
发布一个基于TokyoTyrant的C#客户端开源项目
作者:
目前在网上关于TokyoCabinet(以下简称TC)和TokyoTyrant(以下简称TT)的资料已相对丰富了,但在.NET平台上的客户端软件却相对匮乏,因为做Discuz!NT企业版的关系,两个月前开始接触TC和TT,开始写相关的客户端代码。
这里开放的是客户端主要功能代码,开源的目的一方面是希望更多的人来学习研究TC和TT,同时大家可以下载本C#源码继续优化提升性能,同时查找BUG,必定本人精力能力有限,而Discuz!NT企业版的功能点又太多(抽空会多写文章进行介绍)实在有些力不从心了,呵呵:)
好了,为了便于使用,下面先对源码中的项目文件进行说明:
源码包中包括三个项目:
1.Discuz.EntLib.TokyoTyrant 核心功能代码(目前名空间暂以产品命名)
2.TTSample 主要用于加载测试数据,并对比SQLSERVER数据库的创建查询功能的速度。
3.TTSampleConsole 使用核心功能代码的例子(本文中会介绍其中主要功能)
其中Discuz.EntLib.TokyoTyrant中类图如下: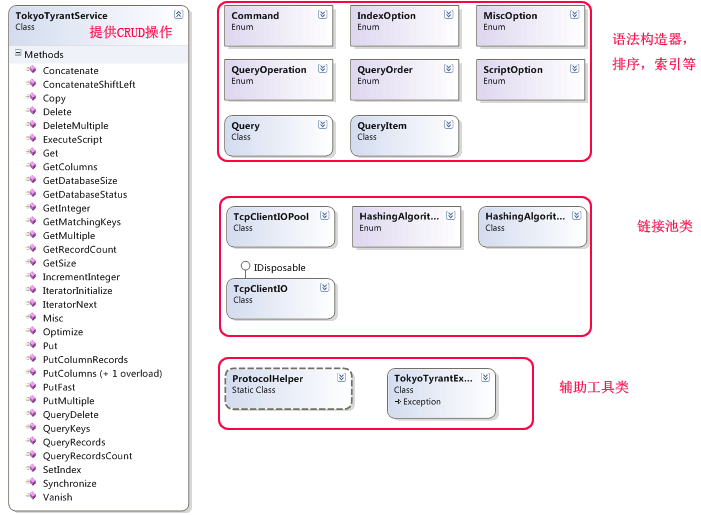
该客户端有如下特点:
支持TcpClient连接池
支持UTF-8编码
支持初始化链接数,链接过期时间,最大空闲时间,最长工作时间等设置
下面介绍一下如何使用:
1.初始化链接池:
复制代码 代码如下:
pool = TcpClientIOPool.GetInstance("dnt_online");//链接池名称(即DNT在线表)
pool.SetServers(new string[] { "10.0.4.66:11211"});
pool.InitConnections = 8;
pool.MinConnections = 8;
pool.MaxConnections = 8;
pool.MaxIdle = 30000;
pool.MaxBusy = 50000;
pool.MaintenanceSleep = 300000;
pool.TcpClientTimeout = 3000;
pool.TcpClientConnectTimeout = 30000;
pool.Initialize();
2.CRUD操作:
创建一条记录(以DISCUZ!NT在线表字段为例):
复制代码 代码如下:
IDictionary<string, string> columns = new System.Collections.Generic.Dictionary<string, string>();
columns.Add("olid", i.ToString());
columns.Add("userid", i.ToString());
columns.Add("ip", "10.0.7." + i);
columns.Add("username", "用户" + i);
columns.Add("nickname", "用户" + i);
columns.Add("password", "");
columns.Add("groupid", "5");
columns.Add("olimg", "");
columns.Add("adminid", "0");
columns.Add("invisible", "0");
columns.Add("action", "0");
columns.Add("lastactivity", "1");
columns.Add("lastposttime", DateTime.Now.ToString());
columns.Add("lastpostpmtime", DateTime.Now.ToString());
columns.Add("lastsearchtime", DateTime.Now.ToString());
columns.Add("lastupdatetime", DateTime.Now.ToString());
columns.Add("forumid", "0");
columns.Add("forumname", "");
columns.Add("titleid", "0");
columns.Add("title", "");
columns.Add("verifycode", "");
columns.Add("newpms", "0");
columns.Add("newnotices", "0");
TokyoTyrantService.PutColumns(TTPool.GetInstance(), i.ToString(), columns, true);//true表示如tc中有记录则覆盖,没有则创建该记录
查询操作:
首先构程过一个查询(条件)对象,比如查询字段olid = 1的在线用户信息,则该对象定义如下:
new Query().NumberEquals("olid", 1)
然后将其放入TokyoTyrantService的QueryRecords方法中(注意绑定链接池),如下:
var qrecords = TokyoTyrantService.QueryRecords(TTPool.GetInstance(), new Query().NumberEquals("olid", 1));
//遍历当前结果集
foreach (var k in qrecords.Keys)
{
var column = qrecords[k];
...数据绑定操作
}
更复杂的查询,如下(查询forumid = 16 and userid<1000 ,同时按userid字段倒序排列的前三条记录):
qrecords = TokyoTyrantService.QueryRecords(pool, new Query().NumberGreaterThanOrEqual("forumid", 16).
