3).all() # 以关键字实参形式进行匹配字段
user_list=Wdtest.query.filter(Wdtest.id == 3).all() # 以恒等式形式匹配字段
# 查询名字结尾字符为g的所有⽤户
Wdtest.query.filter(Wdtest.name.endswith('g')).all()
# 查询名字包含‘wa'的所有项目
user_list=Wdtest.query.filter(Wdtest.name.contains('wa')).all()
# 模糊查询
user_list =Wdtest.query.filter(Wdtest.name.like('%a%')).all()
# 查询名字wa开头和age为20的所有⽤户[2种⽅式]
user_list=Wdtest.query.filter(Wdtest.name.startswith('wa'),Wdtest.age == 20).all()
user_list=Wdtest.query.filter(and_(Wdtest.name.startswith('wa'), Wdtest.age == 20)).all()
# 非条件查询查询名字不等于wade的所有⽤户[2种⽅式]
user_list=Wdtest.query.filter(not_(Wdtest.name == 'wade')).all()
user_list=Wdtest.query.filter(Wdtest.name != 'wade').all()
# in 条件查询
user_list=Wdtest.query.filter(Wdtest.id.in_(['97124f50-0208-11ea-a66c-04ea56212bdf', '3'])).all()
# 所有⽤户先按年龄从⼩到⼤, 再按id从⼤到⼩排序, 取前5个
user_list=Wdtest.query.order_by(Wdtest.age,Wdtest.id.desc()).limit(5).all()
# 分⻚查询, 每⻚3个, 查询第2⻚的数据
pn = Wdtest.query.paginate(2,3)
print(pn.pages)
print(pn.page)
print(pn.items)4 路由传参
有时我们需要将同一类 URL 映射到同一个视图函数处理,比如:使用同一个视图函数来显示不同用户的个人信息。
# 路由传递参数
@app.route('/user/<id>')
def user_info(id):
return '%s' % id路由传递的参数默认当做 string 处理
####指定请求方式
在 Flask 中,定义一个路由,默认的请求方式为:
- GET
- OPTIONS
- HEAD
在装饰器添加请求指定方式:
@app.route('/test', methods=['GET', 'POST'])
def test():
return "ok"5 动态正则匹配路由
flask实现正则匹配步骤:
- 导入转换器基类:在 Flask 中,所有的路由的匹配规则都是使用转换器对象进行记录
- 自定义转换器:自定义类继承于转换器基类
- 添加转换器到默认的转换器字典中
- 使用自定义转换器实现自定义匹配规则
实现:
导入转换器基类
from werkzeug.routing import BaseConverter
自定义转换器
# 自定义正则转换器
class RegexConverter(BaseConverter):
def __init__(self, url_map, *args):
super(RegexConverter, self).__init__(url_map)
# 将接受的第1个参数当作匹配规则进行保存
self.regex = args[0]添加转换器到默认的转换器字典中,并指定转换器使用时名字为: re
app = Flask(__name__) # 将自定义转换器添加到转换器字典中,并指定转换器使用时名字为: regex app.url_map.converters['regex'] = RegexConverter
使用转换器去实现自定义匹配规则
当前此处定义的规则是:3位数字
@app.route('/index/<regex("[0-9]{3}"):id>')
def user_info(id):
return "id 为 %s" % id自定义转换器其他函数实现
继承于自定义转换器之后,还可以实现 to_python 和 to_url 这两个函数去对匹配参数做进一步处理:
to_python:
- 该函数参数中的 value 值代表匹配到的值,可输出进行查看
- 匹配完成之后,对匹配到的参数作最后一步处理再返回,比如:转成 int 类型的值再返回:
class RegexConverter(BaseConverter):
def __init__(self, url_map, *args):
super(RegexConverter, self).__init__(url_map)
# 将接受的第1个参数当作匹配规则进行保存
self.regex = args[0]
def to_python(self, value):
return int(value)系统自带转换器
DEFAULT_CONVERTERS = {
