
删除Table表中的重复行的方法
作者:
在写SQL的时候经常会有这样的需求: 在一个Table中会有多条重复的数据,如何有效的取出来不重复的数据,或者是删除掉重复的数据,或者取出某列重复值的第一条数据.
利用SQL Server 2005的新功能NOW_NUMBER和CTE可以很好的实现.
举例说明如下:
建立测试数据:
create table Dup1
(
Col1 int null,
Col2 varchar(20) null
)
insert into Dup1 values
(1, 'aaa'),
(2, 'aaa'),
(2, 'aaa'),
(2, 'aaa'),
(3, 'bbb'),
(3, 'bbb'),
(4, 'ccc'),
(4, 'ddd'),
(5, 'eee')
select * from Dup1
可以查看到重复的数据有:
SELECT Col1, Col2, COUNT(*) AS DupCountFROM Dup1GROUP BY Col1, Col2HAVING COUNT(*) > 1
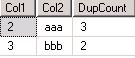
接下来介绍如何delete掉重复的数据:
1.NOW_NUMBER:SQL Server 2005添加了很好用的RANKING函数(NOW_NUMBER,RANK,DENSE_RANK,NTILE),利用NOW_NUMBER()OVER(PARTITION GY)最为直接,也最为方便,不能修改表或者产生多余的列.
首先会分配一个列号码,以Col1,Col2组合来分区排序.
SELECT Col1, Col2,ROW_NUMBER() OVER (PARTITION BY Col1, Col2 ORDER BY Col1) AS rnFROM Dup1
得到的序号如下:
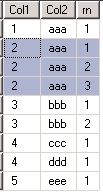
很明显的是重复列都分组分割排序,只需要delete掉排序序号>1的即可.
--用到CTE
WITH DupsD
AS (
SELECT Col1, Col2,
ROW_NUMBER() OVER (PARTITION BY Col1, Col2 ORDER BY Col1) AS rn
FROM Dup1
)
DELETE DupsD
WHERE rn > 1;
--或者
DELETE A FROM (
SELECT Col1, Col2,
ROW_NUMBER() OVER (PARTITION BY Col1, Col2 ORDER BY Col1) AS rn
FROM Dup1) A WHERE A.rn>1
2.创建一个标识键唯一的表记一列.
ALTER TABLE dbo.Dup1
ADD
PK INT IDENTITY
NOT NULL
CONSTRAINT PK_Dup1 PRIMARY KEY;
SELECT *
FROM Dup1;
删除找出与Col1,Col2相同并且比Dup1.PK大的记录,也就是保留重复值中PK最小的记录.
DELETE Dup1
WHERE EXISTS ( SELECT *
FROM Dup1 AS D1
WHERE D1.Col1 = Dup1.Col1
AND D1.Col2 = Dup1.Col2
AND D1.PK > Dup1.PK );
3.select distant into,这种方法借助一个新的table,把不重复的结果集转移到新table中.
SELECT distinct Col1, Col2 INTO NoDupsFROM Dup1;select * from NoDups
建议采用第一种和第三种方法,第一种多见于T-SQL的编程中,第三种在ETL中常常使用.
举例说明如下:
建立测试数据:
复制代码 代码如下:
create table Dup1
(
Col1 int null,
Col2 varchar(20) null
)
insert into Dup1 values
(1, 'aaa'),
(2, 'aaa'),
(2, 'aaa'),
(2, 'aaa'),
(3, 'bbb'),
(3, 'bbb'),
(4, 'ccc'),
(4, 'ddd'),
(5, 'eee')
select * from Dup1
可以查看到重复的数据有:
复制代码 代码如下:
SELECT Col1, Col2, COUNT(*) AS DupCountFROM Dup1GROUP BY Col1, Col2HAVING COUNT(*) > 1
接下来介绍如何delete掉重复的数据:
1.NOW_NUMBER:SQL Server 2005添加了很好用的RANKING函数(NOW_NUMBER,RANK,DENSE_RANK,NTILE),利用NOW_NUMBER()OVER(PARTITION GY)最为直接,也最为方便,不能修改表或者产生多余的列.
首先会分配一个列号码,以Col1,Col2组合来分区排序.
复制代码 代码如下:
SELECT Col1, Col2,ROW_NUMBER() OVER (PARTITION BY Col1, Col2 ORDER BY Col1) AS rnFROM Dup1
得到的序号如下:
很明显的是重复列都分组分割排序,只需要delete掉排序序号>1的即可.
复制代码 代码如下:
--用到CTE
WITH DupsD
AS (
SELECT Col1, Col2,
ROW_NUMBER() OVER (PARTITION BY Col1, Col2 ORDER BY Col1) AS rn
FROM Dup1
)
DELETE DupsD
WHERE rn > 1;
--或者
DELETE A FROM (
SELECT Col1, Col2,
ROW_NUMBER() OVER (PARTITION BY Col1, Col2 ORDER BY Col1) AS rn
FROM Dup1) A WHERE A.rn>1
2.创建一个标识键唯一的表记一列.
复制代码 代码如下:
ALTER TABLE dbo.Dup1
ADD
PK INT IDENTITY
NOT NULL
CONSTRAINT PK_Dup1 PRIMARY KEY;
SELECT *
FROM Dup1;
删除找出与Col1,Col2相同并且比Dup1.PK大的记录,也就是保留重复值中PK最小的记录.
复制代码 代码如下:
DELETE Dup1
WHERE EXISTS ( SELECT *
FROM Dup1 AS D1
WHERE D1.Col1 = Dup1.Col1
AND D1.Col2 = Dup1.Col2
AND D1.PK > Dup1.PK );
3.select distant into,这种方法借助一个新的table,把不重复的结果集转移到新table中.
复制代码 代码如下:
SELECT distinct Col1, Col2 INTO NoDupsFROM Dup1;select * from NoDups
建议采用第一种和第三种方法,第一种多见于T-SQL的编程中,第三种在ETL中常常使用.