
java根据模板导出PDF的详细实现过程
作者:pengyufight
题记:
由于业务的需要,需要根据模板定制pdf文档,经测试根据模板导出word成功了;但是导出pdf相对麻烦了一点。两天的研究测试java导出PDF,终于成功了,期间走了不少弯路,今分享出来,欢迎大家有问题在此交流,与君共勉!
一、需求
根据业务需要,需要在服务器端生成可动态配置的PDF文档,方便数据可视化查看。
此文的测试是在客户端通过java程序的测试,直接运行java类获得成功!
二、解决方案
iText+FreeMarker+JFreeChart生成可动态配置的PDF文档。
iText有很强大的PDF处理能力,但是样式和排版不好控制,直接写PDF文档,数据的动态渲染很麻烦。
FreeMarker能配置动态的html模板,正好解决了样式、动态渲染和排版问题。
JFreeChart有这方便的画图API,能画出简单的折线、柱状和饼图,基本能满足需要。
三、实现功能
1、能动态配置PDF文档内容
2、能动态配置中文字体显示
3、设置自定义的页眉页脚信息
4、能动态生成业务图片
5、完成PDF的分页和图片的嵌入
四、主要代码结构说明:
1、component包:PDF生成的组件 对外提供的是PDFKit工具类和HeaderFooterBuilder接口,其中PDFKit负责PDF的生成,HeaderFooterBuilder负责自定义页眉页脚信息。
2、builder包:负责PDF模板之外的额外信息填写,这里主要是页眉页脚的定制。
3、chart包:JFreeChart的画图工具包,目前只有一个线形图。
4、test包:测试工具类
5、util包:FreeMarker等工具类。

项目采用maven架构,开发工具为MyEclipse10,环境为jdk1.7
五、关键代码说明
1、模板配置
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8"/>
<meta http-equiv="Content-Style-Type" content="text/css"/>
<title></title>
<style type="text/css">
body {
font-family: pingfang sc light;
}
.center{
text-align: center;
width: 100%;
}
</style>
</head>
<body>
<!--第一页开始-->
<div class="page" >
<div class="center"><p>${templateName}</p></div>
<div><p>iText官网:${ITEXTUrl}</p></div>
<div><p>FreeMarker官网:${freeMarkerUrl}</p></div>
<div><p>JFreeChart教程:${JFreeChartUrl}</p></div>
<!--外部链接-->
<p>静态logo图</p>
<div>
<img src="${imageUrl}" alt="美团点评" width="512" height="359"/>
</div>
<!--动态生成的图片-->
<p>气温变化对比图</p>
<div>
<img src="${picUrl}" alt="我的图片" width="500" height="270"/>
</div>
</div>
<!--第一页结束-->
<!---分页标记-->
<span style="page-break-after:always;"></span>
<!--第二页开始-->
<div class="page">
<div>第二页开始了</div>
<div>列表值:</div>
<div>
<#list scores as item>
<div><p>${item}</p></div>
</#list>
</div>
</div>
<!--第二页结束-->
</body>
</html>2、获取模板内容并填充数据
public static String getContent(String fileName,Object data){
String templatePath=getPDFTemplatePath(fileName).replace("\\", "/");
String templateFileName=getTemplateName(templatePath).replace("\\", "/");
String templateFilePath=getTemplatePath(templatePath).replace("\\", "/");
System.out.println("templatePath:"+templatePath);
System.out.println("templateFileName:"+templateFileName);
System.out.println("templateFilePath:"+templateFilePath);
if(StringUtils.isEmpty(templatePath)){
throw new FreeMarkerException("templatePath can not be empty!");
}
try{System.out.println("进到这里了,有来无回1");
Configuration config = new Configuration(Configuration.VERSION_2_3_25);
config.setDefaultEncoding("UTF-8");
config.setDirectoryForTemplateLoading(new File(templateFilePath));
config.setTemplateExceptionHandler(TemplateExceptionHandler.RETHROW_HANDLER);
config.setLogTemplateExceptions(false);System.out.println("进到这里了,有来无回2");
Template template = config.getTemplate(templateFileName);System.out.println("进到这里了,有来无回3");