NumberLessThan("userid", 1000).OrderBy("userid", QueryOrder.NUMDESC).LimitTo(3, 0));
这里的比较运行符可以参见源码中的枚举类型,如下:
复制代码 代码如下:
public enum QueryOperation
{
STREQ = 0, // # 查询条件: 表示与操作对象的文字内容完全相同(=)
STRINC = 1, // # 查询条件: 表示含有操作对象文字的内容(LIKE ‘%文字%')
STRBW = 2, // # 查询条件: 表示以操作对象的文字行列开始(LIKE ‘文字%')
STREW = 3, // # 查询条件: 表示到操作对象的文字行列结束(LIKE ‘%文字')
STRAND = 4, // # 查询条件: 表示包含操作对象的文字行列中右逗号分开部分的字段的全部(name LIKE ‘%文字㈠%' AND name LIKE ‘%文字㈡%')
STROR = 5, // # 查询条件: 表示包含操作对象文字段中逗号分开部分的其中一部分(name LIKE ‘%文字㈠%' OR name LIKE ‘%文字㈡%')
STROREQ = 6, // # 查询条件: 表示与操作对象文字段中逗号分开部分的其中某部分完全相同( name = ‘文字㈠' OR name =‘文字㈡')
STRRX = 7, // # 查询条件: 表与与常规表达式匹配
NUMEQ = 8, // # 查询条件: 表示等于操作对象的数值(=)
NUMGT = 9, // # 查询条件: 表示比操作对象的数值要大(>)
NUMGE = 10, // # 查询条件: 表大于或等于操作对象的数值(>=)
NUMLT = 11, // # 查询条件: 表示比操作对象的数值要小(<)
NUMLE = 12, // # 查询条件: 表示小于或等于操作对象的数值(<=)
NUMBT = 13, // # 查询条件: 表示其大小处于操作对象文字段中被逗号分开的两个数值的中间(between 100 and 200)
NUMOREQ = 14, // # 查询条件: 表示其大小处于操作对象文字段中被逗号分开的两个数值的中间(between 100 and 200)
NEGATE = 1 << 24, // # 查询条件: 负标志negation flag
NOIDX = 1 << 25 // # 查询条件: 非索引标志
}
查询指定主键(如本例中的olid,效率最高)
复制代码 代码如下:
var qrecords = TokyoTyrantService.GetColumns(pool, new string[]{"1", "2", "3"});
foreach (string key in qrecords.Keys)
{
var column = qrecords[key];
}
更新操作:
因为TC的TCT结构没有提供直接更新记录中某一字段的功能,所以只能全部取出相关记录的所有字段,然后再更新全部字段(这种做法的效率不高,但在MONGODB中是可以更新部分字段)。所以要组合使用查询和创建操作中的语法,即选查出相应记录,然后再使用PutColumns方法更新该记录,形式如下:
复制代码 代码如下:
var qrecords = TokyoTyrantService.QueryRecords(TTPool.GetInstance(), new Query().NumberEquals("olid", 1));
foreach (var k in qrecords.Keys)
{
var column = qrecords[k];
...数据绑定操作
TokyoTyrantService.PutColumns(TTPool.GetInstance(), column["olid"], columns, true);//column["olid"]为主键,类似数据库里的主键,以其为查询条件,速度最快
}
删除操作
该操作有两种执行方法,一种是选查询出符合条件的记录,然后再删除(依次删除),一种是直接给定要删除的主键直接删除(效率比前者高)。第一种(可以针对不用字段进行查询,并将相应结果的主键做了删除依据)
复制代码 代码如下:
var qrecords = TokyoTyrantService.QueryRecords(TTPool.GetInstance(), new Query().NumberEquals("userid", 1));
foreach (var k in qrecords.Keys)
{
var column = qrecords[k];
...数据绑定操作
TokyoTyrantService.Delete(TTPool.GetInstance(), column["olid"]);//column["olid"]为主键,类似数据库里的主键
}
第二种(删除olid为1或2或3或4的键值记录,只能删除以主键为条件的记录):
TokyoTyrantService.DeleteMultiple(pool, new string[] { "1", "2", "3", "4" });
创建索引
TC中支持几种类型的字段索引如下(经常用的是数值型和字符型):
复制代码 代码如下:
/// <summary>
/// 索引类型
/// </summary>
public enum IndexOption : int
{
LEXICAL = 0, // # 文本型索引
DECIMAL = 1, // # 数值型索引
TOKEN = 2, // # 标记倒排索引.