'default': UnicodeConverter,
'string': UnicodeConverter,
'any': AnyConverter,
'path': PathConverter,
'int': IntegerConverter,
'float': FloatConverter,
'uuid': UUIDConverter,
}6 增加日志记录、redis配置加载、mq配置加载
6.1 日志记录
Settings._init:
# 配置日志 # LOG_LEVEL = "DEBUG" LOG_LEVEL = "INFO"
日志记录级别
FATAL/CRITICAL = 致命的,危险的 ERROR = 错误 WARNING = 警告 INFO = 信息 DEBUG = 调试 NOTSET = 没有设置
application._init:
1、日志模块基础配置,如:日志存放地址、日志记录格式、日志等级
#增加日志模块
def setup_log(Config):
#设置日志等级
logging.basicConfig(level=Config.LOG_LEVEL)
# 创建日志记录器,指明日志保存的路径、每个日志文件的最大大小、保存的日志文件个数上限
file_log_handler=RotatingFileHandler('log/log',maxBytes=1024 * 1024 * 300, backupCount=10)
# 创建日志记录的格式 日志等级 输入日志信息的文件名 行数 日志信息
formatter = logging.Formatter('%(asctime)s: %(levelname)s %(filename)s:%(lineno)d %(message)s')
# 为刚创建的日志记录器设置日志记录格式
file_log_handler.setFormatter(formatter)
# 为全局的日志工具对象(flaskapp使用的)添加日志记录器
logging.getLogger().addHandler(file_log_handler)2、日志启动
#日志启动 setup_log(Config)
6.2 redis配置及加载
之前我们在config中已经把redis的配置已经写进去了,所以这里可以直接创redis连接池供app全局使用
application._init:
#新增redis连接模块
def connectRedis(Config):
pool = redis.ConnectionPool(host=Config.REDIS_HOST, port=Config.REDIS_PORT, password=Config.REDIS_PASSWORD,
max_connections=Config.REDIS_POLL)
redis_store = redis.Redis(connection_pool=pool)
return redis_store使用示例:
@index_blu.route("/redis",methods=["POST","GET"])
def add_toRedis():
logging.info("come to here")
key = request.args.get("key")
application.redis_store.set(key , "1233")
value=application.redis_store.get( key )
print(value)
return "12333"6.3 rabbitmq基础配置及加载
# rabbitmq配置访问 # 添加用户名和密码 credentials = pika.PlainCredentials(Config.RABBITUSER, Config.RABBITPASSWORD) # 配置连接参数 parameters = pika.ConnectionParameters(host=Config.RABBITHOST, port=Config.RABBITPORT, credentials=credentials) connection = pika.BlockingConnection(parameters) channel = connection.channel()
使用示例:
@index_blu.route("/rabitmq",methods=["POST","GET"])
def add_rabitmq():
logging.info("come to rabiitmq")
application.channel.queue_declare(queue='queuetest2')
return "33333"7 全局拦截器配置
filerter.requestFilter
这里只是简单针对请求路径非index的进行拦截,如果还有其他拦截条件或者机制,可以继续在filter这个包下添加
from flask import request
import application
# 拦截器,每次的请求进来都会做的操作
@application.app.before_request
def before_action():
# 获取当前请求的路由(路径)
a = request.path
print(a)
u = a.split('/')
if len(a)>2:
if u[1] == 'index':
print('success')
else:
return "无权限请求"拦截器加载进app:
#拦截器加载 requestFilter.before_action
8 请求对象request和返回对象Response
请求对象request,使用前先导入request模块
from flask import request
- 获取url请求参数:request.args
- 获取form表单中的数据:request.form
- 获取请求体原始数据:request.data
- 获取文件数据:request.files
- 获取cookie:request.cookies
- 获取header信息:request.headers
- 获取请求方法:request.method
- 获取请求路径:request.path
Response
视图函数中可以返回的值
- 可以直接返回字符串,底层将这个字符串封装成了Response对象
- 元组,响应格式(响应体,状态码,头信息),不一定都要写,底层也是封装了一个Response对象
- 返回Response或其子类(jsonify子类返回标准json)
实现一个自定义Response对象步骤
- 继承Response对象
- 实现方法
force_typeforce_type(cls,rv,environ=None) - 指定
app.response为你定义的类 - 如果返回的值不是可以返回的对象,就会调用force_type方法
实现
class JSONResponse(Response):
@classmethod
def force_type(cls, response, environ=None):
'''
这个方法只有视图函数返回非字符、非元祖、非Response对象才会调用
:param response:是视图函数的返回值
:param environ:
:return:
'''
print(response)
print(type(response))
if isinstance(response,(list,dict)):
#jsonify除了将字典转换成json对象,还将对象包装成了一个Response对象
response = jsonify(response)
return super(JSONResponse,cls).force_type(response,environ)
app.response_class = JSONResponse9 异常捕获及自定义异常
捕获错误
errorhandler 装饰器
- 注册一个错误处理程序,当程序抛出指定错误状态码的时候,就会调用该装饰器所装饰的方法
参数:
- code_or_exception – HTTP的错误状态码或指定异常
例如统一处理状态码为500,404的错误给用户友好的提示:
@app.errorhandler(500)
def internal_server_error(e):
return '服务器搬家了哈哈哈'
@app.errorhandler(404)
def internal_server_error(e):
return '瞎请求什么路径呢'例如自定义错误413
@app.errorhandler(413)
def zero_division_error(e):
return '除数不能为0'异常捕获
abort 方法
- 抛出一个给定状态代码的 HTTPException 或者 指定响应,例如想要用一个页面未找到异常来终止请求,你可以调用 abort(404)。
参数:
code – HTTP的错误状态码
@index_blu.route("/exception",methods=["POST","GET"])
def exception():
logging.info("come to exception")
try:
print(2)
a=3/0
except:
abort(413)
return "ooooo"10 上下文
上下文:即语境,语意,在程序中可以理解为在代码执行到某个时刻,根据之前代码锁做的操作以及下文即将要执行的逻辑,可以决定在当前时刻下可以使用到的变量,或者可以做的事情。
Flask中有两种上下文:请求上下文(request context)和应用上下文(application context)。
Flask中上下文对象:相当于一个容器,保存了Flask程序运行过程中的一些信息。
1.application指的是当你调用app = flask(name)创建的这个对象app。 2.request指的是每次http请求发生时,WSGI server(比如gunicorn)调用Flask.call()之后,在Flask对象内部创建的Request对象; 3.application表示用于相应WSGI请求的应用本身,request表示没出http请求; 4.appliacation的生命周期大于request,一个application存活期间,可能发生多次http请求,所以,也就会有多个request;
请求上下文(request context):在Flask中,可以直接在视图函数中使用request这个独享进行获取先关数据,而request就是请求上下文的对象,保存了当前本次请求的相关数据,请求上线文对象有:request、session