StringWriter writer = new StringWriter();
template.process(data, writer);
writer.flush();
String html = writer.toString();
return html;
}catch (Exception ex){
throw new FreeMarkerException("FreeMarkerUtil process fail",ex);
}
}public static String getContent(String fileName,Object data){
String templatePath=getPDFTemplatePath(fileName);//根据PDF名称查找对应的模板名称
String templateFileName=getTemplateName(templatePath);
String templateFilePath=getTemplatePath(templatePath);
if(StringUtils.isEmpty(templatePath)){
throw new FreeMarkerException("templatePath can not be empty!");
}
try{
Configuration config = new Configuration(Configuration.VERSION_2_3_25);//FreeMarker配置
config.setDefaultEncoding("UTF-8");
config.setDirectoryForTemplateLoading(new File(templateFilePath));//注意这里是模板所在文件夹,不是文件
config.setTemplateExceptionHandler(TemplateExceptionHandler.RETHROW_HANDLER);
config.setLogTemplateExceptions(false);
Template template = config.getTemplate(templateFileName);//根据模板名称 获取对应模板
StringWriter writer = new StringWriter();
template.process(data, writer);//模板和数据的匹配
writer.flush();
String html = writer.toString();
return html;
}catch (Exception ex){
throw new FreeMarkerException("FreeMarkerUtil process fail",ex);
}
}3、导出模板到PDF文件
/**
* @description 导出pdf到文件
* @param fileName 输出PDF文件名
* @param data 模板所需要的数据
*
*/
public String exportToFile(String fileName,Object data){
try {
String htmlData= FreeMarkerUtil.getContent(fileName, data);
if(StringUtils.isEmpty(saveFilePath)){
saveFilePath=getDefaultSavePath(fileName);
}
File file=new File(saveFilePath);
if(!file.getParentFile().exists()){
file.getParentFile().mkdirs();
}
FileOutputStream outputStream=null;
try{
//设置输出路径
outputStream=new FileOutputStream(saveFilePath);
//设置文档大小
Document document = new Document(PageSize.A4);
PdfWriter writer = PdfWriter.getInstance(document, outputStream);
//设置页眉页脚
PDFBuilder builder = new PDFBuilder(headerFooterBuilder,data);
builder.setPresentFontSize(10);
writer.setPageEvent(builder);
//输出为PDF文件
convertToPDF(writer,document,htmlData);
}catch(Exception ex){
throw new PDFException("PDF export to File fail",ex);
}finally{
IOUtils.closeQuietly(outputStream);
}
} catch (Exception e) {
e.printStackTrace();
}
return saveFilePath;
}4、测试工具类
public String createPDF(Object data, String fileName){
//pdf保存路径
try {
//设置自定义PDF页眉页脚工具类
PDFHeaderFooter headerFooter=new PDFHeaderFooter();
PDFKit kit=new PDFKit();
kit.setHeaderFooterBuilder(headerFooter);
//设置输出路径
kit.setSaveFilePath("D:/Users/hello.pdf");
String saveFilePath=kit.exportToFile(fileName,data);
return saveFilePath;
} catch (Exception e) {
System.out.println("竟然失败了,艹!");
e.printStackTrace();
// log.error("PDF生成失败{}", ExceptionUtils.getFullStackTrace(e));
log.error("PDF生成失败{}");
return null;