QGRAM = 3, // #QGram倒排索引.
OPT = 9998, // # 9998, 对索引优化
VOID = 9999, // # 9999, 移除索引.
KEEP = 1 << 24 // # 16777216, 保持已有索引.
}
比如在线表中经常用的字段索引设置如下:
复制代码 代码如下:
TokyoTyrantService.SetIndex(pool, "olid", IndexOption.DECIMAL);
TokyoTyrantService.SetIndex(pool, "userid", IndexOption.DECIMAL);
TokyoTyrantService.SetIndex(pool, "password", IndexOption.LEXICAL);
TokyoTyrantService.SetIndex(pool, "ip", IndexOption.LEXICAL);
TokyoTyrantService.SetIndex(pool, "forumid", IndexOption.DECIMAL);
TokyoTyrantService.SetIndex(pool, "lastupdatetime", IndexOption.DECIMAL);
3.其它常用操作
复制代码 代码如下:
LimitTo(int max, int skip):类似于MYSQL中的LIMIT方法,其中max如同mssql中的TOP,而skip则表示跳过多少条记录(类似LINQ中的那个Skip方法)
Vanish(TcpClientIOPool pool);清空所有记录
QueryRecordsCount(TcpClientIOPool pool, Query query)//查询指定条件的记录数
GetRecordCount(TcpClientIOPool pool)//返回当前表中的记录总数
GetDatabaseSize(TcpClientIOPool pool);//获取数据库(表)信息
IteratorNext(TcpClientIOPool pool)//一个迭代器,用于遍历所有记录
4.因为其兼容Memcached,所以提供方法支持(键/值对)
复制代码 代码如下:
Put(TcpClientIOPool pool, string key, string value, bool overwrite)//该操作方法将不像Put那样获取服务器端返回的信息
PutFast(TcpClientIOPool pool, string key, string value)//快速存储键值对(不再获取服务端返回信息). 如键值已存在则将被覆盖
PutMultiple(TcpClientIOPool pool, IDictionary<string, string> items) //一次添加多值
Delete(TcpClientIOPool pool, string key)//删除指定键的记录
DeleteMultiple(TcpClientIOPool pool, string[] keys)//删除指定键组的记录
Get(TcpClientIOPool pool, string key)//获取指定键的记录(单条)
GetSize(TcpClientIOPool pool, string key)//获取指定键的大小
GetColumns(TcpClientIOPool pool, string[] keys)//获取指定键组的记录(多条)
5.排序
public enum QueryOrder
{
STRASC = 0, // # 排序类型: 表示按照文本型字段内的文本内容在字典中排列顺序的升序
STRDESC = 1, // # 排序类型: 表示按照文本型字段内的文本内容在字典中排列顺序的降序
NUMASC = 2, // # 排序类型: 表示按照数值大小的升序
NUMDESC = 3 // # 排序类型: 表示按照数值大小的降序
}
用法(如降序并取前16条记录):
qrecords = TokyoTyrantService.QueryRecords(pool, new Query().OrderBy("userid", QueryOrder.NUMDESC).LimitTo(16, 0));
注意:尽量避免对大数据集(如100w条记录)进行排序,那样耗时会很严重。所以尽量在OrderBy之前指定查询条件,从而缩减查询结果集的尺寸。
其它说明:
TT的启动参数(这里以TCT类型为例):