request:封装了HTTP请求的内容,针对的是http请求。例如:user = request.args.get('user'),获取的是get请求的参数。
session:用来记录请求会话中的信息,针对的是用户信息。例如:session['name'] = user.id 科可以记录用户信息。还可以通过session.get('name')获取用户信息。
应用上下文(application context):它不是一直存在的,它只是request context中的一个对app的代理,所谓的local proxy。它的作用主要是帮助request获取当前的应用,它是伴request而生,随request而灭的。
应用上下文对象有:current_app,g
current_app:应用程序上下文,用于存储应用程序中的变量,可以通过current_app.name打印当前app的名称,也可以在current_app中存储一些变量,例如:
应用的启动脚本是哪个文件,启动时指定了哪些参数
加载了哪些配置文件,导入了哪些配置
连接了哪个数据库
有哪些可以调用的工具类、常量
当前flask应用在哪个机器上,哪个IP上运行,内存多大
current_app.name current_app.test_value='value'
g变量:g 作为 flask 程序全局的一个临时变量,充当者中间媒介的作用,我们可以通过它传递一些数据,g 保存的是当前请求的全局变量,不同的请求会有不同的全局变量,通过不同的thread id区别
g.name='abc'
注意:不同的请求,会有不同的全局变量
两者的区别:
请求上下文:保存了客户端和服务器交互的数据
应用上下文:flask 应用程序运行过程中,保存的一些配置信息,比如程序名、数据库连接、应用信息等
11 部署
gunicorn作为服务器,安装gunicorn
pip3 install gunicorn
启动
gunicorn -w 3 -b 127.0.0.1:8000 app:app
-w 处理进程数
-b 运⾏主机ip端⼝
dpj.wsgi 项⽬的wsgi
gunicorn常⽤配置
-c CONFIG : CONFIG,配置⽂件的路径,通过配置⽂件启动;⽣产环境使⽤; -b ADDRESS : ADDRESS,ip加端⼝,绑定运⾏的主机; -w INT, --workers INT:⽤于处理⼯作进程的数量,为正整数,默认为1; -k STRTING, --worker-class STRTING:要使⽤的⼯作模式,默认为sync异步,可以下载 eventlet和gevent并指定 --threads INT:处理请求的⼯作线程数,使⽤指定数量的线程运⾏每个worker。为正整数,默认为1。 --worker-connections INT:最⼤客户端并发数量,默认情况下这个值为1000。 --backlog int:未决连接的最⼤数量,即等待服务的客户的数量。默认2048个,⼀般不修改; -p FILE, --pid FILE:设置pid⽂件的⽂件名,如果不设置将不会创建pid⽂件 --access-logfile FILE : 要写⼊的访问⽇志⽬录--access-logformat STRING:要写⼊的访问⽇志格式 --error-logfile FILE, --log-file FILE : 要写⼊错误⽇志的⽂件⽬录。 --log-level LEVEL : 错误⽇志输出等级。 --limit-request-line INT : HTTP请求头的⾏数的最⼤⼤⼩,此参数⽤于限制HTTP请求⾏的允 许⼤⼩,默认情况下,这个值为4094。值是0~8190的数字。 --limit-request-fields INT : 限制HTTP请求中请求头字段的数量。此字段⽤于限制请求头字 段的数量以防⽌DDOS攻击,默认情况下,这个值为100,这个值不能超过32768 --limit-request-field-size INT : 限制HTTP请求中请求头的⼤⼩,默认情况下这个值为8190 字节。值是⼀个整数或者0,当该值为0时,表示将对请求头⼤⼩不做限制 -t INT, --timeout INT:超过这么多秒后⼯作将被杀掉,并重新启动。⼀般设定为30秒; --daemon: 是否以守护进程启动,默认false; --chdir: 在加载应⽤程序之前切换⽬录; --graceful-timeout INT:默认情况下,这个值为30,在超时(从接收到重启信号开始)之后仍然活着 的⼯作将被强⾏杀死;⼀般使⽤默认; --keep-alive INT:在keep-alive连接上等待请求的秒数,默认情况下值为2。⼀般设定在1~5秒之 间。 --reload:默认为False。此设置⽤于开发,每当应⽤程序发⽣更改时,都会导致⼯作重新启动。 --spew:打印服务器执⾏过的每⼀条语句,默认False。此选择为原⼦性的,即要么全部打印,要么全部 不打印; --check-config :显示现在的配置,默认值为False,即显示。 -e ENV, --env ENV: 设置环境变量;
到此这篇关于Flask项目搭建及部署(最全教程)的文章就介绍到这了,更多相关Flask项目搭建部署内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!