}
}
public static void main(String[] args) {
ReportKit360 kit=new ReportKit360();
TemplateBO templateBO=new TemplateBO();
templateBO.setTemplateName("Hello iText! Hello freemarker! Hello jFreeChart!");
templateBO.setFreeMarkerUrl("http://www.zheng-hang.com/chm/freemarker2_3_24/ref_directive_if.html");
templateBO.setITEXTUrl("http://developers.itextpdf.com/examples-itext5");
templateBO.setJFreeChartUrl("http://www.yiibai.com/jfreechart/jfreechart_referenced_apis.html");
templateBO.setImageUrl("E:/图片2/004d.jpg");
List<String> scores=new ArrayList<String>();
scores.add("94");
scores.add("95");
scores.add("98");
templateBO.setScores(scores);
List<Line> lineList=getTemperatureLineList();
DefaultLineChart lineChart=new DefaultLineChart();
lineChart.setHeight(500);
lineChart.setWidth(300);
String picUrl=lineChart.draw(lineList,0);
templateBO.setPicUrl(picUrl);System.out.println("picUrl:"+picUrl);
String path= kit.createPDF(templateBO,"hello.pdf");
System.out.println("打印:"+path);
}此测试工具类中,要注意几点:
1)templateBO.setImageUrl("E:/图片2/004d.jpg");中的参数修改为自己本地有的图片;
2)程序可能会报找不到模板引擎hello.ftl文件的错误,一定要将源码中的hello.ftl放在本地硬盘对应的目录中;
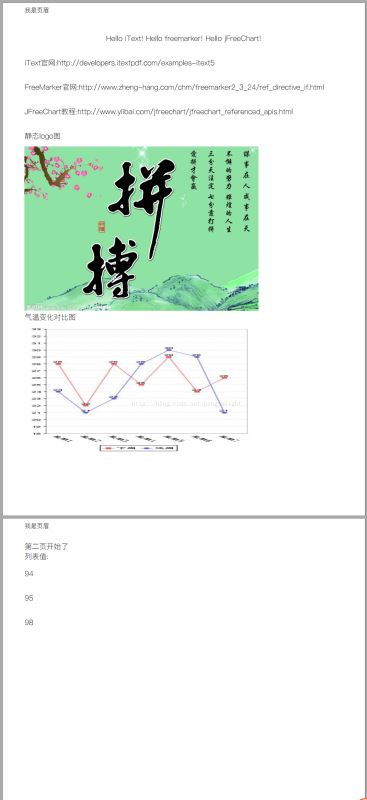
六、生成效果图
七、遇到的坑
1、FreeMarker配置模板文件样式,在实际PDF生成过程中,可能会出现一些不一致的情形,目前解决方法,就是换种方式调整样式。
2、字体文件放在resource下,在打包时会报错,运行mvn -X compile 会看到详细错误:
这是字体文件是二进制的,而maven项目中配置了资源文件的过滤,不能识别二进制文件导致的,plugins中增加下面这个配置就好了:
<build>
<resources>
<resource>
<directory>src/main/resources</directory>
<filtering>true</filtering>
</resource>
</resources>
<!--增加的配置,过滤ttf文件的匹配-->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>2.7</version>
<configuration>
<encoding>UTF-8</encoding>
<nonFilteredFileExtensions>
<nonFilteredFileExtension>ttf</nonFilteredFileExtension>
</nonFilteredFileExtensions>
</configuration>
</plugin>
</plugins>
</build>3、PDF分页配置:
在ftl文件中,增加分页标签: <span style="page-break-after:always;"></span>
八、项目说明
此项目最初是由github上的开源项目经二次开发而成,附github源码地址:https://github.com/superad/pdf-kit;
但是github上的源码bug太多,几乎不能运行,经过一天的测试修改,才完全消除了它的bug;经过测试已经在windows系统,jdk1.7,MyEclipse10中运行成功;此项目只需要在MyEclipse中右击ReportKit360.java文件,然后选择run as java application即可,如图:

下面是整合到web网站中,在网页中填充内容,然后自动生成pdf文档后在网页端查看或者下载。
九、整合到web项目中遇到的坑
1、读取的模板.ftl文档时,

发现读取的内容htmlData开始多了一个?,几经搜索后发现是因为文档编码格式的原因,于是在editplus中将其打开并重新另存为无bom格式的文档后重新读取,发现?消失了。
虽然解决了读取的问题,但是还是没有解决下载pdf乱码的问题。
2、又重新debug项目之后发现,不是字体读取的问题,因为文件夹下的字体是能够读取到的,于是怀疑是编码问题,将所有编码修改为UTF-8格式,仍没有解决乱码问题,又继续debug项目,几经细致查看后,感觉应该是文件读取时是在web容器中的,这一步编码不太容易修改,于是决定按照读取是什么编码就改为什么编码,最终获得成功。
web项目代码结构如下:

启动服务器后,在浏览器中输入http://localhost:8080/项目名/index.action后回车,即可进入前端输入pdf文档内容的页面,输入完成后点击提交,即可下载pdf文档,生成的文档格式完全正确,并且没有乱码。
参考文章:https://www.jb51.net/article/112366.htm
总结
到此这篇关于java根据模板导出PDF的文章就介绍到这了,更多相关java根据模板导出PDF内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!