注:网上有一些关于TC+TT与MONGODB,Redis的速度测试,所以这里我想有必要对TT的启动参数做一下介绍,因为这会关系到最终的测试结果。
因为两者都使用了MMAP模式,而TC+TT要使用MMAP,就要使用下面参数:
xmsiz:指定了TCHDB的扩展MMAP内存大小,默认值为 67108864,也就是64M,如果数据库文件超过64M,则只有前部分会映射在内存中,所以写入性能会下降。
bnum: 指定了bucket array的数量。推荐设置bnum为预计存储总记录数的0.5~4倍,使key的哈希分布更均匀,减少在 bucket内二分查找的时间复杂度。
比如有100w条记录,这里可以使用下面命令行启动ttserver:
ttserver -host 10.0.4.66 -port 11211 -thnum 1024 -dmn -pid /ttserver/ttserver.pid -log /ttserver/ttserver.log -le -ulog /ttserver/ -ulim 256m -sid 1 -rts /ttserver/ttserver.rts /ttserver/database.tct#bnum=1000000#rcnum=1000000#xmsiz=1073741824 (注:1073741824=1G)
当然TTServer中针对不同的数据库(TC中支持6种),都有相应的参数进行启动配置(有重复),这会导致的查询和插入数据的结果上有很大的差异,更多的内容可以参见这个链接。
下面我将自己对TC+TT(仅使用TCT文件类型,其它5种类型都比这个类型快许多)与MONGODB的测试结果做一下说明:
机器是一个普遍台式机:1.5g内存+1.5gCPU,64位的centos机器,150g硬盘。
mongodb (centos 64bit) :
插入1000000 条记录,耗时:250377毫秒
对1000000条记录,查询10000 次记录,耗时:8100毫秒 (偶尔出现7500毫秒) (查询"_id"主键速度在6995毫秒上下)
对1000000条记录,查询100000 次记录,耗时:77101毫秒
ttcache(centos 64bit,使用上面的启动参数):
创建 1000000 条数据,耗时 589472毫秒
对1000000条记录,查询 10000 次数据,耗时 4843毫秒
对1000000条记录,查询 100000 次数据,耗时 47903毫秒
注:查询条件动态变化,以模拟实际生产环境。
比较发现MONGODB插入速度要比TTCACHE快至少一倍(MONGODB在WINDOWS下也是如此),但10000次查询速度会慢大约40%-50%。这里的查询和插入操作都是每做一次操作就Connect一次服务器,操作结束时则将当前链接放到链接池中,而不是开启一个长链接来做批量操作。其中TTSERVER所使用的客户端分别是本文的这个工具, MONGODB则使用的是MongoDB.Driver。
下面是MSSQL数据库操作结果:
批量创建 1000000 条数据,耗时 9020196毫秒
批量查询 10000 条数据,耗时 106040毫秒
批量查询 100000 条数据,耗时 773867毫秒
我想进行这类测试,还是不要使用什么WINDOWS(尽量MONGODB在WINDOW下插入数据的速度已很快)或其它操作系统。而应该使用LINUX(尽量是64位)。当然内存要尽量的大,因为尽管TC+TT已很省内存(必定符合日本的国情,资源少还要多办事),但如果要提升查询和插入速度,还是建议4g以上的内存做测
试。而MONGODB本来对内存要求很高(包括CPU)。
因为mongodb的插入速度非常快,且在数据库大量可以新建文件来存储新的数据(不像TCT使用一个数据文件),所以在更大级别的数据量插入上依然性能稳定。看来将它视为海量数据存储的分布解决方案还是很有可行性的。当然我目前正在考虑一个架构,就是将MongoDb和TC/TT组合起来,实现读写分离(即将TC作为读数据库slavedb,并发性和查询速度快),而将MongoDb作为写数据库masterdb(更新和插入速度快)。将分布式的MongoDb数据文件与前端TC中的文件依次对应(使用C#代码实现两者之间的数据同步和逻辑调用),这样融合两者各自的优势的结果。当然目前这只是想法,且离文本的内容越来越远了,呵呵。
好了,今天的内容就选到这里了。
下载链接:http://tokyotyrantclient.codeplex.com/